[追記]
何か質問、修正、提案があれば気軽にコメントしてください。
どんどんいいものを作って行きたいので、是非お願いします…!
[追記終わり]
毎日arxivをチェックしようと意気込んでいるのですが、なんだかんだ忘れてしまうことが多いのでいっそのこと毎日Slackにでも更新情報を流してくれるbotでも作っちゃえということで作成しました。
こんな人におすすめ
・スクレイピングやってみたい人(seleniumとか)
・pythonでbot作ってみたい人
・arxivをチェックするの忘れる人
・arxivから興味のある論文だけを教えて欲しい人(今回やりませんが、正規表現などで簡単にできると思います。)
こんな感じ
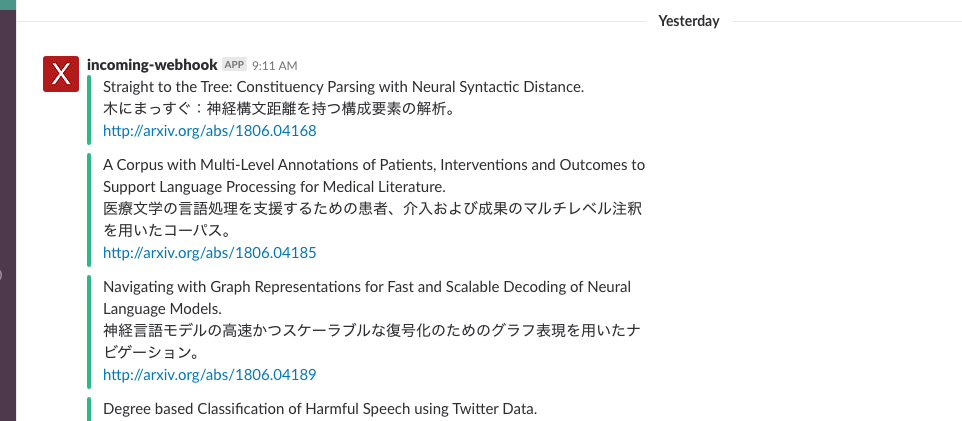
arxivの新規論文を毎日9時にSlackに通知してくれます。
僕の場合、日本語訳がある方がぱっと見で分かりやすいのでGoogle翻訳による日本語訳も一緒に出してます←
通知内容はこんな感じです。
インストールとセッティング
・python3系
・slackアカウント
・google chrome
ここらへんは既に使われてることが多いと思います。
seleniumのインストール
今回自動でwebページを巡回するために利用するツールです。
pythonのパッケージとしてサポートされてるのでpipでインストールします。
pip install selenium
chromedriverのインストール
SeleniumがChromeを操作するためのドライバーです。
macならhomebrew、linuxならlinuxbrewでインストールできます。
他OSでもここからダウンロードできます。
brew install chromedriver
slack webhookの設定
slackに外部から投稿するためのAPIとしてWebHooksを利用します。
SlackのIncoming Webhooksを使い倒す にWebHooksの取得の仕方が記載されてるので、「Incoming Webhooksのエンドポイントを取得する」の項を順に行って設定してください。
ここで、記事にあるようにWebhookURLをメモしておいてください。 ...(1)
Pythonコーディング
実際のコードとその説明を載せます。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
seleniumをインポート
options = Options()
# ヘッドレスモードで起動。
options.add_argument('--headless')
# ChromeのWebDriverオブジェクトを作成する。
# Cronで動かす際には特にexecutable_pathが必要
driver = webdriver.Chrome(executable_path="/usr/local/bin/chromedriver", chrome_options=options)
seleniumでgoogle chromeを起動。
毎回ブラウザが開くと閉じるのがめんどくさいのでheadlessモードで起動します。
executable_pathには
which chromedriver
の結果を書いてください。僕の場合は/usr/local/bin/chromedriverでした。
import slackweb
# webhookのURL
WEBHOOK_URL = "https://hooks.slack.com/services/*******/*******/***************"
# webhookをセット
slack = slackweb.Slack(url=WEBHOOK_URL)
(1)で確認したWebhookのURLを入れて(WEBHOOK_URL="ここに入れる")、slackwebにセットします。
slackwebがない場合は
pip install slackweb
でインストール。
rss = feedparser.parse("http://export.arxiv.org/rss/cs.CL")
arxivの更新情報は毎日RSSという形式で更新されていきます。
arxivの公式ページから詳細が見れます。
例えばComputer ScienceのComputation and Languageの論文の情報が知りたいときには
http://export.arxiv.org/rss/cs.CL
を見ればいいことになります。
興味のある分野に合わせてparse("ここ")を変えてください。
ここからがスクレイピングのコードです。
# 英語のタイトルを日本語に翻訳する関数。
def translate(summary):
#Google翻訳を開く
sleep(3)
driver.get("https://translate.google.com/?hl=ja")
#英語を打ち込む
driver.find_element_by_id("source").send_keys(summary)
#"翻訳"ボタンを押す
driver.find_element_by_id("gt-submit").click()
#翻訳待ち
sleep(3)
