はじめに/参加コンペ概要
2023年5月11日 ~ 2023年8月10日にわたって行われた、ICR - Identifying Age-Related Conditionsに参加したので、その振り返り記事です。
結果は3,400/6,400位ほどでなかなか上手く結果を出せませんでした。
ざっくりコンペ概要
- カラム名がマスクされた健康状態に関するデータから、加齢に関する疾病と診断されるかどうかを予測するタスク
- 学習データが約600行しか用意されておらず、目的変数の比率は5:1の不均衡データ
- 評価指標はbalanced logloss
- 後ほど詳細記述
医療系データは、疾病有りの状態のサンプルを回収することが難しく、その中で予測できないか、というものが本コンペのテーマだと思われる。
評価指標について
下記の通り定義されます。
$\text{Log Loss} = \frac{-\frac{1}{N_{0}} \sum_{i=1}^{N_{0}} y_{0 i} \log p_{0 i} - \frac {1}{N_{1}} \sum_{i=1}^{N_{1}} y_{1 i} \log p_{1 i} } { 2 }$
純粋にloglossをクラス比率に基づいて、加重平均を取った評価指標となっている。特徴としては、誤った予測を「自信を持って」すればするほど大きなペナルティを与えられるということである。1のラベルに対して、0.3という予測を返したときと、0という予測を返したときでは、後者が大きく評価が悪くなる指標です。
ためしたこと
基本的に効きませんでした。
Down Sampling
疾病診断なしラベル(=0)が多かったため、1:1になるように0ラベルをダウンサンプリングしました。その結果学習に使用できるデータが600から200まで減少し、学習できるデータ数の影響からか精度は悪化しました。
K-meansラベルごとの集約特徴量の追加
K-Meansによって、クラスターごとにわけ、その状態で、各クラスターの集約特徴量を追加しました。一方で、閾値以上の相関による削減や、決定木モデルのFeature Importanceによる特徴削減において、追加された集約特徴量はほぼ全て削除されたため、ほとんど効きませんでした。
sample code
# 集約特徴量の追加
agg_cols = ["min", "max", "mean", "std"]
cat_cols = ["cluster_label"]
for col in cat_cols:
grp_df = df.groupby(col)[num_cols].agg(agg_cols)
grp_df.columns = [f"{col}_" + "_".join(c) for c in grp_df.columns]
df = df.merge(grp_df, on=col, how="left")
test_df = test_df.merge(grp_df, on=col, how="left")
序盤に試すテーブルデータの特徴量エンジニアリングを参考にさせていただきました。
カスタムCVの実装
実装したファイルはmodel_selection.pyです。(友人実装)
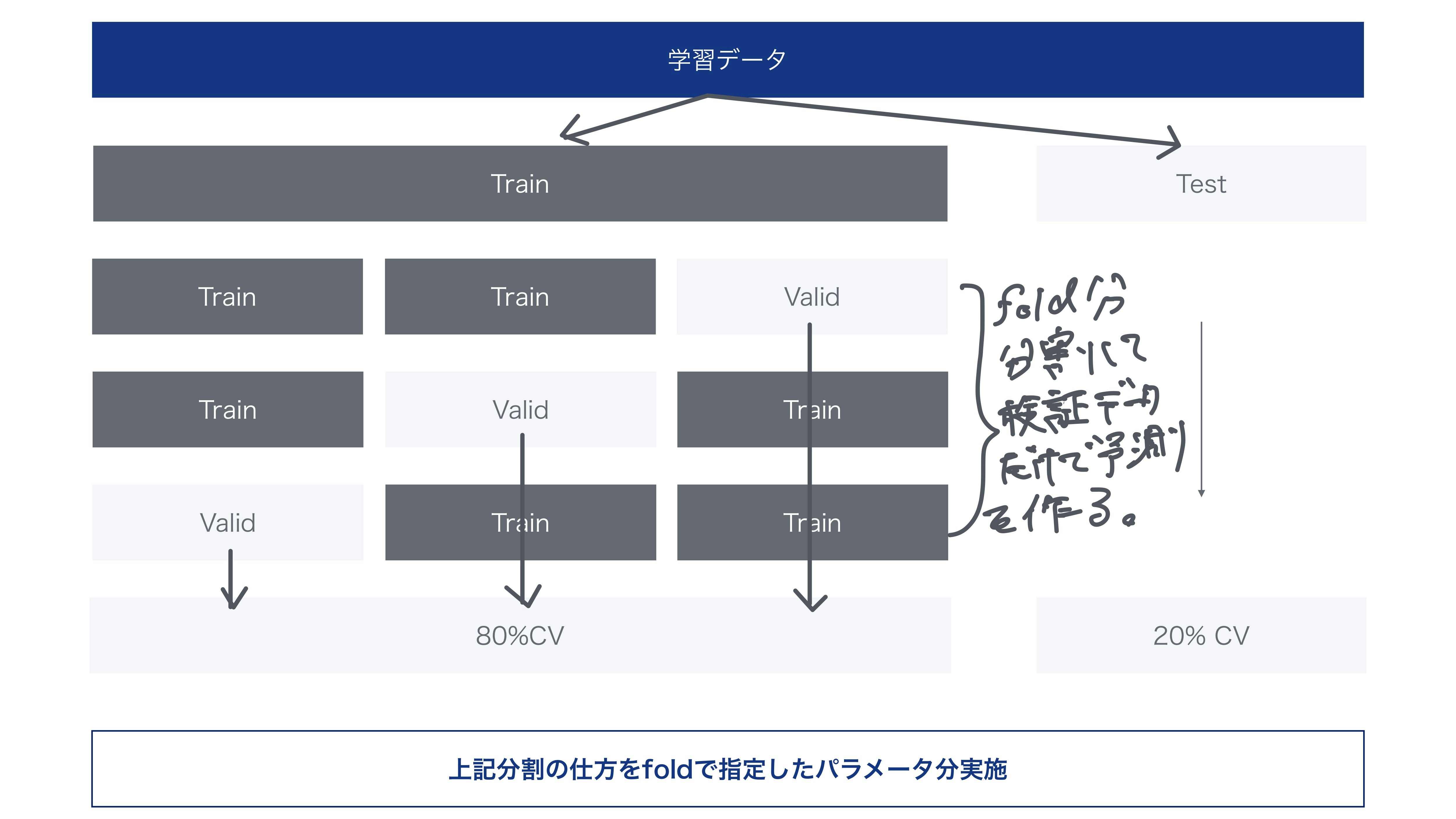
