本記事は、Study-AI社様のJDLA認定プログラムの提出レポートを兼ねた記事となっております。
講義要約
Sec1: 再帰型ニューラルネットワークについて
1-1 RNN (Recurrent Neural Network)
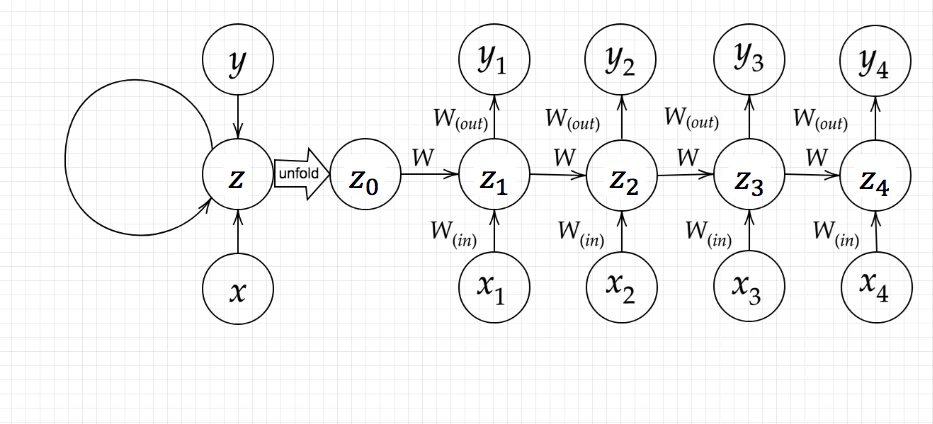
- RNNとは
- 時系列データに対応可能なニューラルネットワーク
- 時系列データ
- 時間的順序を追って一定間隔ごとに観察され、しかも相互に統計的依存関係が認められるようなデータの系列(音声データ、テキストデータなど)
- RNNについて
- 入力に重みをかけ、前の隠れ層$z^{t-1}$に重みをかけたものを加算しバイアスb加算した値を$u_t$とする。
$$ u^t = W_{(in)}x^t + Wz^{t-1} + b $$
u[:, t+1] = np.dot(X, W_in) + np.dot(z[:, t].reshape(1, -1), W)
- $u_t$は活性化関数にかませられ、$z_t$となる。
$$ z^t = f(W_{(in)}x^t + Wz^{t-1} + b $$
z[:, t+1] = functions.sigmoid(u[:, t+1])
- $z_t$を重みと掛け合わせ、新たなバイアスcを加算した値を$v_t$とする。
$$ v^t = W_{(out)}z^t + c $$
np.dot(z[:, t+1].reshape(1, -1), W_out)
- $v_t$は活性化関数にかませられ、$y_t$となる。
$$y^t = g(W_{(out)}z^t + c) $$
y[:, t] = functions.sigmoid(np.dot(z[:, t+1].reshape(1, -1), W_out))
- RNNの特徴:時系列データを扱うには、初期の状態と過去の時間t-1の状態を保持し、そこから次の時間でのtを再帰的に求める再帰構造が必要になる。
1-2 BPTT (Backpropagation Through Time)
-
BPTTとは
- RNNにおけるパラメータ調整方法の一種で、誤差逆伝播法の一種
-
BPTTの数学的記述1
- 誤差EをパラメータWで微分した値。
$$
\frac{\partial E}{\partial W_{(in)}} = \frac{\partial E}{\partial u^t}
\Biggl[ \frac{\partial u^t}{\partial W_{(in)}} \Biggr]^T = \delta^t [x^t]^T
$$
- 誤差EをパラメータWで微分した値。
np.dot(X.T, delta[:, t].reshape(1, -1))
$$
\frac{\partial E}{\partial W_{(out)}} = \frac{\partial E}{\partial v^t}
