通常,HLS(High Level Synthesis)を使うときには,画像処理やフィルタなどライブラリで用意されているような処理を対象にすることが多いかと思います.しかし,ここでは趣を変えて,通常,HDL(Hardware Description Language)で使って書かれるような内容を,HLSを使って書いてみたいと思います.具体的には,7つくらいの機械命令を持つCPUを記述してみました.
想定する読者と環境
ここではCPUの命令セットアーキテクチャについての情報があれば,だいたいCPUはどんな構造になるのかが分かる程度の知識を前提として記載しています.大学などのコンピュータアーキテクチャの講義で,単一サイクルプロセッサの動作やアセンブリプログラミングなどを習ったことがあれば,おそらく理解出来ると思います.
プログラミング言語にはC言語(正確にはC++)を用いています.これはIntel社が提供するIntel HLS Compilerを用いているためです.執筆時に動作確認したHLSのバージョンはVersion 21.1.0 Build 173.3となります.
HLSに関する知識はなくても良いような内容にしており,C言語の知識があれば,十分内容が理解できるとお思います.
概要(設計するCPUの仕様)
ここでは以下の仕様を満たすCPUを設計していきます.
機械命令フォーマット
機械命令は40bit長とし,I形式とR形式の2種類のフォーマットとしています.
opフィールドやrsフィールドなどは3bitや5bitなどに幅を短くすることもできますが,
記述を容易にするためにC言語で標準で用意されている型のビット幅に合わせて,
このように設定しています.
I形式
| フィールド名 | op | rs | rt | imm |
|---|---|---|---|---|
| ビット幅 | 8bit | 8bit | 8bit | 16bit |
| ビットの位置 | [39:32] | [31:24] | [23:16] | [15:0] |
R形式
| フィールド名 | op | rs | rt | rd | 未使用 |
|---|---|---|---|---|---|
| ビット幅 | 8bit | 8bit | 8bit | 8bit | 8bit |
| ビットの位置 | [39:32] | [31:24] | [23:16] | [15:8] | [7:0] |
命令一覧
| 命令 | op | 形式 | アセンブリ命令の記述方法 | 説明 |
|---|---|---|---|---|
| lw | 0x00 | I形式 | lw rt, imm(rs) | R[rs] = M[ R[rt] + imm ] |
| sw | 0x01 | I形式 | sw rt, imm(rs) | M[ R[rt] + imm ] = R[rs] |
| addi | 0x02 | I形式 | add rt, rs, imm | R[rt] = R[rs] + imm |
| beq | 0x04 | I形式 | beq rs, rt, imm | if( R[rs] == R[rt] ) then PC = PC + 4 + imm |
| add | 0x22 | R形式 | add rd, rs, rt | R[rd] = R[rs] + R[rt] |
| slt | 0x28 | R形式 | sll rd, rs, rt | R[rd] = ( R[rs] < R[rt] ) ? 1 : 0 |
| hlt | 0x0F | I形式 | hlt | CPUの実行を停止する |
lw命令の動作
- 命令のrsフィールドを参照して,レジスタファイルからrs番目のレジスタの内容を読み出す.(読み出した値をalu_aとする)
- alu_aと命令のimmフィールドの値を,ALUを使用して足す(足した結果をalu_resultとする)
- alu_resultをメモリアドレスとしてデータメモリから値を読み出す(読み出した結果をmem_read_dataとする)
- mem_read_dataをレジスタファイルのrt番目に格納する
sw命令の動作
- 命令のrsフィールドとrtフィールドの値を参照して,レジスタファイルからrs番目,rt番目のレジスタの内容を読み出す.(読み出した値をr_rs, r_rtとする)
- r_rsと命令のimmフィールドの値を,ALUを使用して足す(足した結果をalu_resultとする)
- データメモリのアドレスalu_result番地に,r_rtの値を書き込む
addi命令の動作
- 命令のrsフィールドを参照して,レジスタファイルからrs番目のレジスタの内容を読み出す.(読み出した値をalu_aとする)
- alu_aと命令のimmフィールドの値を,ALUを使用して足す(足した結果をalu_resultとする)
- alu_resultをレジスタのrt番目に格納する.
beq命令の動作
- 命令のrsフィールドとrtフィールドの値を参照して,レジスタファイルからrs番目,rt番目のレジスタの内容を読み出す.(読み出した値をr_rs, r_rtとする)
- PC(プログラムカウンタ)に+4した値をpc_nextとする.
