初めに
SIGNATEの「第2回 金融データ活用チャレンジ」にチームで参加しました。
結果は104位に終わりました。個人的にはシルバーやゴールドを目指して参加していたので、すごく悔しい結果でした。
以下コンペの概要です。
▼課題
今回は企業向けローンの返済可否予測というテーマを通して、ローンに関連したデータを基に、企業が返済不能になるかどうかの予測に挑戦して頂きます。このデータを活用することで、どの業種や地域が成長の機会を持っているか、あるいはどのような要因がビジネスの成功に影響を与えるかなど、金融機関は効果的な企業支援の戦略を立てることができます。
今回提供するデータは、米国小企業庁(U.S. Small Business Administration、略称SBA)によるデータをもとに生成した人工的なもの(※)で、SBAのローン保証を受けたスタートアップや小企業に関する情報が含まれています。
※人工的なデータとは、実データと同じ構造、カラム数、型を有するものの、AIのアルゴリズムによって作成された全く新しい架空のデータのことをいう。
参考 : 第2回 金融データ活用チャレンジ
EDAとバリデーションアーキテクチャの決定
コンペ序盤では、EDAによるデータ理解に取り組みました。
今回のコンペでは、あまり活発にEDA結果を共有し合うような動きはあまりなく(見落としているだけかもしれませんが...)、バリデーションのアーキテクチャを設定するための情報, 特徴量を作成するための情報を可視化するためにEDAを実施しました。
大まかに数値データ, カテゴリカルデータ, 都市データの3つに大別してEDAを進めました。
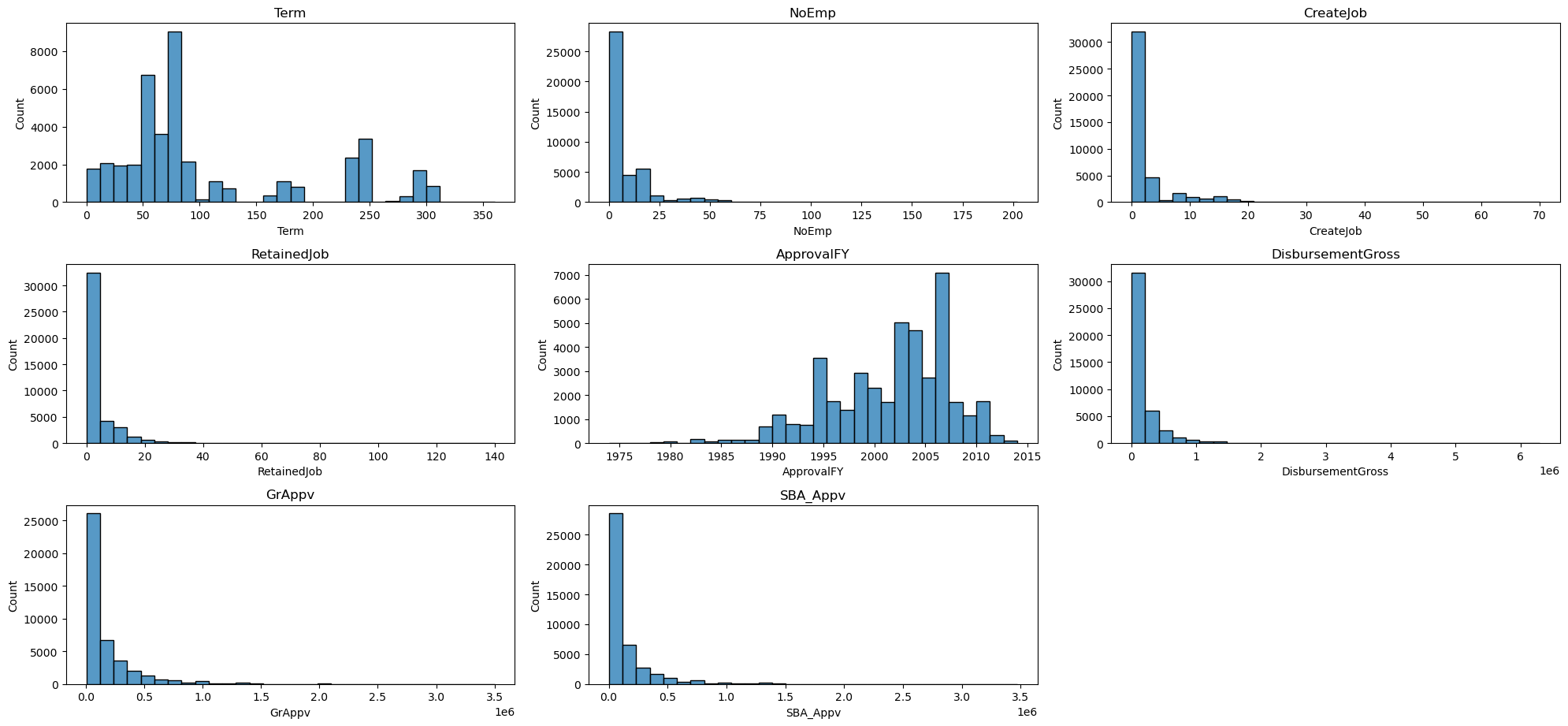
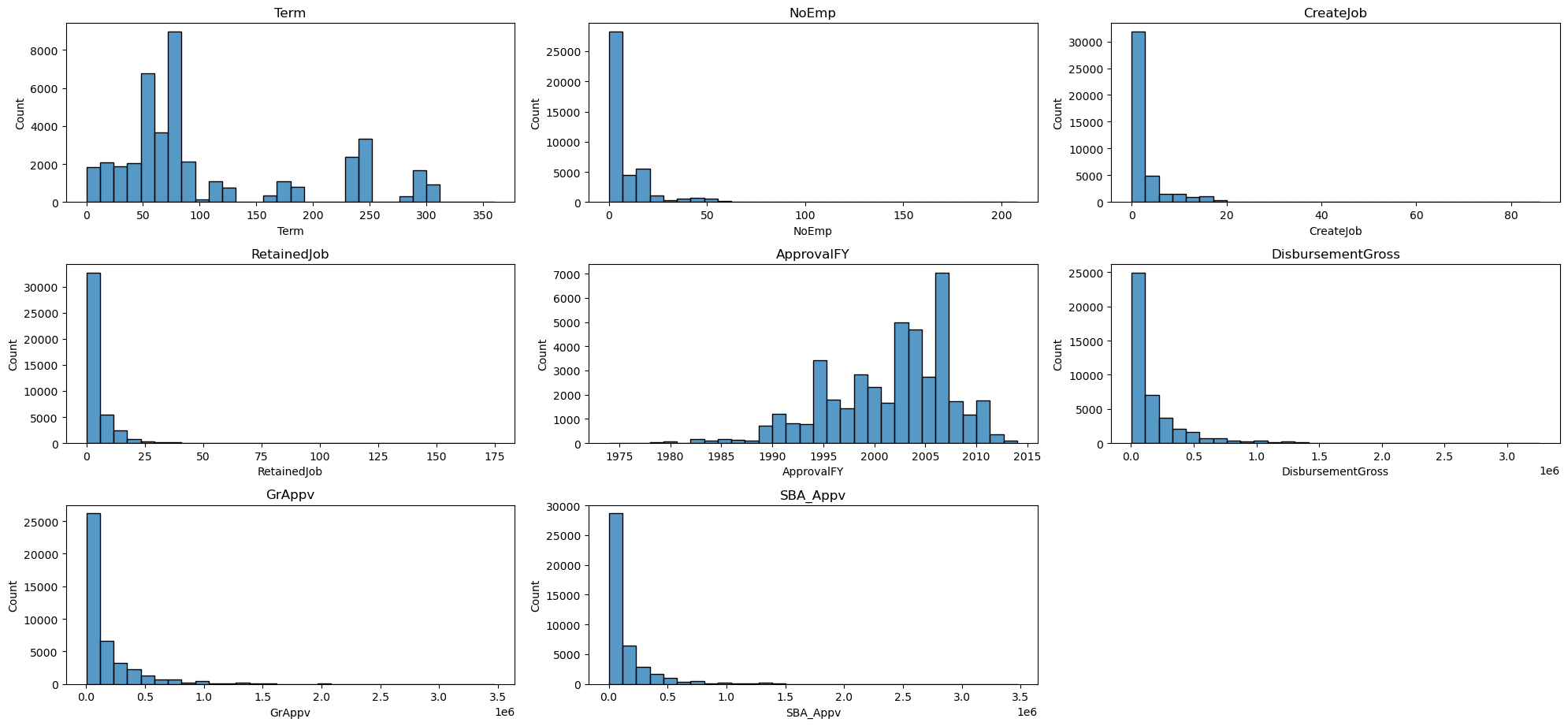
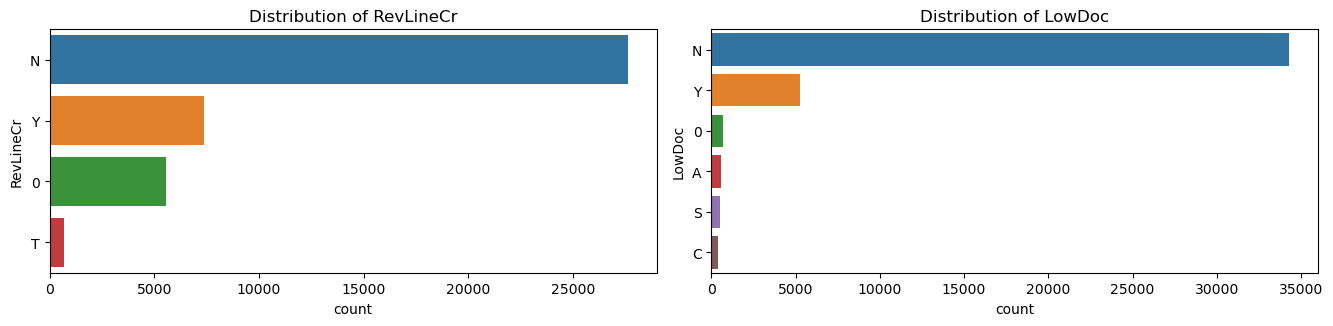
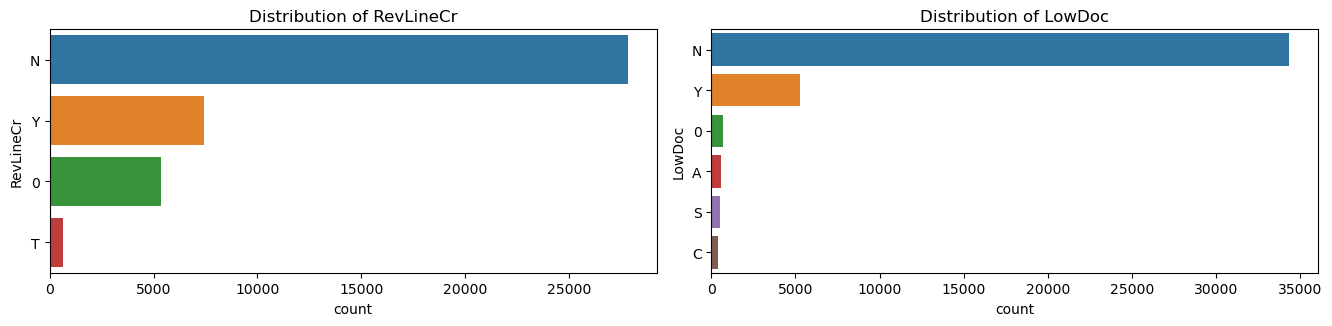
結論としては、数値データ、カテゴリカルデータ、都市データの3つの区分とも、train, testでの分布がかなり似ており、バリデーションスコアを向上させる打ち手はtestデータに対しても有効であると結論づけました。
数値データの可視化
数値データは以下の可視化により、train, testでの分布がほぼ一致していることがわかりました。
▽学習用データの分布の一覧
▽テストデータの分布の一覧
カテゴリカルデータの可視化
カテゴリカルデータも数値データと同様に各クラスの分布はほとんど同じでした。
▽学習用データの分布の一覧
▽テストデータの分布の一覧
都市データの可視化
以下各都市を表すデータの可視化です。
BankStateのカラムでは、testのみに出現する都市が1件、Cityのカラムでは、それぞれに500強のデータセット固有の都市が出現しています。
