この記事について
この記事は筆者がCourseraの"Deep Learning"というオンライン授業を受ける中で、思考を整理したり、知らなかったことを書き留めるための私的なメモである。
なおこの記事では(多分Deep Learningのオンライン授業もその前提だと思いますが)Courseraの別のオンライン授業、Ng Andrew先生の"Machine Learning"を既習のものとしています。
私的なメモではありますが、筆者と同じくMachine Learningの授業を一通り終えたけど、まだDeep Learningには馴染みがないという方には少しばかりか学習の助けになれば幸いです。
コース1-Week2 ニューラルネットワークの基礎
ロジスティック回帰
nx次元ベクトルxが与えられとき、y = P(y=1|x)を出力するのがロジスティック回帰。
パラメータ:w=nx次元ベクトル、b=バイアス項(実数)
出力: y = Sigmoid(wT*x + b) ※別の書き方σ(wT*x + b)
ロジスティック回帰はy=1である確率として0〜1の数値で出力する必要があるのでシグモイド関数を使う。
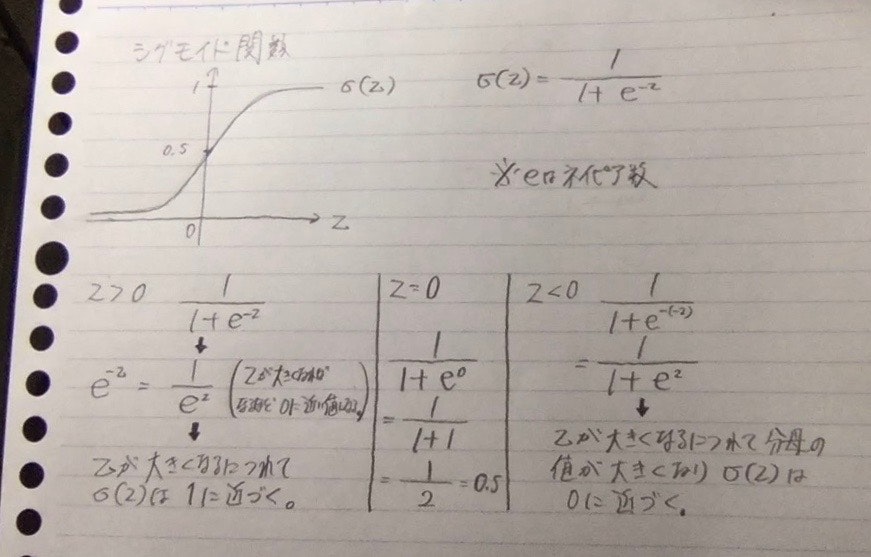
パラメータwとbを学習させる。
ロジスティック回帰の損失関数・コスト関数