\Biggl[ \frac{\partial v^t}{\partial W_{(out)}} \Biggr]^T = \delta^{out, t} [z^t]^T
$$
np.dot(z[;, t+1].reshape(-1, 1), delta_out[:, t].reshape(-1, 1))
$$
\frac{\partial E}{\partial W} = \frac{\partial E}{\partial u^t}
\Biggl[ \frac{\partial u^t}{\partial W} \Biggr]^T = \delta^t [z^{t-1}]^T
$$
np.dot(z[;, t].reshape(-1, 1), delta[:, t].reshape(1, -1))
$$
\frac{\partial E}{\partial b} = \frac{\partial E}{\partial u^t}
\frac{\partial u^t}{\partial b} = \delta^t\
\frac{\partial E}{\partial c} = \frac{\partial E}{\partial v^t}
\frac{\partial v^t}{\partial c} = \delta^{out, t}
$$
- BPTTの数学的記述2
- $W_{(in)}, W$で使うuについて
$$ u^t = W_{(in)}x^t + Wz^{t-1} + b $$
u[:, t+1] = np.dot(X, W_in) + np.dot(z[:, t].reshape(1, -1), W)
$$ z^t = f(W_{(in)}x^t + Wz^{t-1} + b $$
z[:, t+1] = functions.sigmoid(u[:, t+1])
$$ v^t = W_{(out)}z^t + c $$
np.dot(z[:, t+1].reshape(1, -1), W_out)
$$y^t = g(W_{(out)}z^t + c) $$
y[:, t] = functions.sigmoid(np.dot(z[:, t+1].reshape(1, -1), W_out))
- BPTTの数学的記述3
$$
\frac{\partial E}{\partial u^t} = \frac{\partial E}{\partial v^t}
\frac{\partial v^t}{\partial u^t} = \frac{\partial E}{\partial v^t}
\frac{\partial { W_{(out)}f(u^t) + c}}{\partial u^t} = f'(u^t)W_{(out)}^T\delta^{out, t} = \delta^t
$$
