記事の目的
ポアソン混合モデルのギブスサンプリングをRで実装します。
参考:ベイズ推論による機械学習入門
目次
0. ライブラリ
1. モデルの説明
2. 推定する分布
3. パラメータ初期値設定
4. 事後分布
5. 確認
0. ライブラリ
library(dplyr)
library(mvtnorm)
library(MCMCpack)
library(gganimate)
set.seed(100)
1. モデルの説明

2. 推定する分布
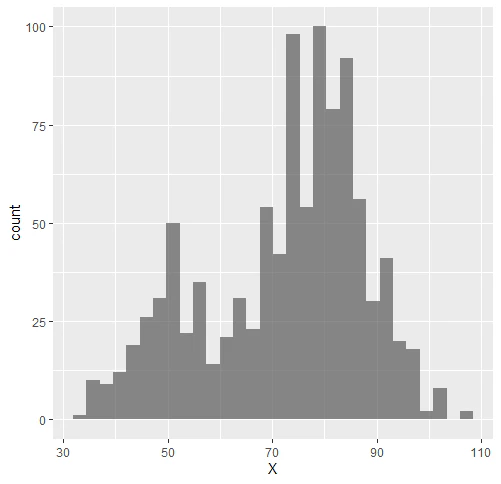
50が平均のポアソン分布と、80が平均のポアソン分布が1:3の割合で混合しているモデルです。
N <- 1000
s.true <- rmultinom(N, 1, c(1/4, 3/4)) %>% apply(2, which.max)
X <- append(rpois(N, 50)[s.true==1], rpois(N, 80)[s.true==2])
NULL %>% ggplot(aes(x=X)) + geom_histogram(position = "identity", alpha=0.7)
N <- length(X)
3. パラメータの初期値設定
# ハイパーパラメータ設定
K <- 2
alpha0 <- rep(1/K, K)
a0 <- rep(1, K)
b0 <- rep(1, K)
# パラメータ初期値設定
pi <- rep(1/K, K)
s <- rep(1:K, N)[1:N]
lambda <- rep(100, K)
alpha <- {}
a <- {}
b <- {}
s.Data1 <- data.frame(s, iter=rep(0, N))
4. 事後分布
max.iter <- 30
eata <- matrix(NA, nrow = N, ncol=K)
for(t in 1:max.iter){
#sのサンプリング
for(i in 1:N){
eata[i, ] <- (X[i]*log(lambda) - lambda + log(pi)) %>% exp()
s[i] <- rmultinom(1, 3, eata[i, ]) %>% apply(2, which.max)
}
s.Data2 <- data.frame(s, iter=rep(t, N))
s.Data1 <- rbind(s.Data1, s.Data2)
#lambdaのサンプリング
for(k in 1:K){
a[k] <- sum(X[s==k]) + a0[k]
b[k] <- (X[s==k] %>% length()) + b0[k]
lambda[k] <- rgamma(1, a[k], b[k])
}
#piのサンプリング
for(k in 1:k){
alpha[k] <- (X[s==k] %>% length()) + alpha0[k]
}
pi <- rdirichlet(1, alpha)
}
5. 確認
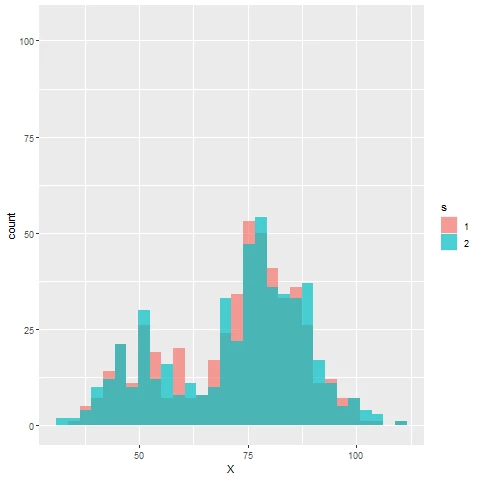
iter15でだいたい分類できていることが分かります。
s.Data <- s.Data1 %>% filter(iter==0|iter==5|iter==15|iter==20|iter==25|iter==30)
s.Data <- data.frame(X=rep(X, 6), s.Data)
s.Data$s <- s.Data$s %>% as.factor()
s.Data %>% ggplot(aes(x=X, fill=s)) + geom_histogram(position = "identity", alpha=0.7) +
transition_states(iter, transition_length = 2, state_length = 1)