ここからは自分の後悔なのですが、この中のカラムでもCityのカラムは特に予測に寄与したカラムでした。提出した段階だとtrain, testでconcatしてラベリングした前処理しかできなかったので、他の方同様、trainのみに出現する都市を"train_only", testにのみ出現する年を"test_only"のようにラベリングするなど、Cityの前処理をより工夫できればよかったと反省しています。
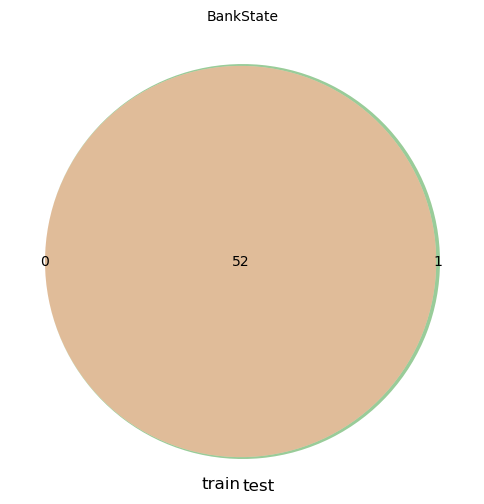
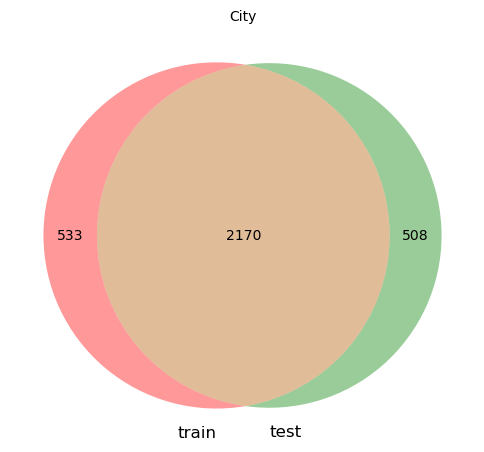
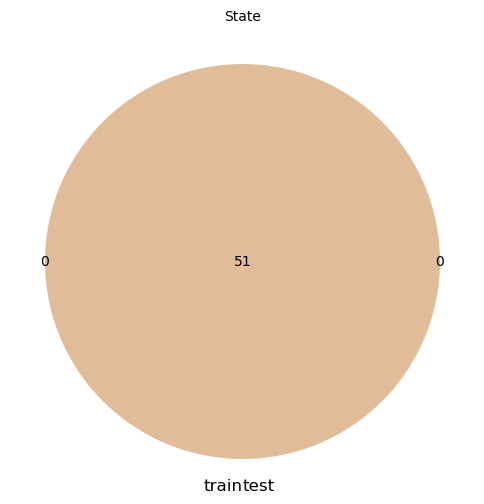
バリデーションアーキテクチャの設定
結論として、バリデーションとしては、Stratified K-Foldを採用しました。検討したアーキテクチャと、棄却理由は以下の通りとなります。
| バリデーション候補 | アーキテクチャ | 採用 / 棄却理由 |
|---|---|---|
| Stratified K-Fold | 目的変数が不均衡なため、各foldの目的変数の分布を均等にするため、Stratified K-Foldを採用しました。 | 日付を表すデータが含まれており、時系列データとしての取り扱いも検討しましたが、今回のコンペは2月のA社, 3月のA社といったように、同一の企業が異なる時系列としてデータとして現れることがないため、時系列を考慮せずにバリデーションを設計してもリークは起きないと判断して、目的変数の分布だけを考慮するシンプルなバリデーションとしました。 |
| Stratified Group K-Fold | 目的変数の分布を各foldで同じにしつつ、同じ月の時系列データをtrain or testにしか入れないアーキテクチャ(例えばカラムAで2023/01のデータはtrainにしか入れない、といったこと)を候補としました。 | 異なる時系列に同一の会社が出現せず、Stratified K-FoldでのCVスコアとLBが近い値になることもあり、不採用としました。 |
| Hold Out | 今回のコンペを時系列データとして捉える場合に候補となったアーキテクチャです。時系列ごとにデータを並べ、最新のデータおよそ2割を検証用データとし、残りのデータで学習するアーキテクチャを候補としました。 | 異なる時系列に同一の会社が出現せず、Stratified K-FoldでのCVスコアとLBが近い値になることもあり、不採用としました。 |
ここからは感想になりますが、今回採用したバリデーションのアーキテクチャにて、提出して観測できた範囲では、CVが最も高かった予測結果が、Private Scoreにおいて最も高くなっていました。最終サブミットは、Public Scoreが最も高いものと、アンサンブルにおいて複数のSeed値で平均化させたものの2つを提出したため、最も高いスコアを選択することができず、しかも一番CVが高いものを見逃してしまうというかなり悔しい結果になりました。
可視化用サンプルコード