delta[:, t] = (np.dot(delta[:, t+1].T, W.T) + np.dot(delta_out[:, t].T, W_out.T)) * functions.d_sigmoid(u[:, t+1])
$$
\delta^{t-1} = \frac{\partial E}{\partial u^{t-1}} = \frac{\partial E}{\partial u^t}
\frac{\partial u^t}{\partial z^{t-1}} = \delta^t \Biggl\{ \frac{\partial u^t}{\partial z^{t-1}} \frac{\partial z^{t-1}}{\partial u^{t-1}} \Biggr\} = \delta^t { Wf'(u^{t-1}) }
$$
$$
\delta^{t-z-1}= \delta^{t-z} { Wf'(u^{t-z-1}) }
$$
- BPTTの数学的記述4
- パラメータ更新式
$$
W_{(in)}^{t+1} = W_{(in)}^t - \epsilon \frac{\partial E}{\partial W_{(in)}} = W_{(in)}^t - \epsilon \sum_{z=0}^{T_t} \delta^{t-z}[x^{t-z}]^T
$$
- パラメータ更新式
W_in -= learning_rate * W_in_grad
$$
W_{(out)}^{t+1} = W_{(out)}^t - \epsilon \frac{\partial E}{\partial W_{(out)}} = W_{(out)}^t - \epsilon \delta^{out, t}[z^t]^T
$$
W_out -= learning_rate * W_out_grad
$$
W^{t+1} = W^t - \epsilon \frac{\partial E}{\partial W} = W_{(in)}^t - \epsilon \sum_{z=0}^{T_t} \delta^{t-z}[z^{t-z-1}]^T
$$
W -= learning_rate * W_grad
$$
b^{t+1} = b^t - \epsilon \frac{\partial E}{\partial b} = b^t - \epsilon \sum_{z=0}^{T_t} \delta^{t-z}
$$
$$
c^{t+1} = c^t - \epsilon \frac{\partial E}{\partial c} = c^t - \epsilon \delta^{out, t}
$$
- BPTTの全体像
$$
\begin{align}
E^t &= loss(y^t, d^t)\
&= loss(g(W_{(out)}z^t + c), d^t) \