- pc_nextと命令のimmフィールドの値を足す(足した結果をblanch_addressとする)
- r_rs - r_rtをALUを使って計算し,zフラグの情報をz_flagとする.
- z_flagの値が1であれば,PCにblanch_addressの値をセットし,z_flagの値が0であれば,PCにpc_nextの値をセットする
add命令の動作
- 命令のrsフィールドとrtフィールドの値を参照して,レジスタファイルからrs番目,rt番目のレジスタの内容を読み出す.(読み出した値をr_rs, r_rtとする)
- ALUを使用して,r_rs + r_rtを計算し,その結果をalu_resultとする
- レジスタファイルのrd番目に,alu_resultの値を保存する
slt命令の動作
- 命令のrsフィールドとrtフィールドの値を参照して,レジスタファイルからrs番目,rt番目のレジスタの内容を読み出す.(読み出した値をr_rs, r_rtとする)
- ALUを使用して,r_rs, r_rtを入力とするSLT演算をし,その結果をalu_resultとする
- レジスタファイルのrd番目に,alu_resultの値を保存する
hlt命令
- CPUの実行を停止する.
レジスタ一覧
| レジスタ番号 | 別名 | 説明 |
|---|---|---|
| $0 | $zero | 常に0(書き込み不可能) |
| $1〜$7 | 予約済レジスタ | |
| $8〜$15 | $t0〜$t7 | 一次的なデータの保存用レジスタ |
| $16〜$23 | $s0〜$s7 | 長期的なデータの保存用レジスタ |
| $24, $25 | $t8, $t9 | 一次的なデータの保存用レジスタ |
| $26, $27 | 予約済レジスタ | |
| $28 | $gp | グローバルポインタ |
| $29〜$31 | 予約済レジスタ |
メモリの仕様
データメモリと命令メモリでそれぞれ独立したアドレス空間を持つ.
- データメモリ
- int型(32bit)のデータが65536(2^16)個保存できるメモリとする.
- 1つの番地に1つのint型データを格納できる.つまり,連続するint型のデータは1000番地, 1001番地と保存していく.
- 命令メモリ
- INST型(40bit)のデータが65536(2^16)個保存できるメモリとする.
- CPUは命令メモリの0番地の命令から順番に実行していくとする
- 1つの番地に1つの命令(INST型データ)を格納できる.つまり,連続する命令は0番地,1番地と保存していく.
実行するアセンブリプログラム
CPUで実行するプログラムは,データメモリの1000番地と1001番地に格納された値を
かけ算し,結果を1002番地に保存するプログラムとする.
かけ算のアルゴリズムは,1000番地の値を1001番地に格納された回数だけ
足し算するという単純なアルゴリズムを採用している.
以下に,具体的なアセンブリプログラムを示す.
lw $16, 0($28) # 16番レジスタに1つ目の値をロード
lw $17, 1($28) # 17番レジスタに1つ目の値をロード
addi $18, $0, 0 # 18番レジスタを0を格納
addi $19, $0, 0 # 19番レジスタを0を格納
LOOP: slt $8, $19, $17 # (19番レジスタの値<17番レジスタの値)であれば,8番レジスタに1が入る
#(そうでないなら,8番レジスタに0が入る)
beq $8, $0, DONE # 8番レジスタの値が0と一致したら,DONEに分岐する
add $18, $18, $16 # 18番レジスタの値と16番レジスタの値を足して,18番レジスタに保存する
addi $19, $19, 1 # 19番レジスタの値を1つ増やす
beq $0, $0, LOOP # LOOPに分岐する
DONE: sw $18, 2($28) # 18番レジスタの値をストアする
hlt
ここで,28番レジスタには1000という値が事前に格納されていると仮定している.