# ライブラリのインポート
import os
import random
from tqdm.auto import tqdm
from pathlib import Path
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pathlib import Path
import seaborn as sns
from matplotlib_venn import venn2
# configの設定
class config:
INPUT_DIR = Path("../Inputs")
OUTPUT_DIR = Path("../Outputs")
SEED = 42
# seed値の固定
def fix_seed(seed):
# random
#random.seed(seed)
# NumPy
np.random.seed(seed)
# PyTorch
# torch.manual_seed(seed)
# torch.cuda.manual_seed_all(seed)
# torch.backends.cudnn.deterministic = True
# Tensorflow
#tf.random.set_seed(seed)
fix_seed(config.SEED)
# Preprocess
# 金額を表す列を数値型に変換するための関数
def convert_currency_to_float(df, currency_cols):
return df[currency_cols].replace('[\$,]', '', regex=True).astype(float)
# 日付を表すカラムを日付型に変換する関数
def convert_calender_to_date(df, date_cols):
for c in date_cols:
df[c] = pd.to_datetime(df[c])
return df
# Sectorをカテゴリーのデータ型に変換
def convert_catcols_to_category(df, cat_cols):
for c in cat_cols:
df[c] = df[c].astype("category")
return df
# クレンジング対象のカラムの定義
CLEANSING_COLUMNS = ['DisbursementGross', 'GrAppv', 'SBA_Appv']
# categoryカラムの定義
CAT_COLS = ["City", "State", "BankState", "Sector", "NewExist", "FranchiseCode", "UrbanRural", "RevLineCr", "LowDoc"]
# データの読み込み
train = pd.read_csv(config.INPUT_DIR / 'train.csv', index_col=0)
