はじめに
OPENLOGI Advent Calendar 2020 の12月14日の記事です。
オープンロジの技術開発部では、ビジネスサイドへの技術的な支援やログ監視をする当番を1週間ごとに1〜2名で交代しながら運用しており、この作業を社内では「オペ」と呼んでいます。
具体的にはこのオペでは以下をします。
- 機能の仕様回答
- 障害の報告、調査、暫定対応
- (画面上ではまだ対応が追いついていない、大量データの扱いたいときの)バッチ処理の実行
- ログ監視
- システムから分かる統計情報をとるための Redash クエリの作成
サービスの成長に伴ってしたいことやすべきことが増えるはずで、仮になにも改善をしないのであればサービスの成長に伴ってこのオペのコストも増えていき、人手を増やすしかなくなります。
ですが、人手を増やしていくペースには限界があると思いますので、サービス側の機能追加、社内向け管理画面に機能追加、FAQ や Wiki などのドキュメント追加などの改善をすることで、このオペのコストの増加を緩やかにする必要があります。
2020年6月あたりに、このオペを改善するための定量的な指標として Redash で以下の2つのクエリを作成してみました。
- オペ依頼件数の推移
-
- の中で手順がパターン化されているバッチ処理の実行依頼数のランキング
この記事では上記2つのクエリについて紹介したいと思います。
似たような業務があり、同様の指標を作ろうと思っている方々へのサンプルとして参考になれば幸いです。
前提環境
オープンロジでは、機能要望/不具合/オペ依頼に関して、EC2 上に稼働させている Redmine でチケット管理をしています。
現状、この Redmine のデータベースは MySQL を使っており、Redash はこの MySQL をデータソースとして扱えるように設定されています。
以後紹介するクエリはこのデータソースに対してのクエリとなります。
それぞれのバージョンは以下です。
Redmine: 4.0
Redash: 8.0.0
MySQL: 8.0
オペ依頼件数の推移のクエリについて
最初に紹介するのは Redmine に起票されたオペ依頼件数の推移を確認するグラフです。
まずは、現在のオペ依頼件数は過去にくらべてどのような値なのか、また一時的なものなのか慢性的に増えてきているのかを判断できる指標を用意して、どれくらい改善が急を要する状況なのかを判断できる指標が欲しいと思いました。
そこで、過去から現在のオペ依頼の Redmine チケットの件数の推移と傾向を把握できるグラフを用意することにしました。
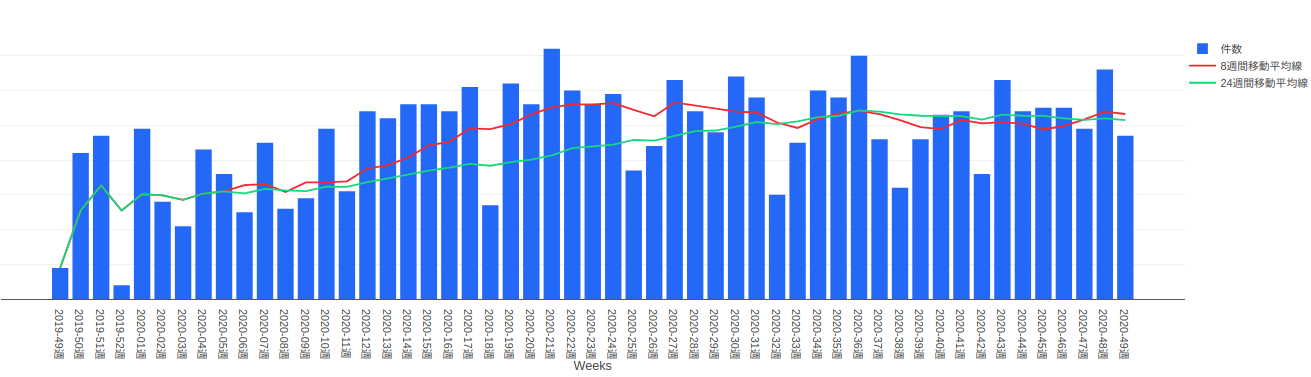
青の棒グラフは、週ごとに起票されたオペ依頼のチケット数を表しています。
赤の折れ線グラフは、8週間分の移動平均線を表しています。
緑の折れ線グラフは、24週間分の移動平均線を表しています。
移動平均線を用意することで、その週の瞬間的な量だけでなく、全体的な傾向を確認できるようにしてあります。
たとえば、上述のグラフだと、2020-12週あたりから2020-27週あたりまでは増加傾向にありましたが、それ以降は2つの移動平均線がどちらともほぼ横ばいでオペ依頼の量の増減は落ち着いている状況なのがわかります。
このグラフを表現するための SQL は以下となります。
select
week,
counts,
AVG(counts) OVER (ORDER BY week ROWS BETWEEN 8 PRECEDING AND CURRENT ROW) AS avg_count_8week,
AVG(counts) OVER (ORDER BY week ROWS BETWEEN 24 PRECEDING AND CURRENT ROW) AS avg_count_24week
from (
select
date_format(i.created_on, '%X-%V週') as week,
count(i.id) as counts
from issues i
join projects p on i.project_id=p.id
join trackers t on i.tracker_id=t.id
where
p.name='開発'
and t.name in ('Task', 'Support')
and i.created_on >= current_timestamp - interval '12' month
group by week
order by week asc
) as w
;
オペのチケットはプロジェクトが「開発」であり、トラッカーが「Task」または「Support」となっています。
現在日時から12ヶ月分のそれらのチケットを週ごとに集計後、さらに8週間と24週間の移動平均も算出している感じです。
グラフの Visualization Editor の設定値は以下です。
- General
- ChartType: Line
- X Column: week
- Y Columns: counts, avg_count_8week, avg_count_24week
- X Axis
- Name: Weeks
- Y Axis
- Left Y Axis
- Name: counts
- Left Y Axis
- Series
- 1
- Left Y Axis
- Label: 件数
- Type: Bar
- 2