#翻訳後の日本語取得
result = driver.find_element_by_id("result_box").text
return result
# 論文ごとのクラス
class Entry():
def __init__(self,entry):
#著者、URL、タイトル、要約を取得。
self.author = [re.sub("<.+?>","",a) for a in entry.author.split(", ")]
self.url = entry.id
self.title = re.sub(" \(arXiv:.+\)$","",entry.title)
self.author_info = {}
#タイトルと要約を英日翻訳
def translate(self):
#translate by google translation
self.title_ja = translate(self.title)
self.summary_ja = translate(self.summary)
# RSSのエントリー(新規論文)ごとに翻訳
for one_entry in rss.entries:
try:
# Entryのクラスを作成
entry = Entry(one_entry)
# 翻訳
entry.translate()
新規論文の情報はrss.entriesにリスト形式で格納されてます。
なのでこれをfor文で回せば1論文ごとの情報が取得できます。
今回はクラスを使用して、initで著者、URL、タイトル、要約を取得しておきます(もちろんクラス使わなくてもOK)。
次に翻訳ですが、上のtranslate関数で可能です。
翻訳の際のseleniumの動きがどうなってるか気になったら、headlessモード以外で起動してやってみてください。
seleniumの使いかたは調べたら出てくると思いますが、開発は基本的に
- ページのソースをみる(chromeの場合、知りたい要素を右クリックして"検証")
2. 要素のidかxpathを調べてseleniumで指定
3. click()クリック/ textで本文取得/ etc...
の流れです。
# 論文ごとのクラス
class Entry():
## initとtranslate関数がここにあります##
def arrange_attachment(self):
self.attachments = [
{
"fallback": "Required plain-text summary of the attachment.",
"color": "#2eb886",
"fields": [
{
"value": self.title+"\n"+self.title_ja+"\n"+self.url,
"short": False
}
],
"image_url": "http://my-website.com/path/to/image.jpg",
"thumb_url": "http://example.com/path/to/thumb.png",
}
]
for one_entry in rss.entries:
try:
# Entryのクラスを作成
entry = Entry(one_entry)
# 翻訳
entry.translate()
# slackに送る情報(attachment)を作成
entry.arrange_attachment()
attachments = entry.attachments.copy()
# 通知する
slack.notify(attachments=attachments)
#接続エラーやロボット検出があればストップ(多分問題なし)
except:
break
slackのwebhookに情報を渡すにはslack.notifyという関数を利用しますが、ここでattachmentsという引数に通知したい情報を辞書形式で渡します。
このattachmentの書き方の詳細はslack webhook公式ページからみれます。
これでSlackに通知がくるかと思います!
(しかし通知がうるさいので、通知音やホーム画面への通知は切っておくことをオススメします笑)
cron
ここまででarxivの新着情報をpythonによってslackに送ることができました。
次はcronというデーモンプログラムで時間や日付を指定して、バックグラウンドで先ほど作ったarxivbot.pyを実行させます。ちなみにwikiによるとデーモンという言葉はdemon(悪魔)とdeamon(守護神)の2通りの書き方が使われてるみたいですね。厨二でかっこいい()
やることは非常に簡単で、
crontab -e
でcronの設定ファイルを開き、
0 9 * * * {pythonのpath} {arxiv_botのpath}
と書くだけです。
ここで、{pythonのpath}は
which python
の結果で、{arxiv_botのpath}はarxiv_botの絶対PATHです。
0 9 * * * というのは
0分 9時 *日 *月 *年ということで、つまり毎日9時0分に実行するということになります。
これが出来ればbotの作成が終了です。お疲れ様でした。