test = pd.read_csv(config.INPUT_DIR / 'test.csv', index_col=0)
# 通貨の形式での入力を数値型に変換
train[CLEANSING_COLUMNS] = convert_currency_to_float(train, CLEANSING_COLUMNS)
test[CLEANSING_COLUMNS] = convert_currency_to_float(test, CLEANSING_COLUMNS)
# 日付データカラムを日付型に変換
date_columns = [col for col in train.columns if 'Date' in col]
train = convert_calender_to_date(train, date_columns)
test = convert_calender_to_date(test, date_columns)
# Sectorをカテゴリーのデータ型に変換
train = convert_catcols_to_category(train, CAT_COLS)
test = convert_catcols_to_category(test, CAT_COLS)
## EDA
# 数値カラムのEDA
# 分布の可視化関数
def plot_numeric_dist(df, numeric_cols):
plt.figure(figsize=(20, 15))
for i, col in enumerate(numeric_cols):
plt.subplot(5, 3, i+1) # 5行3列のグリッドでプロット
sns.histplot(df[col], kde=False, bins=30)
plt.title(col)
plt.tight_layout()
plt.show()
# 数値カラムの抽出
numeric_columns = test.select_dtypes(include=['number']).columns
# trainデータの可視化
plot_numeric_dist(train, numeric_columns)
# testデータの可視化
plot_numeric_dist(test, numeric_columns)
# カテゴリカルデータのEDA
# 分布の可視化関数
def plot_categorical_dist(df, numeric_cols):
plt.figure(figsize=(20, 15))
for i, col in enumerate(numeric_cols):
plt.subplot(5, 3, i+1) # 5行3列のグリッドでプロット
sns.countplot(y=df[col], order = df[col].value_counts().index)
plt.title(f'Distribution of {col}')
plt.tight_layout()
plt.show()