このアセンブリプログラム上で1000を代入する命令を最初に挿入しても良いが,28番レジスタはメモリ上のデータ領域の先頭を示すベースレジスタとして使われる事を想定し,本プログラム中で値のセットをしないようにした.
CPUのブロック図と動作の説明
以下に今回設計したCPUのブロック図を示します.
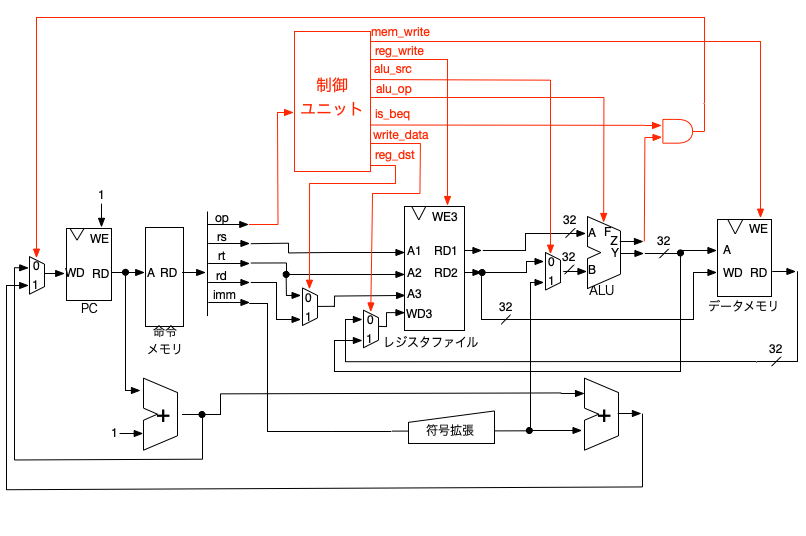
HLSでプログラムを書く観点からいうと,このCPUのブロック図において各アセンブリ命令がどのように動作するのかという説明が必要だと思いますが,そうなるとコンピュータアーキテクチャの講義になってしまうので,今回は割愛しておきます.もしそのような解説の希望があれば,ご連絡下さい.
ソースコード
1つのファイルに全ての記述をすると可読性が悪くなるので,以下のようにファイルを分割します.
- cpu.c (cpuに関する記述)
- cpu.h (cpuに関する記述で使用するdefine文, 構造体定義,プロトタイプ宣言などをまとめたもの)
- main.c (cpuの記述に対して,テストデータを送信したりするプログラム)
それぞれのファイルの内容を以下で補足していきたいと思います.
cpu.h
cpu.hのソースコードを以下に示します.
# include "HLS/hls.h"
typedef struct {
int rd1;
int rd2;
} INT2;
# define LW 0x00
# define SW 0x01
# define ADDI 0x02
# define BEQ 0x04
# define ADD 0x22
# define SLT 0x28
# define HLT 0x0F
# define ALU_ADD 2
# define ALU_SUB 6
# define ALU_SLT 7
typedef union {
short imm;
char rd;
} LO16;
typedef struct {
char op;
char rs;
char rt;
LO16 lo16;
} INST;
typedef struct {
int result;
bool z;
} ALU_OUTPUT;
constexpr auto REGFILE_SIZE = 32;
struct RegisterFile {
RegisterFile() : data{} {
// あらかじめ初期化しておきたいレジスタの内容をここに書いておく
data[0] = 0;
data[28] = 1000;
}
const int &operator[](int idx) const { return data[idx]; }
int &operator[](int idx) { return data[idx]; }
int data[REGFILE_SIZE];
};
constexpr auto DATAMEM_SIZE = 65536;
struct DataMemory {
DataMemory() : data{} {
// あらかじめ初期化しておきたいメモリの内容をここに書いておく
data[1000] = 5;
data[1001] = 5;
}
const int &operator[](int idx) const { return data[idx]; }
int &operator[](int idx) { return data[idx]; }
int data[DATAMEM_SIZE];
};
int slt(int a, int b);
ALU_OUTPUT alu(char op, int a, int b);
INT2 regfile(bool we3, char a1, char a2, char a3, int wd3);
int data_memory(bool we, short num, int data);
component void cpu();
ここで解説が必要なのは,レジスタファイルとデータメモリをクラス構造体を用いて定義している所でしょうか.