&= loss(g(W_{(out)} f(W_{(in)}x^t + Wz^{t-1} + b) + c), d^t)
\end{align}
$$
$$
W_{(in)}x^t + Wz^{t-1} + b\
W_{(in)}x^t + W f(u^{t-1}) + b\
W_{(in)}x^t + W f(W_{(in)}x^{t-1} + Wz^{t-2} + b) + b
$$
Sec2: LSTM (Long Short Term Memory network)
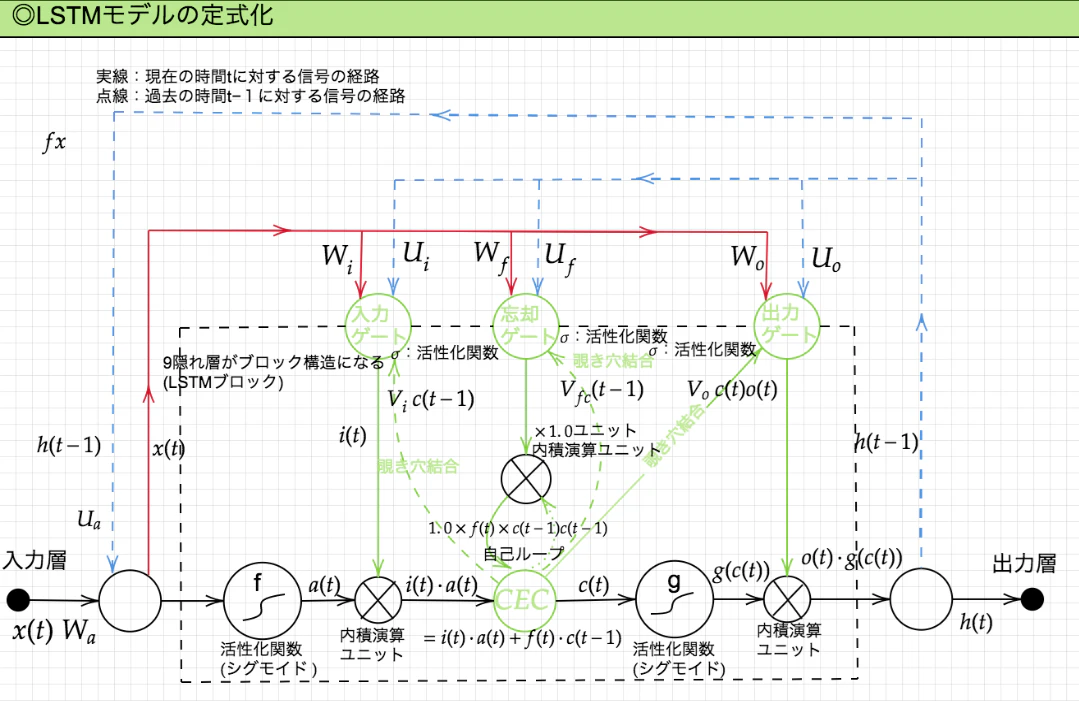
-
RNNの課題:時系列を遡るほど、勾配が消失していく→長い時系列の学習が困難
-
重みの初期値や活性化関数の変更とは別に、RNNの構造自体を変えて勾配消失問題に対処したものがLSTM
-
勾配爆発問題:勾配が層を逆伝播する毎に指数関数的に大きくなっていき、最適値に収束しないこと
2-1 CEC (Constant Error Carousel, 定誤差カルーセル)
- 勾配消失および勾配爆発の解決方法として、勾配が1であれば解決できる。
- CECを用いれば勾配が1になり続けて勾配消失および勾配爆発を回避できる。
- 課題:入力データについて、時間依存度に関係なく重みが一律である。つまりニューラルネットワークの学習特性がないため、CECのみを使うと学習そのものが行われなくなる。
- 入力層→隠れ層への重み:入力重み衝突
- 隠れ層→出力層への重み:出力重み衝突
$$ \delta^{t-z-1} = \delta { Wf'(u^{t-z-1}) } = 1 $$
$$
\frac{\partial E}{\partial c^{t-1}} = \frac{\partial E}{\partial c^t} \frac{\partial c^t}{\partial c^{t-1}} = \frac{\partial E}{\partial c^t} \frac{\partial}{\partial c^{t-1}} { a^t - c^{t-1} } = \frac{\partial E}{\partial c^t}
$$
2-2 入力ゲートと出力ゲート
- 入出力ゲートを追加することで、それぞれのゲートへの入力値の重みを、重み行列W,Uで可変可能とする。これにより、CECに対する重みが一律化する問題を解決した。
2-3 忘却ゲート
- LSTMの現状:CECは過去の情報が全て保管されている。
- 課題:過去の情報が要らなくなっても、削除することができず保管され続ける。さらに、直接関係のないような遠い過去の情報からも影響を受け続ける。
- 解決策:過去の情報が要らなくなったタイミングでその情報を忘却する機能が必要。→忘却ゲート
2-4 覗き穴結合
-
課題:CECに保存されている過去の情報を、任意のタイミングで他のノードに伝播させたり、あるいは任意のタイミングで忘却させたい。←CEC自身の値は、ゲート制御に影響を与えていない