# 文字列カラムの抽出
object_columns = ['RevLineCr', 'LowDoc']
plot_categorical_dist(train, object_columns)
plot_categorical_dist(test, object_columns)
# 都市カラムの可視化
# ベン図でどの程度歳の被りがあるか確認
def plot_venn_train_test(train, test, col):
"""trainとtestのベン図をplotする
"""
fig, ax = plt.subplots(figsize=(6,9))
plt.title(col, fontsize=10)
train_unique = train[col].unique()
test_unique = test[col].unique()
common_num = len(set(train_unique) & set(test_unique))
venn2(subsets=(len(train_unique)-common_num, len(test_unique)-common_num, common_num),set_labels=('train', 'test'))
# 都市のカラムの定義
city_cols = ["City", "State", "BankState"]
# 可視化の実行
for c in city_cols:
plot_venn_train_test(train, test, c)
baselineモデルの採用
baselineを作っていてどうしてもうまく学習が進まず、ユーザー名takaitoさんが公開してくださったbaselineをチームとして使用させていただきました。
参考 : 【FDUA】第二回 金融データ活用チャレンジの戦い方を考える
自作baselineでうまくいかなかったこと
自作のbaselineでは、LightGBMのシングルモデルを作成しました。
その際にパラメータとして、is_unbalancedをTrueにし、不均衡データにおけるlossの算出方法を調整しました。そうすると、何度やってもearly stoppingが3回目あたりの学習でストップしてしまい、学習がうまく進みませんでした。
また、当初LBの計算に不具合があり、何を出してもほとんどスコアが変わらなかったこともあり、自作でのbaselineに対して懐疑的になってしまい、そのタイミングで公開されたtakaitoさんのbaselineを使用させていただきました。
あたらめてコンペが終わった今、学習を回してみると、確かにearly stoppingは3 round前後で止まってしまいますが、全体的にみると1200roundほどの学習でlossが収束しており、試しにearly stopをかけずに1200round回してみるとうまく学習していました。
# LightGBMのパラメータ
params = {