これは以下で紹介しているcpu.cでコメントアウトした箇所を見てもらえば分かるかと思うのですが,
元々,「int mem[65536]={[1000]=5, [1001]=5};」というように配列の要素を要素番号を指定して初期化していたのですが,今回使用しているHLSでは,この記述方法はwarningが出てしまいます.
まぁwarningなので無視しても良いのですが,より最新の記述方法に合わせるということで,クラス構造体を定義して,そのコンストラクタで初期化の内容を書くようにしました.
C++に不慣れな人からすると,これらのクラス構造体の記述は複雑怪奇に見えますが,「&operator」と記載されている部分はおまじないだと思ってみれば,構造体内にdataという配列定義と初期化の記述が含まれているだけのように見えないでしょうか?(見て下さい><)
cpu.c
以下にcpu.cの記述を示します.
# include<stdio.h>
# include<stdlib.h>
# include "HLS/hls.h"
# include "cpu.h"
int slt(int a, int b) {
int result;
if( a < b ) {
result = 1;
} else {
result = 0;
}
return result;
}
ALU_OUTPUT alu(char op, int a, int b) {
int result;
bool flag_z;
ALU_OUTPUT out;
if( op == ALU_ADD) {
result = a + b;
} else if( op == ALU_SUB ) {
result = a - b;
} else if( op == ALU_SLT) {
result = slt(a, b);
} else {
result = 0;
}
flag_z = (result == 0) ? true : false;
out.result = result;
out.z = flag_z;
return out;
}
INT2 regfile(bool we3, char a1, char a2, char a3, int wd3) {
INT2 ret;
//static int reg[32]{[28]=1000};
static auto reg = RegisterFile();
if(we3) {
if( a3 != 0 ) {
reg[a3] = wd3;
}
}
ret.rd1 = (a1 == 0) ? 0 : reg[a1];
ret.rd2 = (a2 == 0) ? 0 : reg[a2];
return ret;
}
int data_memory(bool we, short num, int data) {
int read_data;
//hls_init_on_powerup static int mem[65536]={[1000]=5, [1001]=5};
hls_init_on_powerup static auto mem = DataMemory();
if(we) {
mem[num] = data;
read_data = 0;
printf("Data Memory: write mem[%d]: %d\n", num, data);
} else {
read_data = mem[num];
printf("Data Memory: read mem[%d]: %d\n", num, read_data);
}
return read_data;
}
void print_op(char op) {
if(op == LW) {
printf("lw ");
} else if( op == SW ) {
printf("sw ");
} else if( op == ADDI ) {
printf("addi ");
} else if( op == BEQ ) {
printf("beq ");
} else if( op == ADD ) {
printf("add ");
} else if( op == SLT ) {
printf("slt ");
} else if( op == HLT ) {
printf("hlt ");
} else {
printf("?(%d) ", op);
}
}
void print_inst(unsigned short adr, INST inst) {
printf("%04d: ", adr);
print_op(inst.op);
if( inst.op == ADD || inst.op == SLT) {
printf("r%d, r%d, r%d\n", inst.lo16.rd, inst.rs, inst.rt);
} else {
printf("r%d, %d(r%d)\n", inst.rt, inst.lo16.imm, inst.rs);
}
}
INST inst_memory(unsigned short adr) {
static INST mem[65536] = {
{.op=LW, .rs=28, .rt=16, .lo16{.imm=0},}, // lw $16, 0($28)
{.op=LW, .rs=28, .rt=17, .lo16{.imm=1},}, // lw $17, 1($28)
{.op=ADDI, .rs=0, .rt=18, .lo16{.imm=0},}, // addi $18, $0, 0
{.op=ADDI, .rs=0, .rt=19, .lo16{.imm=0},}, // addi $19, $0, 0
