記事の目的
正規分布と、平均と分散が未知の時の共役事前分布である正規分布を使用し、Rを使ってベイズ推定を行います。
20代男性の身長の平均と分散を事後分布で推定します。
参考:ベイズ推論による機械学習入門
目次
1. モデルの説明
2. 推定する分布
3. 事前分布
4. 事後分布
5. 予測分布
1. モデルの説明

2. 推定する分布
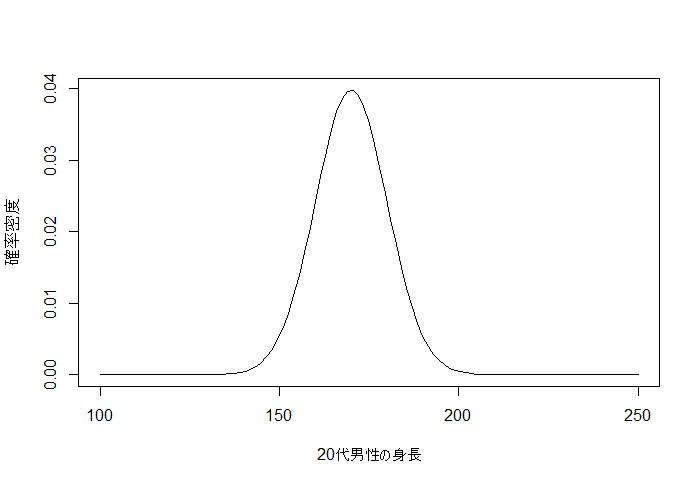
20代男性の身長は、平均が170で標準差が10の正規分布に従います(適当)。しかし、僕たちはそれを知りません。
この、真の分布の平均170と分散の逆数1/100=0.01を事後分布で推定します。
curve(dnorm(x, 170, 10), 100, 250, xlab="20代男性の身長", ylab="確率密度")
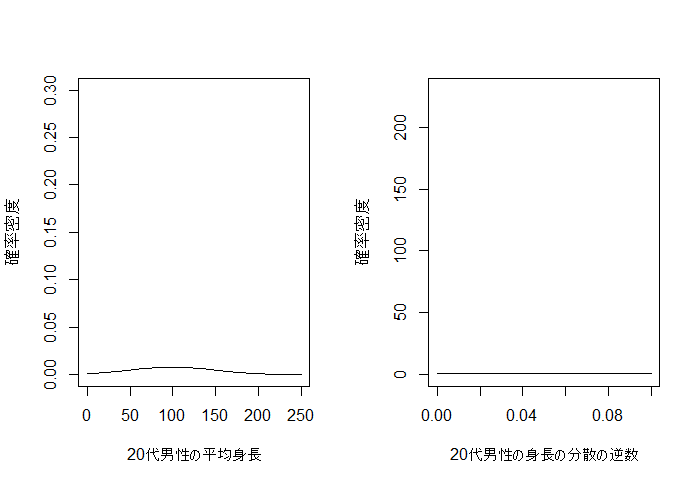
3. 事前分布
平均の事前分布として正規分布、分散の逆数の事前分布としてガンマ分布を仮定します。
どちらもデータに適合しやすいようにパラメータを設定しています。
par(mfrow=c(1,2))
lambda0 <- 1
beta0 <- 1/100^2
m0 <- 100
lambda.mu0 <- 1/50^2
curve(dnorm(x, m0, 1/sqrt(lambda.mu0)), 0, 250,
xlab="20代男性の平均身長", ylab="確率密度", ylim=c(0,0.3))
a0 <- 1
b0 <- 1
curve(dgamma(x, a0, b0), 0, 0.1, ylim=c(0,230),
xlab="20代男性の身長の分散の逆数", ylab="確率密度")
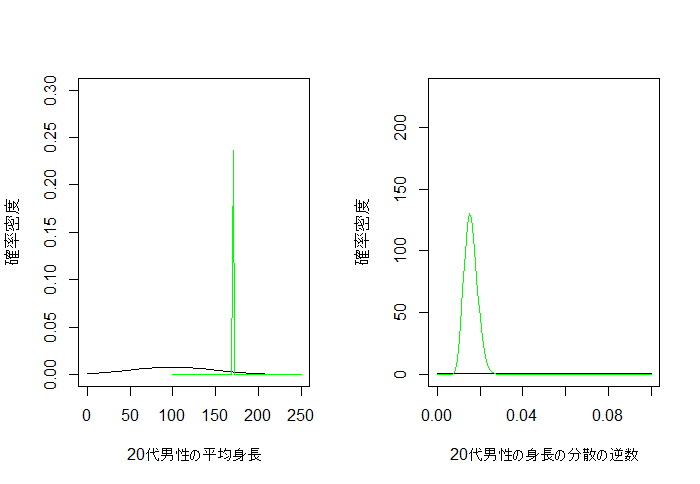
4. 事後分布
真の分布がら100個のサンプルを取って事後分布を推定します。
事後分布は緑の曲線です。平均は170, 分散は1/100=0.01をうまく推定できています。
# データ
N <- 50
X <- rnorm(N, 170, 10)
# 事後分布
beta <- N + beta0
m <- (sum(X)+beta0*m0)/beta
curve(dnorm(x, m0, 1/sqrt(lambda.mu0)), 0, 250,
xlab="20代男性の平均身長", ylab="確率密度", ylim=c(0,0.3))
curve(dnorm(x, m, 1/sqrt(lambda0*beta)), 100, 250, add=T, col="green")
a <- N/2 + a0
b <- (sum(X^2)+beta0*m0^2-beta*m^2)/2+b0
curve(dgamma(x, a0, b0), 0, 0.1, ylim=c(0,230),
xlab="20代男性の身長の分散の逆数", ylab="確率密度")
curve(dgamma(x, a, b), 0, 0.1, add=T, col="green")
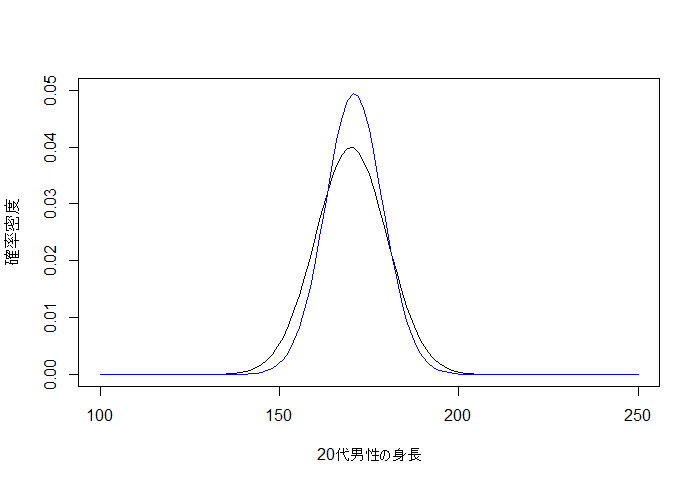
5. 予測分布
予測分布も、うまく推定できていることが分かります。
u.p <- m
lambda.p <- beta*a/((1+beta)*b)
n <- 2*a
par(mfrow=(c(1,1)))
curve(dnorm(x, 170, 10), 100, 250,ylim=c(0,0.05),xlab="20代男性の身長", ylab="確率密度")
curve(dt(x, df=n)*((1+x^2/n)^((n+1)/2))*sqrt(lambda.p)*((1+lambda.p*(1/n)*(x-u.p)^2)^(-(n+1)/2)), 100, 250,
add=T, col="blue")