はじめに
機械学習を始めた人がまず最初に手に触れるPythonのライブラリの一つがscikit-learn. なんて話はよくあると思います. scikit-learnには独自の設計思想があり,
- モデルのインスタンスを生成する. このときにハイパーパラメータを一緒に設定する.
-
.fit()でモデルを訓練する. -
.predict()で予測する.
という, 非常にわかりやすい一貫した作りになってます. そのため, 使い方も初心者向に易しい方だと思います.
一方, scikit-learnでは扱われていない機械学習アルゴリズムの1つである「ニューラルネットワーク」は, kerasやtensorflow, pytorchで実装するのが一般的です. これらのライブラリはそれぞれに設計が異なるため, 当たり前ですが使い方もまちまちです. これ, 面倒でよね. 全て.fit()でモデルを訓練できれば楽に作業できるし, 作業効率が上がるのに... こんな悩みを著者はよく抱きます. 今回は, kerasのニューラルネットワークをscikit-learnライクに扱えるように実装してみます.
サンプルデータ
サンプルデータにはscikit-learnのbostonデータを使います.
from sklearn.datasets import load_boston
boston = load_boston()
X = boston['data']
y = boston['target']
kerasによるニューラルネットワークの実装
まずkerasによるオーソドックスなneural networkの実装をおさらいしましょう. まず, データセットをトレーニングセットとバリデーションセットとテストセットに分割します.
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=1647)
_, te_idx = list(kf.split(X, y))[0]
tr_idx, va_idx = list(kf.split(X[_], y[_]))[0]
X_te, y_te = X[te_idx], y[te_idx]
X_tr, y_tr = X[_][tr_idx], y[_][tr_idx]
X_va, y_va = X[_][va_idx], y[_][va_idx]
説明変数を見ていきます.
pd.DataFrame(X).isnull().sum(axis=0).sum()
>> 0
説明変数に欠損値はありませんでした.
次に, 説明変数の分布を見ていきます.
pd.DataFrame(X).iloc[:,0].hist(bins=50)
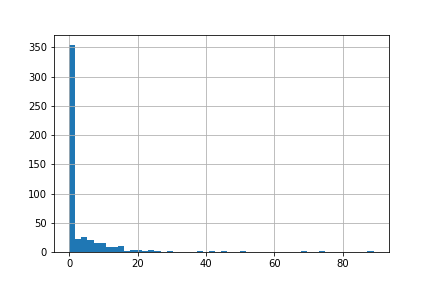
説明変数が正規分布してません. ニューラルネットワークはこのような入力に弱いので, 説明変数を強制的に正規分布っぽくしていきます.
from sklearn.preprocessing import QuantileTransformer
transformer = QuantileTransformer(n_quantiles=100, random_state=0, output_distribution='normal')
X_train = transformer.fit_transform(X_tr)
X_valid = transformer.transform(X_va)
X_test = transformer.transform(X_te)
pd.DataFrame(X_train).iloc[:,0].hist(bins=50)
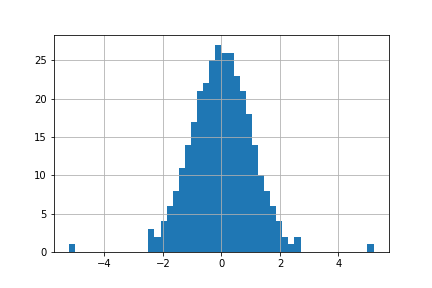
準備ができましたので, モデルの実装に移ります.
from keras.callbacks import EarlyStopping
from keras.layers.advanced_activations import ReLU
from keras.layers.core import Dense, Dropout
from tensorflow.keras.layers import BatchNormalization
from keras.models import Sequential
from tensorflow.keras.optimizers import Adam
model = Sequential()
# input layer
model.add(Dropout(0.001, input_shape=(X_train.shape[1],)))
# hidden layer
for i in range(2):
model.add(Dense(10))
model.add(BatchNormalization())
model.add(ReLU())
# out layer
model.add(Dense(1))
# optimizer
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, decay=0.)
# compile
model.compile(
loss='mean_squared_error',
optimizer=optimizer,
metrics=['mae']
)
# eaerly stopping
early_stopping = EarlyStopping(patience=100, restore_best_weights=True)
# train
history = model.fit(
X_train,
y_tr,
batch_size=32,
epochs=10000,
verbose=1,
validation_data=(X_valid, y_va),
callbacks=[early_stopping]
)
scikit-learnライクなニューラルネットワークの実装
以下のようにNNRegressorというクラスを新しく設計して, コンストラクタの引数にモデルのアーキテクチャに関する設定を記述すれば, scikit-learn風に走らせることができて便利です.
class NNRegressor:
def __init__(self, input_dropout=0.01, hidden_layers=2, hidden_units=256, hidden_dropout=0.01,
batch_norm="before_act", learning_rate=1e-5, batch_size=64, epochs=10000,
standardization=True
):
self.input_dropout = input_dropout # layer param
self.hidden_layers = int(hidden_layers) # layer param
self.hidden_units = int(hidden_units) # layer param
self.hidden_dropout = hidden_dropout # layer param
self.batch_norm = batch_norm # layer param
self.learning_rate = learning_rate # optimizer param
self.batch_size = int(batch_size) # fit param
self.epochs = int(epochs) # fit param
self.standardization = standardization
def fit(self, X_train, y_train, eval_set, early_stopping_rounds, eval_metric, verbose=1):
# Data standardization
if self.standardization:
self.transformer = QuantileTransformer(n_quantiles=100, random_state=0, output_distribution='normal')
X_train = self.transformer.fit_transform(X_train)
X_valid = self.transformer.transform(eval_set[0])
elif self.standardization is False:
X_valid = eval_set[0]
# Keras Wrapper for sklearn AIP
def create_model():
model = Sequential()
model.add(Dropout(self.input_dropout, input_shape=(X_train.shape[1],)))
for i in range(self.hidden_layers):
model.add(Dense(self.hidden_units))
if self.batch_norm == 'before_act':
model.add(BatchNormalization())
model.add(ReLU())
model.add(Dropout(self.hidden_dropout))
model.add(Dense(1))
# Optimazer
optimizer = Adam(lr=self.learning_rate, beta_1=0.9, beta_2=0.999, decay=0.)
# Compile
model.compile(
loss=eval_metric,
optimizer=optimizer,
metrics=['mae']
)
return model
early_stopping = EarlyStopping(patience=early_stopping_rounds, restore_best_weights=True)
self.model = create_model()
self.model.fit(
X_train,
y_train,
batch_size=self.batch_size,
epochs=1000,
verbose=1,
validation_data=(X_valid, eval_set[1]),
callbacks=[early_stopping]
)
def predict(self, x):
if self.standardization:
x = self.transformer.transform(x)
y_pred = self.model.predict(x).astype("float64")
y_pred = y_pred.flatten()
return y_pred
def get_model(self):
return self.model
def get_transformer(self):
if self.standardization:
return self.transformer
トレーニングは以下のように行います.
model = NNRegressor(
input_dropout=0.01, hidden_layers=2, hidden_units=256, hidden_dropout=0.01,
batch_norm="before_act", learning_rate=1e-3, batch_size=32, epochs=1000,
standardization=True
)
history = model.fit(
X_train=X_tr,
y_train=y_tr,
early_stopping_rounds=10,
eval_set=(X_va, y_va),
eval_metric='mean_absolute_error'
)