{.op=SLT, .rs=19, .rt=17, .lo16{.rd=8},}, // LOOP: slt $8, $19, $17
{.op=BEQ, .rs=8, .rt=0, .lo16{.imm=3},}, // beq $8, $0, DONE
{.op=ADD, .rs=18, .rt=16, .lo16{.rd=18},}, // add $18, $18, $16
{.op=ADDI, .rs=19, .rt=19, .lo16{.imm=1},}, // addi $19, $19, 1
{.op=BEQ, .rs=0, .rt=0, .lo16{.imm=-5},}, // beq $0, $0, LOOP
{.op=SW, .rs=28, .rt=18, .lo16{.imm=2},}, // DONE: sw $18, 2($28)
{.op=HLT, .rs=0, .rt=0, .lo16{.imm=0},}, // hlt
};
print_inst(adr, mem[adr]);
return mem[adr];
}
void control_unit(char op, bool ®_write, bool &mem_write, char &write_data,
char ®_dst, char &alu_src, char &alu_op, bool &run, bool &is_beq) {
if ( op == LW ) {
reg_write = true;
mem_write = false;
write_data = 0;
reg_dst = 0;
alu_src = 1;
alu_op = ALU_ADD;
run = true;
is_beq = false;
} else if( op == SW ){
reg_write = false;
mem_write = true;
write_data = 0;
reg_dst = 0;
alu_src = 1;
alu_op = ALU_ADD;
run = true;
is_beq = false;
} else if( op == ADDI ){
reg_write = true;
mem_write = false;
write_data = 1;
reg_dst = 0;
alu_src = 1;
alu_op = ALU_ADD;
run = true;
is_beq = false;
} else if( op == ADD ){
reg_write = true;
mem_write = false;
write_data = 1;
reg_dst = 1;
alu_src = 0;
alu_op = ALU_ADD;
run = true;
is_beq = false;
} else if( op == SLT ){
reg_write = true;
mem_write = false;
write_data = 1;
reg_dst = 1;
alu_src = 0;
alu_op = ALU_SLT;
run = true;
is_beq = false;
} else if( op == BEQ ){
reg_write = false;
mem_write = false;
write_data = 0;
reg_dst = 0;
alu_src = 0;
alu_op = ALU_SUB;
run = true;
is_beq = true;
} else {
reg_write = false;
mem_write = false;
write_data = 0;
reg_dst = 0;
alu_src = 0;
alu_op = ALU_ADD;
run = false;
is_beq = false;
}
}
component void cpu() {
// varibable for cpu running
bool run = true;
// program counter
unsigned int pc = 0;
unsigned int pc_next;
unsigned int branch_addr;
// instruction
INST inst;
// variables for data path
INT2 reg_read_data;
ALU_OUTPUT alu_out;
int alu_a, alu_b, alu_result;
int mem_read_data;
int mem_write_data;
char reg_dst_num;
int reg_write_data;
// variables for control signals
bool reg_write, mem_write;
bool is_beq, is_branch, flag_z;
char alu_op;
char write_data, reg_dst, alu_src;
// variables for debug
int return_data;
while( run ) {
// instruction fetch
inst = inst_memory(pc);
// control unit
control_unit(inst.op, reg_write, mem_write, write_data, reg_dst,
alu_src, alu_op, run, is_beq);
// register read
reg_read_data = regfile(false, inst.rs, inst.rt, 0, 0);
// set up inputs for alu.