-
覗き穴結合:CEC自身の値に、重み行列を介して伝播可能にした構造。これによりCECから各制御ゲートに対し影響を与えることが可能になった。
Sec3: GRU (Gated Recurrent Unit)
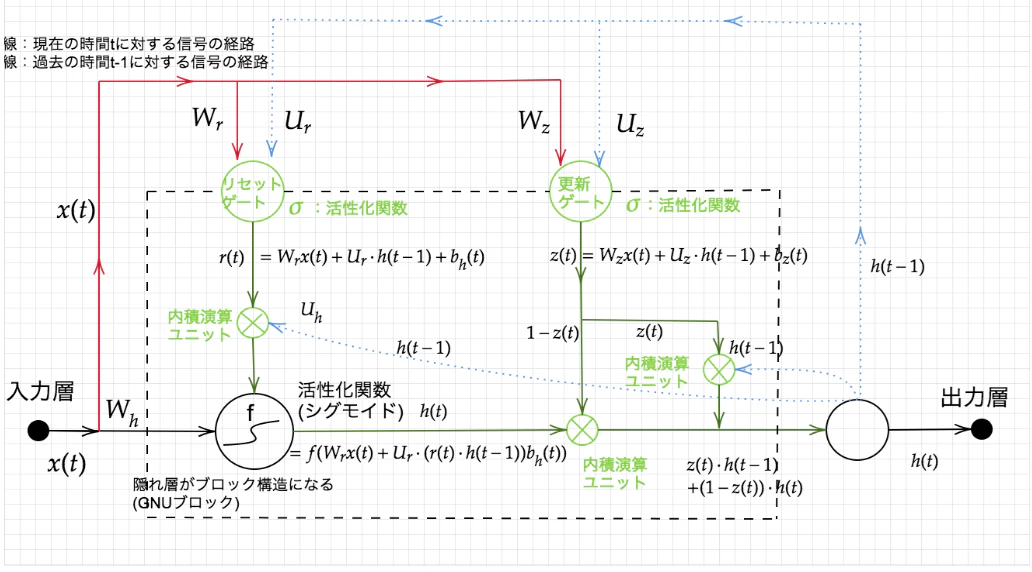
-
課題:LSTMではパラメータ数が多く、計算負荷が大きくなる問題があった。
-
GRUではパラメータを削減しつつ構造を改変し、タスクによっては精度はLSTMと同等かそれ以上が望めるようになった(実務の観点においては必ずしもLSTMの上位互換ではない)。
-
メリット:計算負荷が小さい
Sec4: 双方向RNN
-
過去の情報だけでなく、未来の情報を加味することで精度の向上をさせるモデル
-
実用例:文章の推敲や機械翻訳
Sec5: Seq2Seq
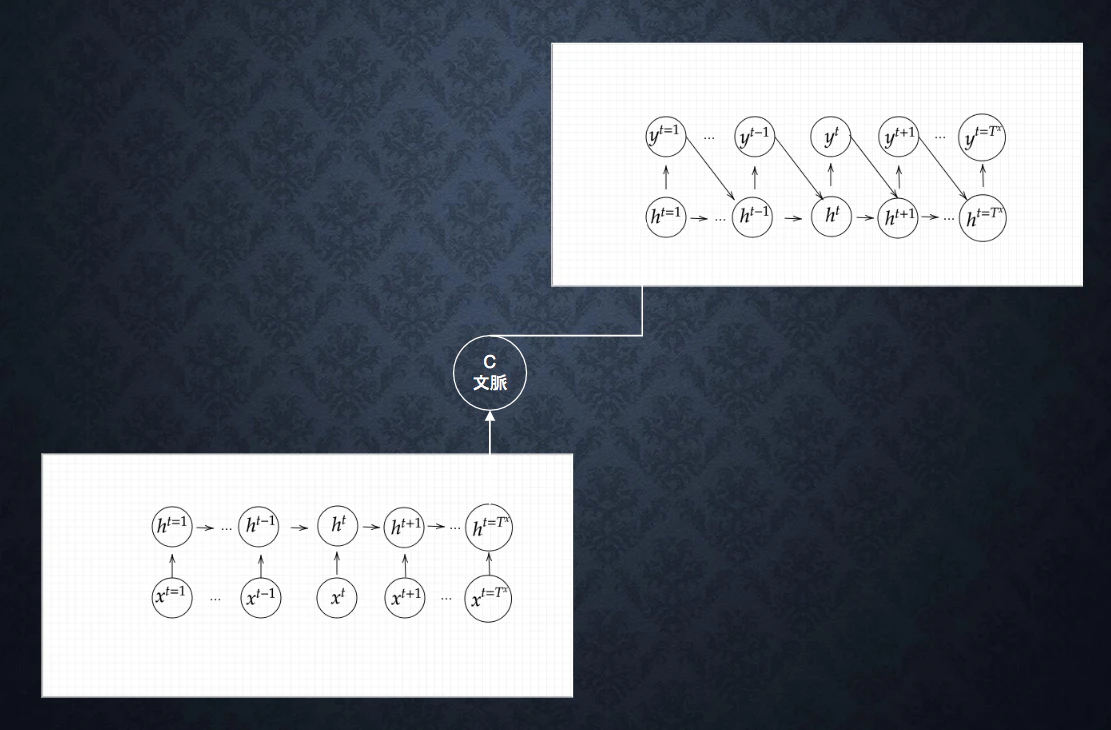
-
Encoder-Decoderモデルの一種
-
実用例:機械対話や機械翻訳
5-1 Encoder RNN
- ユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す構造
- Taking:文章を(単語などの)トークン毎に分割し、トークン毎のIDに分割する
- Embedding:IDから、そのトークンを表す分散表現ベクトル(One-hot ベクトルなど)に変換
- Encoder RNN:ベクトルを順番にRNNに入力していく
- 処理手順:
- vec1をRNNに入力し、hidden stateを出力。これと次の入力vec2をまたRNNに入力し、hidden stateを出力する、という流れを繰り返す。
- 最後のvecを入れた時のhidden stateをfinal stateとして取っておく。このfinal stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなる。
5-2 Decoder RNN
- システムがアウトプットデータを、単語などのトークン毎に生成する
- 処理手順:
- Decoder RNN:Encoder RNN のfinal stateから、各トークンの生成確率を出力。それを Decoder RNN の initial state として設定し、Embeddingを入力する。
- Sampling:生成確率に基づきトークンをランダムに選ぶ。
- Embedding:2で選ばれたトークンをEmbeddingとしてDecoder RNNへの次の入力とする。
- Detokenize:1-3を繰り返し、2で得られたトークンを文字列に直す。
5-3 HRED (Hierarchical Recurrent Encoder-Decoder)
- Seq2Seqの課題:一問一答しかできない