'boosting_type': 'gbdt', # Gradient Boosting Decision Tree
'objective': 'binary', # 二値分類の場合(多クラスの場合は'multiclass')
'metric': 'binary_logloss', # 損失測定(多クラスの場合は'multi_logloss')
'learning_rate': 0.05,
'verbose': -1,
'is_unbalance': True,
}
scores = []
log_losses = []
mean_f1_scores = []
threshold = 0.5
for fold in range(N_SPLITS):
train_df = train[train['fold'] != fold]
valid_df = train[train['fold'] == fold]
X_train, y_train = train_df.drop([TARGET_COL, "fold"], axis=1), train_df[TARGET_COL]
X_valid, y_valid = valid_df.drop([TARGET_COL, "fold"], axis=1), valid_df[TARGET_COL]
# データセットをLightGBMの形式に変換
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid)
# モデルの訓練
model = lgb.train(
params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1200,
#callbacks=[
# lgb.early_stopping(stopping_rounds=1200, verbose=True), # early_stopping用コールバック関数
# lgb.log_evaluation(50)]
)
y_pred_proba = model.predict(X_valid)
y_pred = [1 if prob >= threshold else 0 for prob in y_pred_proba]
logloss = log_loss(y_valid, y_pred)
mean_f1 = f1_score(y_valid, y_pred, average='macro')
log_losses.append(logloss)
mean_f1_scores.append(mean_f1)
print(f"Fold: {fold}, log loss: {round(logloss, 5)}, Mean F1 Score: {round(mean_f1, 5)}")
print()
print("Log Loss")
print(log_losses)
print(np.mean(log_losses), np.std(log_losses))
print()
print("Mean F1 Score")