alu_a = reg_read_data.rd1;
alu_b = (alu_src) ? inst.lo16.imm : reg_read_data.rd2;
// set up inputs for data memory
mem_write_data = reg_read_data.rd2;
// calculation of address
alu_out = alu(alu_op, alu_a, alu_b);
alu_result = alu_out.result;
flag_z = alu_out.z;
// memory read(load)
mem_read_data = data_memory(mem_write, alu_result, mem_write_data);
// select write data for register
if( write_data == 0 ) {
reg_write_data = mem_read_data;
} else {
reg_write_data = alu_result;
}
// select the number of register to write
if( reg_dst == 0 ) {
reg_dst_num = inst.rt;
} else {
reg_dst_num = inst.lo16.rd;
}
// write to register file
regfile(reg_write, 0, 0, reg_dst_num, reg_write_data);
// count up pc
pc_next = pc + 1;
// calculation of branch address
branch_addr = pc_next + inst.lo16.imm;
// decide next pc value
is_branch = is_beq & flag_z;
pc = (is_branch) ? branch_addr : pc_next;
}
}
cpu.cの記述において,一番大事な点は,cpu()という関数の中身がほぼCPUのブロック図と同じ構造をしている点でしょうか.これはハードウェア(CPUのブロック図)を描いてから,HLSで設計しているためで,ちゃんとハードウェア構造を意識したようなHLS記述になっていると思います.
ハードウェア構造を意識せずにC言語のプログラムでCPUを記述すると,while文の中はおそらくswitch文で命令毎に異なる処理を書くような感じになるかと思いますが,そうするとハードウェア資源の共有などはされにくいと思います.
CPUのブロック図にない要素としては,hlt命令が入力されたときに,cpuの動作を止めるためのrun信号です.run信号をブロック図に入れるとすると,制御ユニットからrun信号が出力される感じでしょうが,その信号の行先を描く方法がなく,今回はブロック図に記載しておりません.
次にデータメモリ,命令メモリを今回はCPUの記述内に含めてしまってます.本来ならばこれらはCPUの外にあるのが通常ですが,今回は記述を簡単にするため,こうしてます.もし皆様からの要望が多ければ,CPUの外にメモリがあるような場合の記述方法も紹介したいと思います.
それとC言語のプログラムとして動作している時に,プログラムの実行内容が正しいかどうかを検証できるようにprintfで所々,変数の内容などを出力しています.これは実際にハードウェアの変換時には無視されるので,デバッグ時には気にしないでどんどん書いちゃいましょう.
main.c
# include<stdio.h>
# include<stdlib.h>
# include"cpu.h"
int main() {
cpu();
return 0;
}
main.cについてはcpuを起動することしかしていないため,すごくシンプルになっています.
アセンブリプログラムの内容を外部メモリに設定したり,データメモリに入力値のセットと出力値が期待値と一致しているかどうかのチェックなどをmain関数内に記述することもできますが,今回は全てcpuモジュール内に記述してしまったので,それらを割愛しています.
動作検証
プログラムとして動作検証
通常のプログラムとしてコンパイルして実行すると,printfにより,以下のような出力を得ることができます.