少数データなため、バリデーションを実施したときのばらつきが大きく、train, validのスコアに対して、testのスコアがどの程度になるのかを検証する目的で実装しました。アーキテクチャは下記画像の通りです。
予測分布の可視化とpostprocessの検証
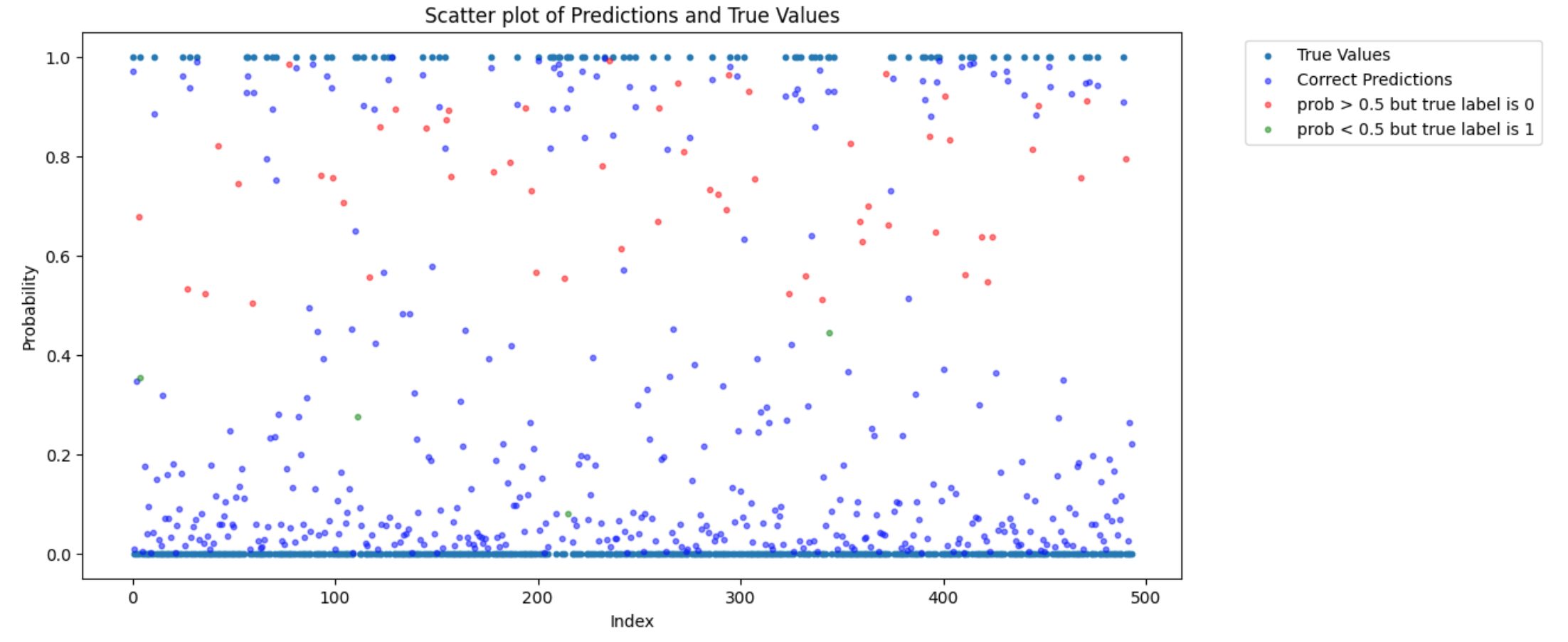
下記画像のような形で、予測分布を可視化し、一定の確率値以上or以下で閾値を定め、すべて1or0にするといったpostprocessを検証しました。
この際に、主に上のCVアーキテクチャにおける20% CVの分布を見て、閾値を定めるべきかについて友人と議論しました。結果として、postprocessは採択しなかったのですが、上位の解法を見る限り、どのコードもpostprocessを採用しておらず、この判断ができたことはポジティブに捉えています。(コンペ中、postprocessをかけてlbにoverfitするコードが多く出回っており、本当に有効か検証するために苦労しました)
Issue#1 : 予測分布の可視化を行う
Issue#2 : アンサンブル手法の探索
sample code(友人実装)
def plot_predictions_distribution(true_values, predictions, title="pred_dist.png"):
fig, ax = plt.subplots(figsize=(12, 6))
indexes = np.arange(len(predictions)) # Create an array of index values
true_values = np.array(true_values) # Ensure true_values is an array for element-wise comparison
predictions = np.array(predictions) # Ensure predictions is an array for element-wise comparison
# Plot all predictions and true values
ax.scatter(indexes, true_values, label='True Values', s=10)
# Create a mask for incorrect predictions where prob > 0.5 but true label is 0
incorrect_mask_1 = (predictions > 0.5) & (true_values == 0)
# Create a mask for incorrect predictions where prob < 0.5 but true label is 1
incorrect_mask_2 = (predictions < 0.5) & (true_values == 1)
# Create a mask for correct predictions
correct_mask = (predictions >= 0.5) & (true_values == 1) | (predictions < 0.5) & (true_values == 0)