print(mean_f1_scores)
print("MEAN : ", np.mean(mean_f1_scores), "STD : ", np.std(mean_f1_scores))
>>>
Fold: 0, log loss: 5.16954, Mean F1 Score: 0.64873
Fold: 1, log loss: 5.36719, Mean F1 Score: 0.63109
Fold: 2, log loss: 5.19339, Mean F1 Score: 0.64291
Fold: 3, log loss: 5.21093, Mean F1 Score: 0.6403
Log Loss
[5.169539774160038, 5.367188625116717, 5.193393945827223, 5.2109253055938085]
MEAN : 5.235261912674447 STD : 0.07757134464293217
Mean F1 Score
[0.6487333748948876, 0.6310896687435454, 0.6429061455591146, 0.640297194562607]
MEAN : 0.6407565959400388 STD : 0.006362194926031358
特徴量の追加と選択
主に以下の特徴量を作成しました。
- 基本的な特徴量の追加
- 集約特徴量の追加
- 外部データの追加
- k-meansラベルの追加
- hard to predictの追加
基本的な特徴量の追加
col A + col Bのようなシンプルな特徴量の追加です。
- SBA保証率の追加 : SBA_Appv / GrAppv
- 月額の返済額 : GrAppv / Term
など、純粋に仮説として追加すると精度が上がりそうなものを追加していきました。
また、今回は産業分類コードが特徴量に含まれていたので、各産業分類の英語でのマスタをベクトル化し、特徴量に追加しました。意図としては、例えば、「不動産、賃貸・リース」というカテゴリと「金融、保険」、「建設業」はそれぞれマスタ上では異なるものとして認識されていますが、この3つだと、「不動産、賃貸・リース」と「金融、保険」似ているが、「建設業」はちょっとこの2つとは違うよね、ということをモデル側に認識させたかったことが挙げられます。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentence_embeddings = model.encode(sector_master["Description"])
モデル的には本来、「建設業」のような形で入力されているので、word2vecなど、単語単位での分散表現を取得するものが適切かなと思いながら、sentence transformerが一番実装が簡単だったので、このモデルにしました。(どうしても時間が取りきれず...)