ロジスティック回帰において二乗誤差を損失関数に使うと、局所解を多く持つようになってしまい最適化が上手に出来ないので、使わない。ロジスティック回帰の損失関数は綺麗に凸な関数なのだ。
ここで損失関数は一つの教師データを対象にしており、コスト関数はm個の教師データを対象にしている。よってコスト関数はm個のデータの損失関数の平均である。
また、損失関数はyがtにいかに近いかの評価指標であり、コスト関数はパラメータwとbがどのくらい正確に推論をできているかの評価指標である。
損失関数: l(y, t) = -(t*log*y + (1 - t)log(1 - y))
コスト関数: J(w, b) = 1/m*Σi=1:m*l(y(i), t(i)) = -1/m*Σi=1:m[t(i)log*y(i) + (1 - t(i))*log(1 - y(i))]
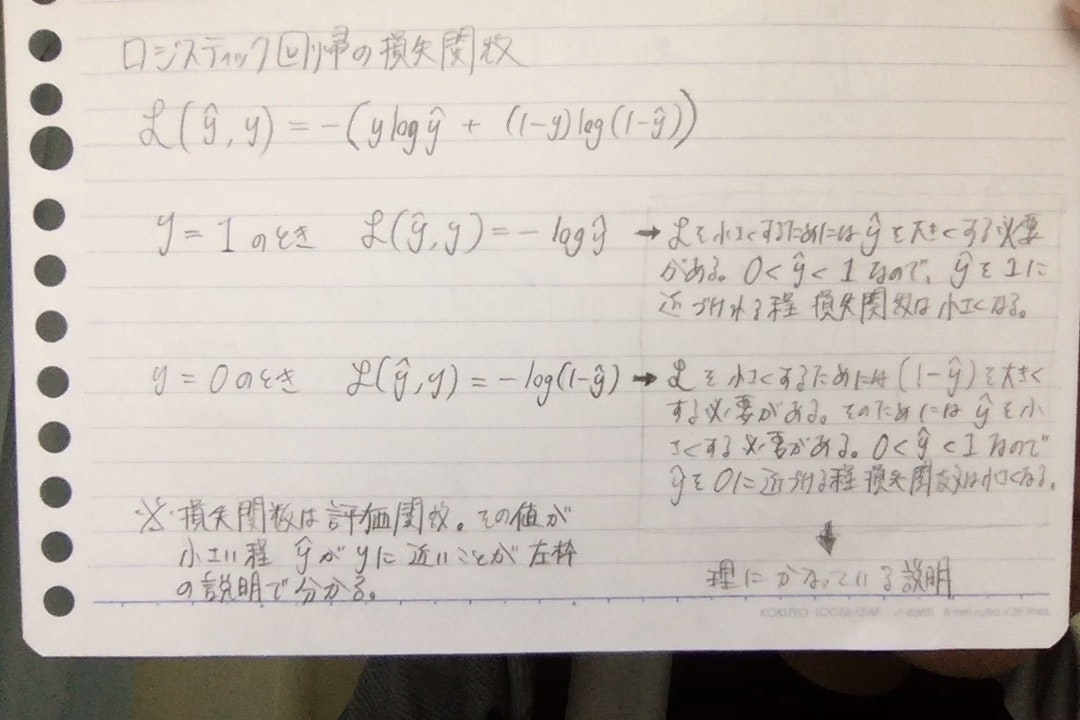
最急降下法

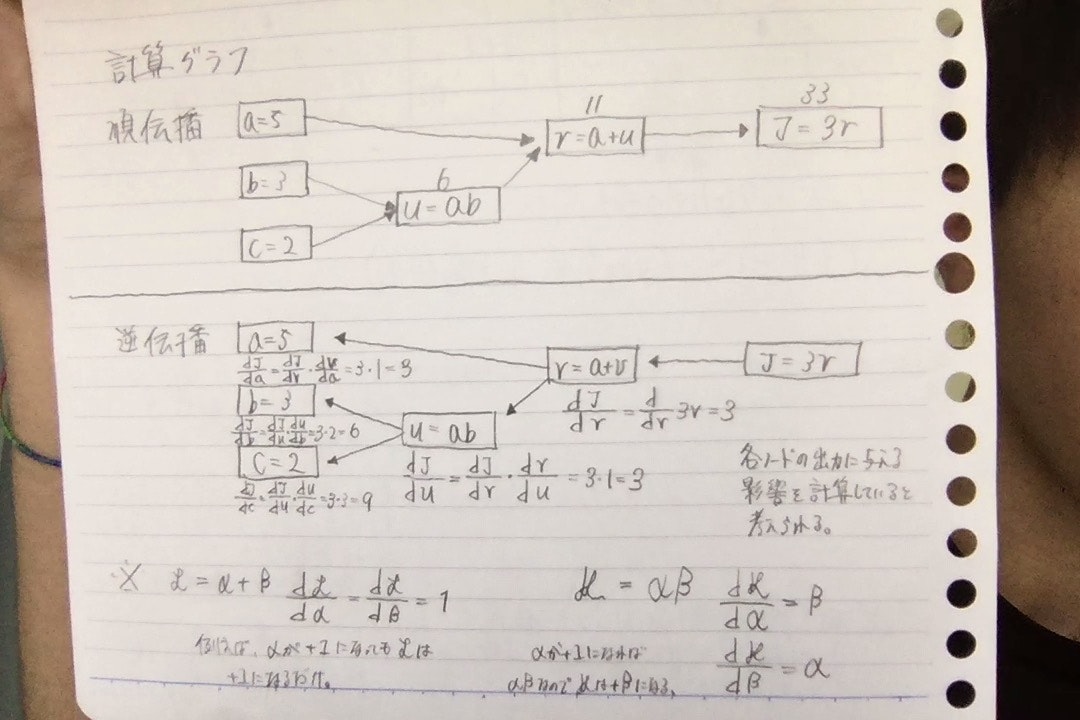
計算グラフ
ロジスティック回帰やニューラルネットワークの順伝播や逆伝播(微分)の計算を分かりやすく表現できる。
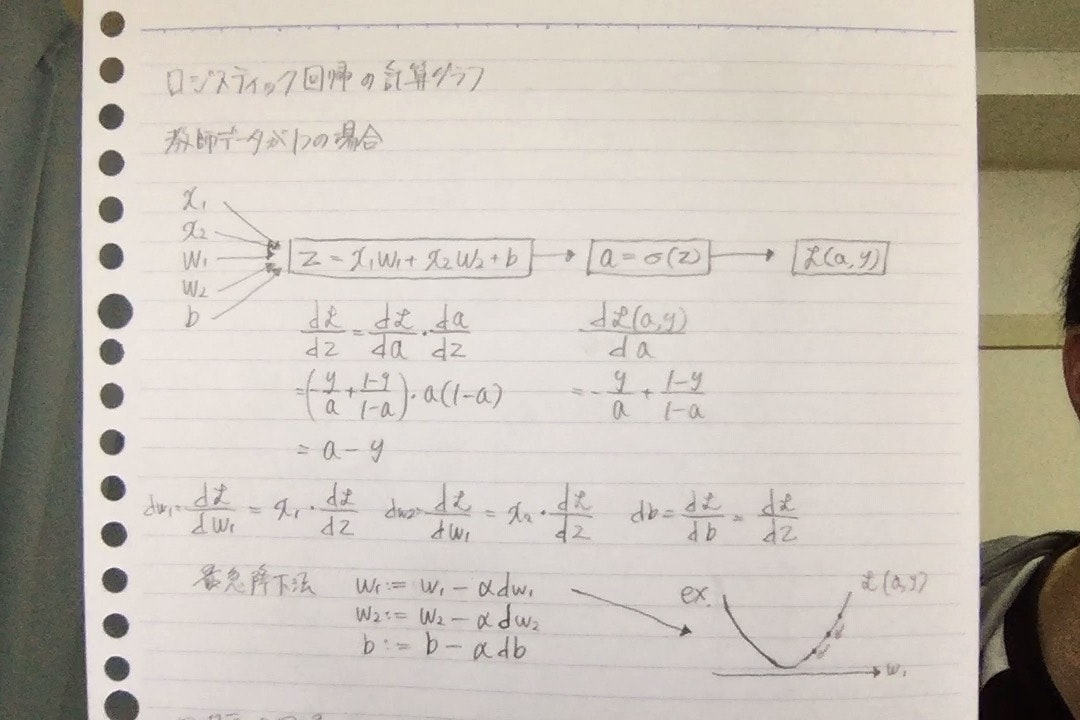
ロジスティック回帰の計算グラフ
Python・NumPyのコーディングにおける注意
(1, 5)のベクトルを作るときにnp.randm.randn(5)にするとランク1配列が生まれ、これはベクトルではない。
ランク1配列は転置や内積といったベクトル・行列の基本的な操作が出来ないので使わない。
ベクトルを作るには、np.random.randn(1,5)かnp.random.randn(5,1)
学習のデータに対する前処理(ロジスティック回帰)
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()でデータをインポート
train_set_x_origとtest_set_x_origを1枚の画像をベクトルとして表現した行列に整形する。
train_set_x_flatter = train_set_x_orig.reshape(train_set_x_orig.sape[0], -1).T-
train_set_x_flatterとtest_set_x_flatterの各行の要素を/255にして標準化。
train_set_x = train_set_x_flatter/255.ロジスティック回帰 m個の教師データでの順伝播

ロジスティック回帰 for文とベクトル計算の比較

Coursera Deep Learning👉 https://www.coursera.org/specializations/deep-learning