0000: lw r16, 0(r28)
Data Memory: read mem[1000]: 5
0001: lw r17, 1(r28)
Data Memory: read mem[1001]: 5
0002: addi r18, 0(r0)
Data Memory: read mem[0]: 0
0003: addi r19, 0(r0)
Data Memory: read mem[0]: 0
0004: slt r8, r19, r17
Data Memory: read mem[1]: 0
0005: beq r0, 3(r8)
Data Memory: read mem[1]: 0
0006: add r18, r18, r16
Data Memory: read mem[5]: 0
0007: addi r19, 1(r19)
Data Memory: read mem[1]: 0
0008: beq r0, -5(r0)
Data Memory: read mem[0]: 0
0004: slt r8, r19, r17
Data Memory: read mem[1]: 0
0005: beq r0, 3(r8)
Data Memory: read mem[1]: 0
0006: add r18, r18, r16
Data Memory: read mem[10]: 0
0007: addi r19, 1(r19)
Data Memory: read mem[2]: 0
0008: beq r0, -5(r0)
Data Memory: read mem[0]: 0
0004: slt r8, r19, r17
Data Memory: read mem[1]: 0
0005: beq r0, 3(r8)
Data Memory: read mem[1]: 0
0006: add r18, r18, r16
Data Memory: read mem[15]: 0
0007: addi r19, 1(r19)
Data Memory: read mem[3]: 0
0008: beq r0, -5(r0)
Data Memory: read mem[0]: 0
0004: slt r8, r19, r17
Data Memory: read mem[1]: 0
0005: beq r0, 3(r8)
Data Memory: read mem[1]: 0
0006: add r18, r18, r16
Data Memory: read mem[20]: 0
0007: addi r19, 1(r19)
Data Memory: read mem[4]: 0
0008: beq r0, -5(r0)
Data Memory: read mem[0]: 0
0004: slt r8, r19, r17
Data Memory: read mem[1]: 0
0005: beq r0, 3(r8)
Data Memory: read mem[1]: 0
0006: add r18, r18, r16
Data Memory: read mem[25]: 0
0007: addi r19, 1(r19)
Data Memory: read mem[5]: 0
0008: beq r0, -5(r0)
Data Memory: read mem[0]: 0
0004: slt r8, r19, r17
Data Memory: read mem[0]: 0
0005: beq r0, 3(r8)
Data Memory: read mem[0]: 0
0009: sw r18, 2(r28)
Data Memory: write mem[1002]: 25
0010: hlt r0, 0(r0)
Data Memory: read mem[0]: 0
今回,cpu.hのDataMemoryの記述内に,1000番地と1001番地に5を格納しているため,
乗算結果は25となります.その計算が正しくできていることが,上記の出力結果の最後から3行目にある「Data Memory: write mem[1002]: 25」という内容から確認できます.
ハードウェア記述として動作検証
プログラムとして実行するときは,gccなどと同様にコンパイルして実行すれば良いですが,ハードウェアとして実行するときも同様の手順でできます.
$ i++ -march=Stratix10 -O3 -o cpu_sim *.c -ghdl
コンパイルオプションで,-march=Stratix10など,FPGAのファミリ名や型番を指定すると,HDLシミュレーション用の実行ファイルが生成されます.そして,
この時に,-ghdlオプションを指定しておくと,HDLシミュレーション実行時に波形情報も保存されます.
なにはともあれHDLシミュレーションを実行しましょう.
$ ./cpu_sim
として,実行すれば,HDLシミュレーションが実行されます.
このHDLシミュレーション後に,プロジェクトディレクトリ内の verification/vsim.wlf が波形ファイルになりますので,波形ビューワで内容を確認することができます.
実際に波形ビューワでデータメモリへの書き込み部分を抽出した結果が以下となります.
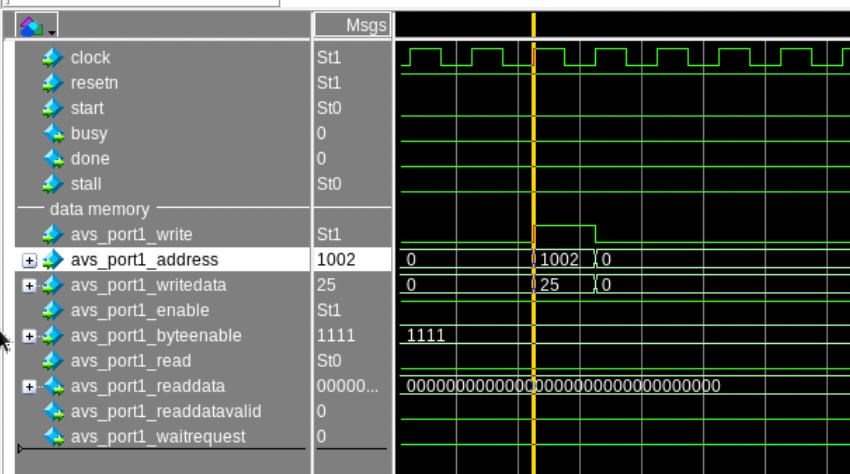
この図をみますと,write信号が1になっている時に,アドレス1002番地に対して,25という値が書かれていることが分かります.この波形の結果から,cpuは無事,ハードウェアとしても正しく動作していると言えます.