- Left Y Axis
- Label: 8週間移動平均線
- Type: Line
- 3
- Left Y Axis
- Label: 24週間移動平均線
- Type: Line
- 1
パターン化されているバッチ処理の実行依頼数のランキングについて
次に紹介するのはパターン化されているバッチ処理の実行依頼数をランキング形式で表現した表です。
前述のグラフでは過去と現在の状況を可視化できるようになりました。
では、次はどこから改善すればより効果的かを判断できる指標が欲しいと考えました。
「はじめに」の項にあげた以下のバッチ処理の実行手順はパターン化されています。
- (画面上ではまだ対応が追いついていない、大量データの扱いたいときの)バッチ処理の実行
これらについては、発生数が多いのであればサービス上での機能化や手順の簡略化を検討すべきであり、スクリプトなどの手順が用意されている状況であれば機能化するコストも低いはずなので、まずはここから改善するのがやりやすいと考え、それをわかりやすいようにランキング形式で表を作ってみようと思いました。
以下が実際の表です。1
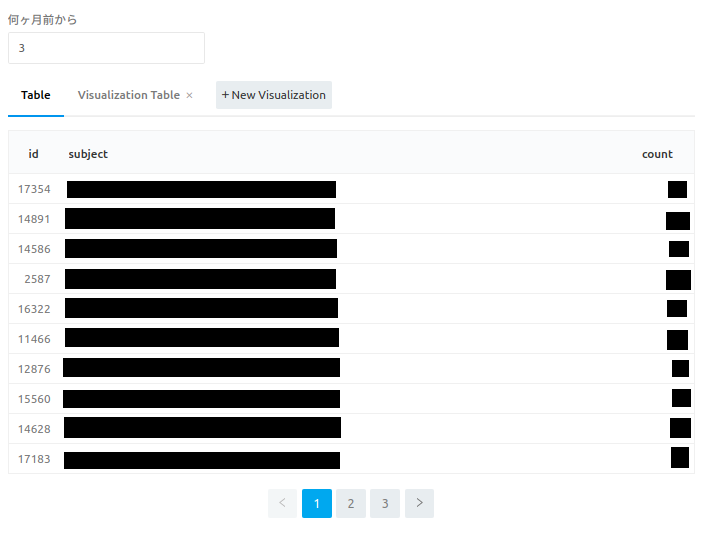
id カラムは Redmine のバッチ処理の手順が書かれたチケットの IDです。
subject カラムは Redmine のバッチ処理の手順が書かれたチケットの題名です。
count はバッチ処理の手順が書かれたチケットに紐づく実際のオペ依頼のチケットの件数で、count の多い順にソートしてあります。
この表を表現するための SQL は以下となります。
select
target_issue.id as id,
target_issue.subject as subject,
count(target_issue.id) as `count`
from issues issue
join projects issue_project on issue.project_id=issue_project.id
join trackers issue_tracker on issue.tracker_id=issue_tracker.id
left join issue_relations ir on issue.id=ir.issue_to_id
left join issues target_issue on ir.issue_from_id=target_issue.id
left join projects target_issue_project on target_issue.project_id=target_issue_project.id
left join trackers target_issue_tracker on target_issue.tracker_id=target_issue_tracker.id
where
issue_project.name='開発'
and issue_tracker.name in ('Task', 'Support')
and issue.created_on >= now() - interval {{ 何ヶ月前から }} month
and ir.relation_type='copied_to'
and target_issue_project.name='運用'
and target_issue_tracker.name='Task'
group by target_issue.id
order by `count` desc
;
前述のグラフでも説明したとおり、オペ依頼のチケットはプロジェクトが「開発」であり、トラッカーが「Task」または「Support」となっています。
すでに過去の実績があってパターン化しているバッチ処理は、プロジェクトは「運用」、トラッカーは「Task」の形で手順が書かれたチケットが用意されていて、各オペ依頼のチケットはこのチケットをコピー元2として関連づけしてあるような運用です。
表の Visualization Editor の設定値は以下です。
- Columns
- id
- Display as: Number
- Number format: 0
- subject
- Display as: Text
- Allow HTML content: true
- count
- Display as: Number
- Number format: 0
- id
- Grid
- Items per page: 10
今後の課題
今後の課題としては、現状はどちらの指標もチケットの件数でしかみておらず、チケット1つ1つの対応の重みを考慮できていません。
これに関しては、都度チケットに重みを設定をしていく対応コストとの兼ね合いになりますが、件数だけでは定性的な感覚との差異があまりにも大きく感じるようになってきたら検討していきたいと思っています。
また、改善の優先度判断は 3) のみしか可視化できていないのも気になっており、「はじめに」の項に挙げた 1) から 5) のオペ依頼の種類の比率も気になっています。
3) 以外の対応の方が改善する優先度が高い可能性もあるためです。
さいごに
以上となります。
他のサービス運用でも、この記事であげたオペのような業務は大小は違うと思いますが、0ではないかなと思っています。
それを改善するにあたって、まずは定量的に可視化したいと考え始めた時に本記事が1つの参考情報となれば幸いです。