- HRED:過去のn-1個の発話から次の発話を生成する
- Seq2Seqでは会話の文脈無視で応答がなされたが、HREDでは前の単語の流れに即して応答されるため、より人間らしい文脈が生成される。
- HRED = Seq2Seq + Context RNN
- Ccontext RNN:Encoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造→過去の発話の履歴を加味した返答をできる(文脈をベクトル化できる)
- 課題:
- HREDは確率的な多様性が字面にしかなく、会話の「流れ」のような多様性はない。
- HREDは短く情報量に乏しい答えをしがちである。
5-4 VHRED (Variable HRED)
- VHRED:HREDにVAEの潜在変数の概念を追加したもの
5-5 VAE (Variational Autoencoder)
- オートエンコーダー
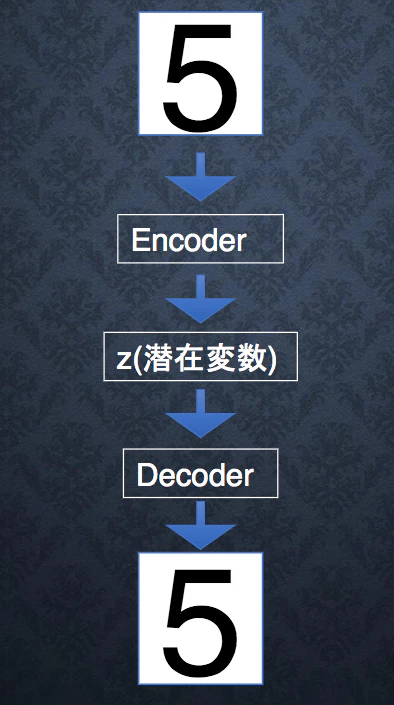
- 教師なし学習
- Encoder:入力データを潜在変数zに変換するNN
- Decoder:潜在変数zを入力して元画像を復元するNN
- メリット:次元削減ができる(zの次元が入力データより小さい場合)
- VAE
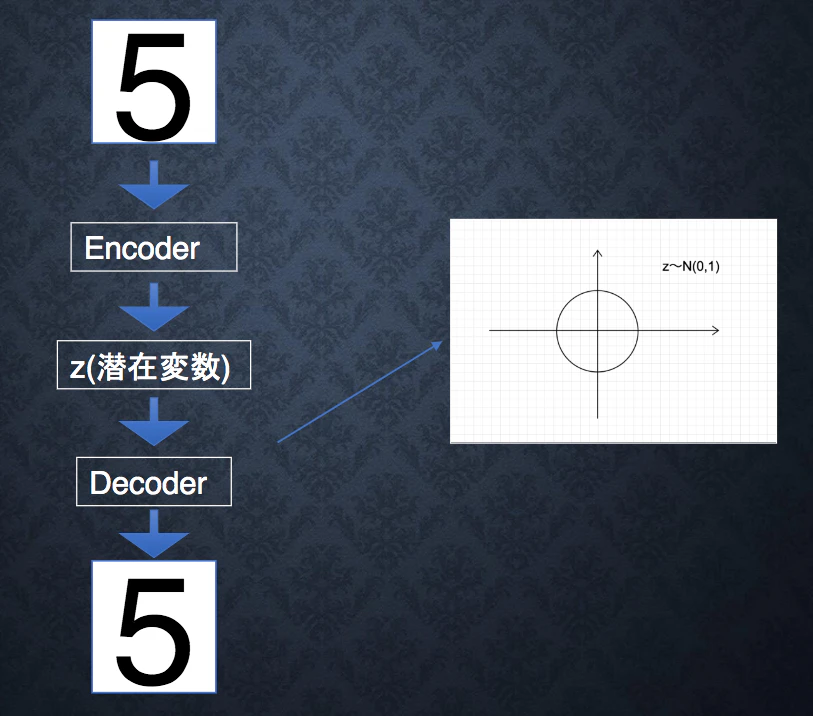
- 通常のオートエンコーダーの場合、何かしら潜在変数zにデータを押し込めているもののその構造がどのような状態かわからない。
- VAEはこの潜在変数zに確率分布z~N(0,1)を仮定したもので、ある程度は構造を可視化できる。
Sec6: Word2vec
- 課題:RNNでは、単語のような可変長の文字列をNNに与えることはできない→固定長形式で表す必要がある。
- メリット:大規模データの分散表現学習が、現実的な計算速度とメモリ量で実現可能になった。
- 従来:ボキャブラリ × ボキャブラリだけの重み行列が誕生
- Word2Vec:ボキャブラリ × 任意の単語ベクトル次元で重み行列が誕生
- 次元を減らしても、単語自体は意味を持った数値として算出できる。
Sec7: Attention Mechanism
-
課題:seq2seqでは長い文章への対応が難しく、何単語であっても固定次元ベクトルに入力しなければならない。
-
解決策:文章が長くなる程そのシーケンスの内部表現の次元も大きくなっていく仕組みが必要
-
Attention Mechanism:入力と出力との間で、どの単語同士が関連しているのかの「関連度」を学習する仕組み
確認テストと考察
Sec0.
- サイズ5×5の入力画像を、サイズ3×3のフィルタで畳み込んだときの出力画像のサイズを答えよ。なお、ストライドは2、パディングは1とする。
OH(OW) = \frac{5 + 2*1 - 3}{2} + 1 = 3
3×3
Sec1.