性能について
HDLシミュレーションが終了した後は,Webブラウザで,cpu_sim.prjディレクトリ内のレポートファイルを開き,verification結果を確認します.
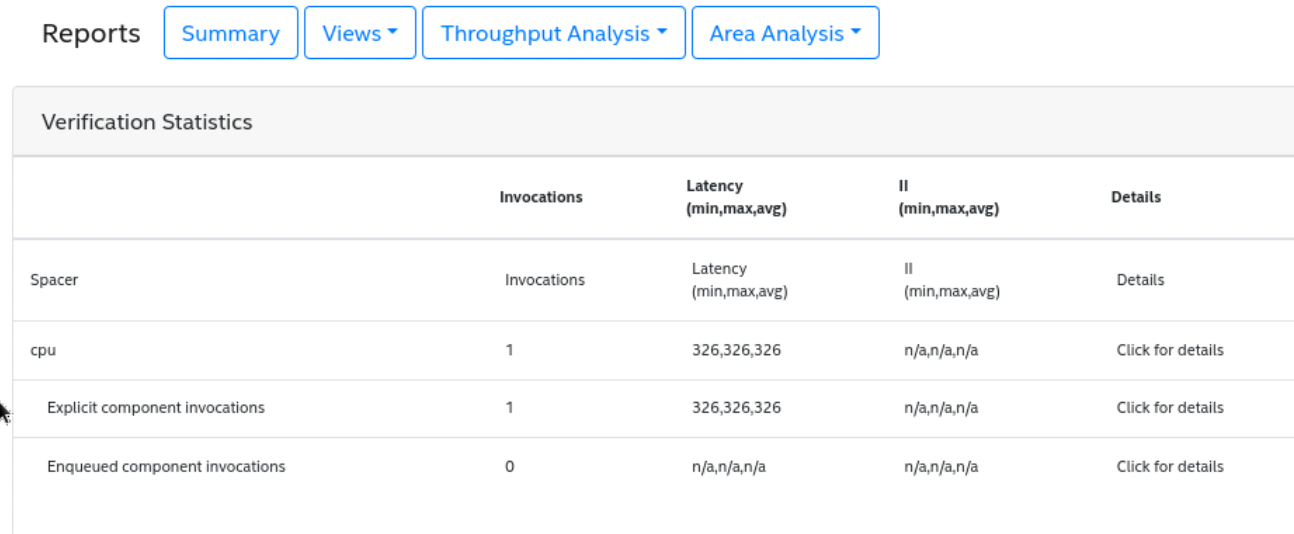
そうすると,上記のように実行にかかったサイクル数が326サイクルであることが分かります.この時,CPUが実行した命令数を考えると,アセンブリプログラムの内容から考えても分かりますが,先程,C言語のプログラム時に実行された命令を出力していたので,その個数を数えても分かります.今回は実行された命令の個数をログの結果から数えると,33命令となってました.以上のことから,1命令の実行あたりにかかるサイクル数はCPI(Clocks Per Instruction) = 326/33 = 約10サイクルということが分かります.
ただし,この326サイクルにはcpu自体を起動するためのサイクルなども含まれてますので少し正確性にはかけます.そこで,かけ算の内容を5x5から1000x1000を計算する内容に変更して,同様に実行された命令数とサイクル数を調べますと,実行された命令数は5008命令で,サイクル数は25201サイクルとなりました.よって,CPI = 25201/5008 = 約5サイクルということが分かります.(同じ事はレポートファイルのLoop Analysisから,cpu関数のwhileループのII(Iteration Interval)が5であることからも分かります)
以上,今回はとりあえずCPUをHLSで設計してみましたが,さらに性能を向上させるために,パイプラインプロセッサを設計してみることもできると思います.もしそのような記述方法に興味のある方がいらっしゃいましたら,ご連絡下さい.