※この記事は2020年に作成しました
#概要
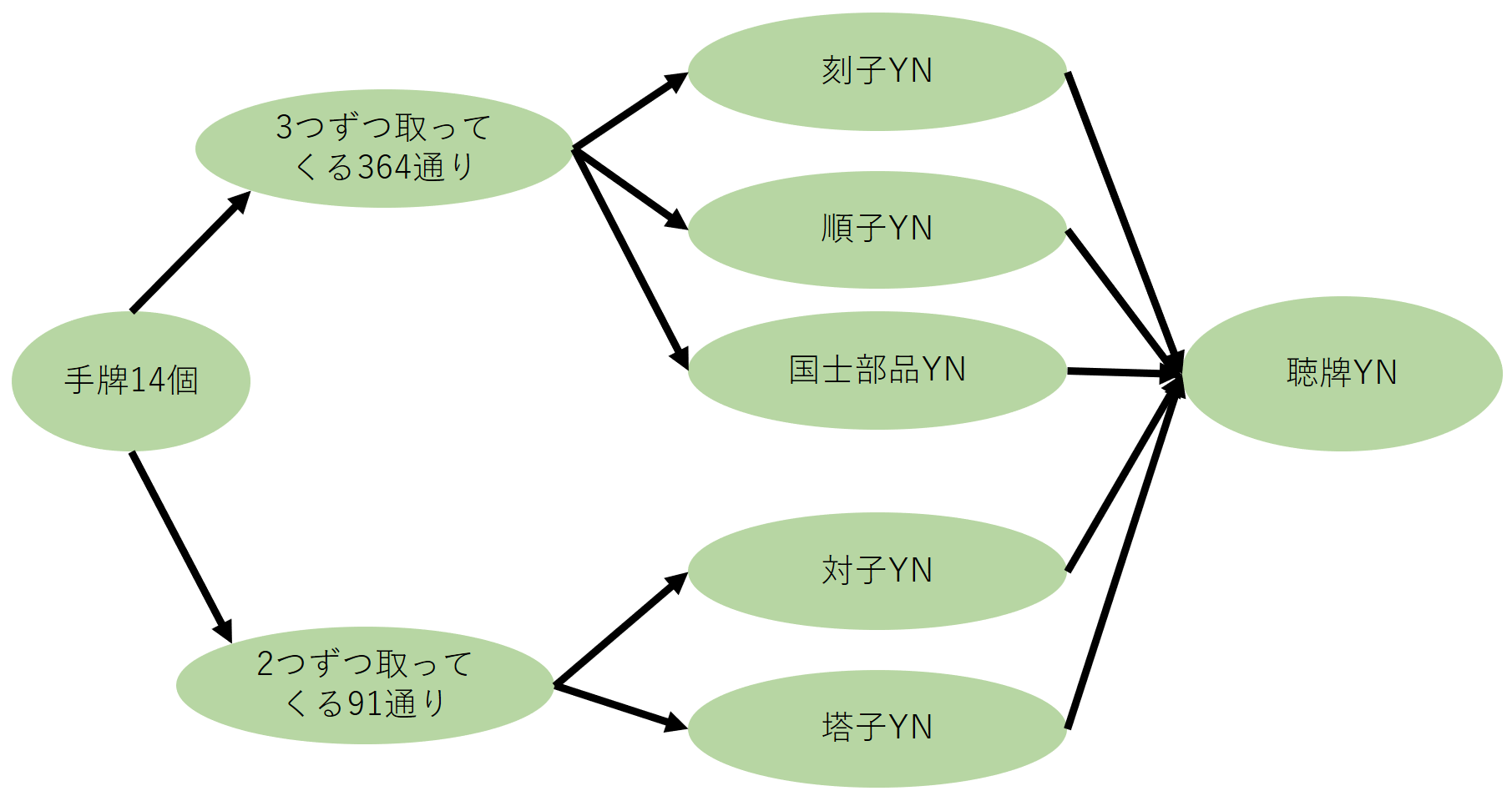
14個の手牌を、14個から2個とってくる91通りと、14個から3個取ってくる364通りにし、3個の場合は順子YN、刻子YN、国士の部品YNに、2個の場合は対子YN、塔子YNにいれ、その結果をまとめたものを1つの手牌とし、打牌を正解ラベルとして打牌予測をするようにした。
手牌数は鳴きなしのときのみの101437個使用した。
YNのモデルで判断する回数は、「データ数×((364通り×3つのYN)+(91通り×2つのYN))」なので、129,230,738回である。
_{14}C_2=91\\
_{14}C_3=364
###イメージ図
#結果
テストデータに対する正解率は約11%ほどになった。
実行時間198747秒。
#作成したコード
import numpy as np
import itertools
import time
from keras.models import load_model
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
np.set_printoptions(threshold=10000000,linewidth=200)
t1 = time.time()
data = 101437
x_train = np.zeros((data,34), dtype='float32')# x_trainは手牌
with open('C:/sqlite/tehai.csv', 'r') as fr:
for i,row in enumerate(fr.readlines(),start=0):
if i <data:
x_train[i] += np.array(list(map(np.float,row[:34])))
dahai = np.zeros((data,34), dtype='float32')#打牌読み込み
with open('C:/sqlite/tehai.csv', 'r') as fr:
for i,row in enumerate(fr.readlines(),start=0):
if i <data:
dahai[i] += np.array(list(map(np.float,row[:34])))
tehai = np.zeros((data,14))#x_trainを14個の手牌tehaiへ
for i in range(data):
cnt = 0
for j in range(34):
if x_train[i,j] >= 1:
tehai[i,cnt] = j
cnt += 1
x_train[i,j] -=1
if x_train[i,j] >= 1:
tehai[i,cnt] = j
cnt += 1
x_train[i,j] -=1
if x_train[i,j] >= 1:
tehai[i,cnt] = j
cnt += 1
x_train[i,j] -=1
if x_train[i,j] >= 1:
tehai[i,cnt] = j
cnt += 1
x_train[i,j] -=1
label=[0,1]
tehaiC364 = np.zeros((data,364,3))
for i in range(data):#tehaiを364通りへ
tehaiC364[i,] = list(itertools.combinations(tehai[i,], 3))
#print(tehaiC[i,])
tehaiC91 = np.zeros((data,91,2))
for i in range(data):#tehaiを91通りへ
tehaiC91[i,] = list(itertools.combinations(tehai[i,], 2))
label = [0,1]
modelToitsu = load_model('toitsuYN.h5')
ToitsuYN = np.zeros((data,91))#対子YNの結果を入れる
for i in range(data):#tehaiC78を対子YNにかける
for j in range(91):
x_train = np.zeros((1,2))
x_train[0,] = tehaiC91[i,j]
x_train = x_train/33.
pred = modelToitsu.predict(x_train, batch_size=1, verbose=1)
pred_label = label[np.argmax(pred[0])]
ToitsuYN[i,j] = np.argmax(pred[0])
modelTatsu = load_model('tatsuYN.h5')
TatsuYN = np.zeros((data,91))#塔子YNの結果を入れる