- RNNのネットワークには大きく分けて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残り1つの重みについて説明せよ。
中間層から次の中間層に渡される際にかけられる重み
- 誤差逆伝播法を説明してみよう。
勾配降下法の一種で、順伝播の際算出される誤差の値を、微分により入力側に伝達する。これは連鎖律を利用し不要な再帰的計算を回避することにより、数値微分を用いた勾配降下法より計算量が少なくて済むというメリットがある。
- 連鎖律原理を使い、dz/dxを求めよ。
$$
z = t^2\
t = x + y
$$
$$
\begin{align}
\frac{dz}{dx} &= \frac{dz}{dt} \frac{dt}{dx}\
&= 2 * 1\
&= 2
\end{align}
$$
- 図中$y_1$を$x, s_0, s_1, w_{in}, w, w_{out}$を用いて数式で表せ。
※バイアスは任意の文字で定義せよ。
※また中間層の出力にシグモイド関数g(x)を作用させよ。
z_1 = g(W_{in}*x + Wz*_0 + b)
y_1 = g(W_{out}*z_1 + c)
- コード演習問題:(お)に当てはまるのはどれか。
(2) delta_t.dot(U)
Sec2.
- 勾配消失問題を説明してみよう。
誤差逆伝播法が下位層に進んでいくにつれて、勾配がどんどん緩やかになっていく。そのため、勾配降下法による更新では下位層のパラメータはほとんど変わらず、訓練は最適値に収束しなくなる。
- シグモイド関数を微分した時、入力値が0の時に最大値をとる。その値として正しいものを選択肢から選べ。
(2)
- 演習チャレンジ:(さ)に当てはまるものはどれか。
(1)gradient * rate
- 以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測において無くなっても影響を及ぼさないと考えられる。
このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもお腹が空いたから何か_____。」
忘却ゲート
- 演習チャレンジ:(け)に当てはまるものはどれか。
(3)
Sec3.
- LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
・LSTM: パラメータ数が多く計算負荷が高い
・CEC: 重みが一律であるため学習そのものに適していない
- 演習チャレンジ:(こ)に当てはまるのはどれか。
新しい中間状態は1ステップ前の中間表現と計算された中間表現の線形和で表現される。
(4) (1-z)*h + z*h_bar
- LSTMとGRUの違いを簡潔に述べよ。
LSTMはパラメータ数が多く計算負荷がい大きいが、GRUは構造が簡素で計算負荷が比較的小さい。
Sec4.
- 演習チャレンジ:(か)に当てはまるのはどれか。
(4) np.concatnate([h_f, h_b[: : -1]], axis=1)
Sec5.
- 選択肢から、seq2seqについて説明しているものを選べ。
(2)
- 演習チャレンジ:(き)に当てはまるのはどれか。
(1) E.dot(w)
- seq2seqとHRED、HREDとVHREDとの違いを簡潔に述べよ。
・seq2seqとHRED:seq2seqは一問一答形式の応答のみだがHREDは前の文脈に即した応答が可能
・HREDとVHRED:HREDは短い単調な応答になりがちだがVHREDは多彩な応答が可能
- VAEに関して空欄に当てはまる言葉を答えよ:自己符号化器の潜在変数に___を導入したもの。
確率分布
Sec7:
- RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ。
・RNNとword2vec:RNNは固定長単語ベクトルのみ対応できたが、word2vecでは可変長単語ベクトルにも対応することで計算速度向上とメモリ使用量削減することができた。
・seq2seqとseq2seq + Attention Mechanism:seq2seqは固定次元ベクトルしか学習できないが、seq2seq + AMでは入出力の関連度・重要度を学習し可変次元ベクトルに対応することで、長い文章の翻訳も可能になった。
- 演習チャレンジ:(く)に当てはまるのはどれか。
(2) W.dot(np.concatenate([left, right]))
演習結果と考察
3_1_simple_RNN
- tanh関数はsingmoid関数と似て、滑らかな表現ができるのは通す値が小さい場合(6 ~ -6程度)のみであり、大きい値はその特徴を潰してしまうため使用の際は注意が必要か。
3_3_predict_sin
- maxlen や iters_num を増やすことで精度改善することが確認できた。