集約特徴量の追加
colum2131さんの記事を参考に、集約特徴量を追加しました。
集約特徴量は、量的変数と質的変数の組み合わせによって特徴量を追加する手法です。
序盤はとりあえず特徴量を増やして、後で選択すればいいや、と思っていたので、とにかく各カテゴリカル変数ごとの集約特徴量を追加しました。
今回のコンペのルールでは、train, testをconcatして全データから集約特徴量を作成することは禁止されていたので、trainデータのみ集約し、それぞれtrain, testに各カテゴリカル変数をKeyに結合する処理を実装しました。
def add_aggrigation_feats(train, test, num_cols, cat_cols, agg_cols=['min', 'max', 'mean', 'std']):
for col in cat_cols:
# trainのみで集約することに気をつける
grp_df = train.groupby(col)[num_cols].agg(agg_cols)
grp_df.columns = [f'{col}_' + '_'.join(c) for c in grp_df.columns]
train = train.merge(grp_df, on=col, how='left')
test = test.merge(grp_df, on=col, how='left')
return train, test
# 集約特徴量の追加
train_df, test_df = add_aggrigation_feats(train_df, test_df, num_feats_agg, default_categorical_features)
外部データの使用
都市を表すカラムに対して、緯度経度を追加しました。
ここの部分はチームメンバーが実装してくれました。
K-Meansラベルの追加
K-meansのラベルは、都市の緯度経度に対してラベリングづけしました。
今回のコンペは、feature importance上では、Cityカラムが最も予測に寄与していたので、緯度経度のデータを使用して、K-Meansを用いて5, 10, 15のクラスに分類しました。
ただこれは特に予測には寄与せず、スコアを上げることはできませんでした。
Hard to Predictラベルの追加
1つくらいおしゃれな手法を実装したいなと思い、こちらの追加にチャレンジしてみました。
やったこととしては、以下の2つに該当する行に対しては、1のラベルを、そうでない行に対しては0を立てるカラムを作成し、そのカラムを目的変数として、予測を行い、train, testともに予測値を特徴量とする手法を追加しました。
- 目的変数の予測として、0.8以上の予測値を出力しているにも関わらず、正解ラベルが0の行
- 目的変数の予測として、0.2以下の予測値を出力しているにも関わらず、正解ラベルが1の行
# htpラベルの算出
htp_label = np.where((train_df["pred_prob"] >= 0.8) & (train_df[CFG.target_col] == 0), 1, 0)
# htpラベルの算出
htp_label_2 = np.where((train_df["pred_prob"] <= 0.2) & (train_df[CFG.target_col] == 1), 1, 0)
# 1が立ったフラグの数を確認
print(np.sum(htp_label + htp_label_2))
>>> 2673
追加により、手元のCVスコアが0.682768から0.683138まで上昇し、Feature Importanceでも3番目に来ていました。
参考 : ICR - Identifying Age-Related Conditions
特徴量の選択
特徴量の選択は単純に、Feature Importanceを可視化し、上位X個を採用しました。
50, 100, 150, ...と50個単位で試していき、精度を比較しました。私たちのチームでは、150個の特徴量を採用しました。
EDAにて、train, testの分布がかなり近い状態であると確認が取れたので、validationスコアに寄与する特徴量は、そのままtestの予測にも寄与すると捉え、シンプルですがFeature Importanceの上位から50個区切りで試してみる手法を選択しました。
moreなポイントは、150個の特徴量の中には、sentence transformerで取得したembeddingのうち、一部の次元だけが含まれる形となっていることです。本来ある一部の次元に意味があるというよりは、全部の次元が揃ってある意味を持つベクトルであると理解しているので、ここについては時間があれば、次元圧縮などうまく処理できていればなと思います。
特徴量の選択は、チームメンバーが実装してくれました。
Stackingの実装
1層目, 2層目のアーキテクチャは以下の通りです。
- 1層目 : Catboost, LightGBM, Tabnetの3モデルにて予測
- Tabnetはチームメンバーが実装してくれました。
- 2層目 : Random Forest, Catboost, XGBoost
- 各モデルで1層目の予測結果を特徴量として予測しました
- 最終的な予測は2層目の3つのモデルを重み付けしてブレンドして提出しています
最後に
様々なトラブルが発生する中、最後まで対応してくださった運営の方々、本当にありがとうございました。個人的には一番の学びとしてちゃんとtrust cvをする、を身をもって体験できてよかったです。(言うは易しですが、人間高いLBを見るとそれを出したくなってしまいますよね。。。)
仮説を持ってCVアーキテクチャを作るということを改めて意識して、CV自体はうまく作れていたことは自信を持ちつつ、今後はしっかりと自分のCVを信じ切れるような分析をしていきたいです。
また、忙しい中チームを組んで一緒に取り組めたチームメンバーにも感謝を伝えたいです。
ありがとうございました。