# Plot the predictions using the masks for coloring
ax.scatter(indexes[correct_mask], predictions[correct_mask], label='Correct Predictions', alpha=0.5, s=10, color='blue')
ax.scatter(indexes[incorrect_mask_1], predictions[incorrect_mask_1], label='prob > 0.5 but true label is 0', alpha=0.5, s=10, color='red')
ax.scatter(indexes[incorrect_mask_2], predictions[incorrect_mask_2], label='prob < 0.5 but true label is 1', alpha=0.5, s=10, color='green')
ax.set_xlabel('Index')
ax.set_ylabel('Probability')
plt.title('Scatter plot of Predictions and True Values')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.savefig(title, bbox_inches='tight')
plt.close(fig)
stacking, blendingでのアンサンブルの実施
アンサンブルを実施することにより、一般的にはロバストな予測値を得ることができると言われています。精度向上に加え、ロバストな予測値を得る目的で実装しました。
1層目はLGB, XGB, CAT, Tab-PFNで実装し、2層目でblendingやlogistic回帰, シンプルなNN, LGBを試しました。
code : exp008-stacking-v2.py
上位解法を見た学び
hard to predict labelを追加し、cvの分割に利用する
・予測値が0.8以上, 正解ラベルが0のもの
・予測値が0.2以下, 正解ラベルが1のもの
上記条件に当てはまるものに、hard to predictラベルを付与し、k-foldのstrategyに組み込んでいました。今回の評価指標において、「自信を持って外した予測」の罰則が大きいため、そこに対して何らかの打ち手を打てているところが勉強になりました。
hard to predictをPseudo-Labelingして半教師あり学習を実施するなど、hard to predictをラベリングすることは他の打ち手にもつながりそうで、今後コンペに参加するときは選択肢に加えられればと思います。
参考 : How on Earth did I win this competetion?
最後に
Our Work Directory
友人と参加したため、友人のgithubディレクトリです。
初めてkaggleのコンペを走り切りました。(ダブルワークしながらだったので、激コミットはできませんでしたが...)
Masterに憧れを抱いてるので、Masterになるまでは頑張りたい所存です。。。