for i in range(data):#tehaiC91を塔子YNにかける
for j in range(91):
x_train = np.zeros((1,2))
x_train[0,] = tehaiC91[i,j]
x_train = x_train/33.
pred = modelTatsu.predict(x_train, batch_size=1, verbose=1)
pred_label = label[np.argmax(pred[0])]
TatsuYN[i,j] = np.argmax(pred[0])
modelShunts = load_model('shuntsYN.h5')
ShuntsYN = np.zeros((data,364))#順子YNの結果を入れる
for i in range(data):#tehaiCを順子YNにかける
for j in range(364):
x_train = np.zeros((1,3))
x_train[0,] = tehaiC364[i,j]
x_train = x_train/33.
pred = modelShunts.predict(x_train, batch_size=1, verbose=1)
pred_label = label[np.argmax(pred[0])]
ShuntsYN[i,j] = np.argmax(pred[0])
modelkotsu = load_model('kotsuYN.h5')
kotsuYN = np.zeros((data,364))#刻子YNの結果を入れる
for i in range(data):#tehaiCを刻子YNにかける
for j in range(364):
x_train = np.zeros((1,3))
x_train[0,] = tehaiC364[i,j]
x_train = x_train/33.
pred = modelkotsu.predict(x_train, batch_size=1, verbose=1)
pred_label = label[np.argmax(pred[0])]
kotsuYN[i,j] = np.argmax(pred[0])
modelkokushi = load_model('kokushiYN.h5')
kokushiYN = np.zeros((data,364))#国士YNの結果を入れる
for i in range(data):#tehaiCを国士YNにかける
for j in range(364):
x_train = np.zeros((1,3))
x_train[0,] = tehaiC364[i,j]
x_train = x_train/33.
pred = modelkokushi.predict(x_train, batch_size=1, verbose=1)
pred_label = label[np.argmax(pred[0])]
kokushiYN[i,j] = np.argmax(pred[0])
YN5 = np.zeros((data,1274))
for i in range(data):
ShunKotYN = np.hstack((ShuntsYN[i,],kotsuYN[i,]))
SKKYN = np.hstack((ShunKotYN,kokushiYN[i,]))
SKKYN_toitsu = np.hstack((SKKYN,ToitsuYN[i,]))
SKKYN_tatsu = np.hstack((SKKYN_toitsu,TatsuYN[i,]))
YN5[i,] = SKKYN_tatsu
model = Sequential()
#中間層、入力層、活性化関数ReLU関数
model.add(Dense(units=637,input_shape=(1274,),activation='relu'))
#出力層2、活性化関数ソフトマックス関数
model.add(Dense(units=34,activation='softmax'))
#最適化アルゴリズムAdam、損失関数クロスエントロピー
model.compile(
optimizer=Adam(lr=0.001),
loss='categorical_crossentropy',
metrics=['accuracy'],
)
history_adam=model.fit(
YN5,
dahai,
batch_size=100,
epochs=1,
verbose=1,
shuffle = True,
validation_split=0.2
)
t2 = time.time()
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}")