はじめに
現在、社内でAIや機械学習を用いたCADの見積りサービスの構想をプロジェクトとして企画しています。以前からプロジェクト自体は続いており、PoC(Proof of Concept)から、
実際にインサイドセールスでの営業や見積もり業務で運用できるようなサービスを目指しております。
目次
1 機械学習とCAD見積りの関連性
2 機械学習とモデル
3 データハンドリング(前処理)の重要性
4 機械学習のタスク
5 教師あり学習
6 機械学習の処理の手順
7 CADを活用している主な企業
8 機械学習のライブラリ調査
9 前処理、欠損地への対応例(*ここではサンプルソースとデータをあげます)
10 分類を実行するアルゴリズムの紹介
11 AWS・SageMakerを活用した本番化
12 自動見積もりサービスを開発したい方へ
13 興味あるかたはこちらまで、
1 機械学習とCAD見積りの関連性
3DのCADでの自動化は進んでおりますが、まだまだ機械学習を用いて完全に自動化することは
一部の企業を除いて達成できてない状況です。
2 機械学習とモデル
機械学習は大量のデータから、機械学習アルゴリズムによってデータの特性を見つけて予測などを行う計算式の塊を作り、
これをモデルといいます。そのモデルを作るためには、入力するデータとデータを処理するアルゴリズムが必要です。
データとアルゴリズムを基に内部のパラメータを更新し機械学習のモデルを作っていきます。
3 データハンドリング(前処理)の重要性
データハンドリングは前処理とも、いわれデータの入手や加工、つなぎわせや加工など、データ分析において必要な上で
何度も繰り返し実施されます。
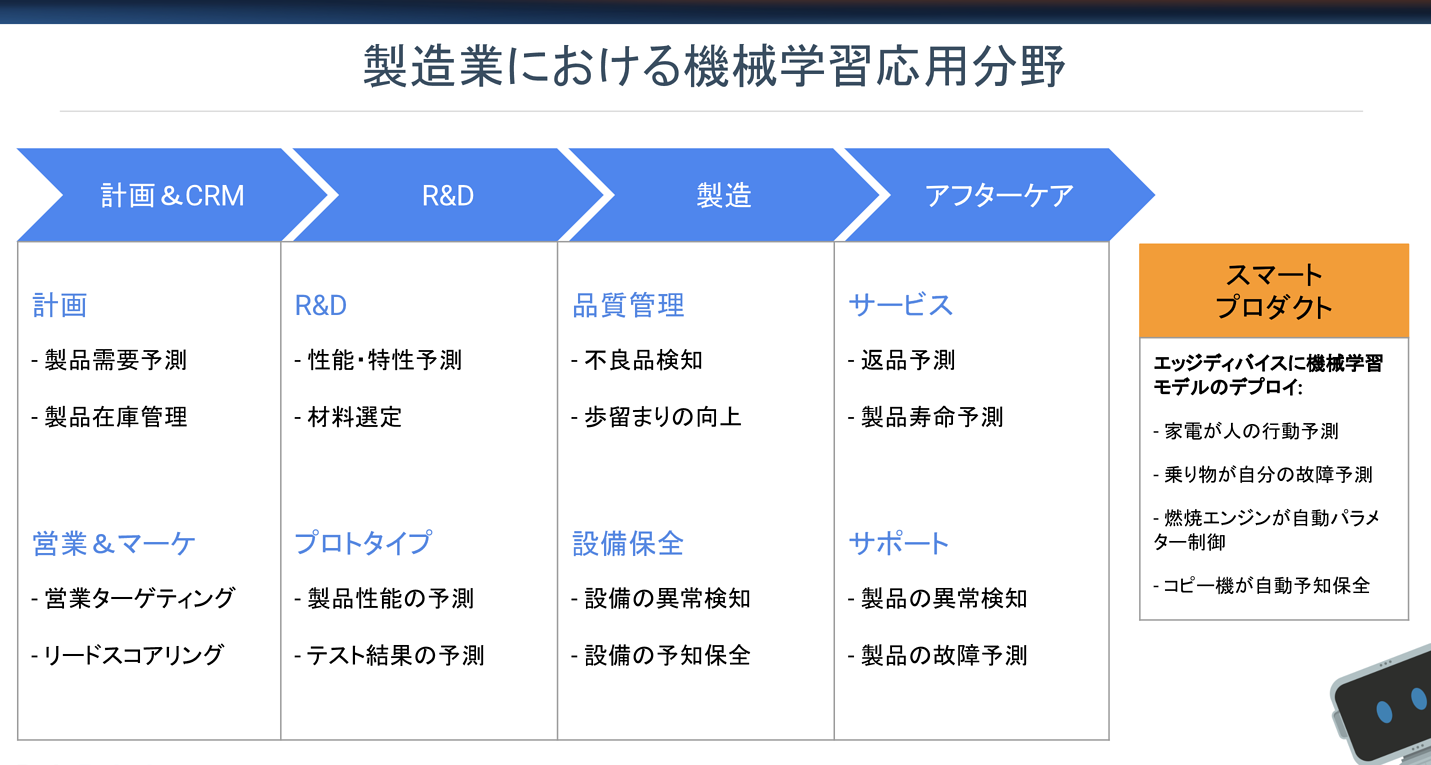
4 機械学習のタスク
・機械学習を用いて解決できる業務範囲は年々、増えています。
例:製造業における機械学習の活用事例
参考事例:DataRobot:データロボット
https://blog.datarobot.com/jp/2017/11/28/manufacturing
5 教師あり学習
・正解となるラベルデータが存在する場合に使用されます。
正解ラベル→ある課題に対して目的となる値。
正解ラベルである目的データが意味を持ち、それ以外のデータを用いて正解、または正解に近い値を予測します。
6 機械学習の処理の手順
・データ入手→今回の場合は、開発元の基盤DB、もしくは見積り担当の方に入力していただくという方式になりそうです
・データ加工→Excelデータを手入力で加工してもらうことを検討しています
・データ可視化→まとまったデータをMatplotlibなどで可視化します。
・アルゴリズム選択→Scikit learnなど目的データに沿ったアルゴリズムを選択します
・学習プロセス→アルゴリズムをもとにハイパーパラメータを設定します。こちらもScikit learnがよく活用されます
・精度評価→学習済みモデルを使って予測を行います。こちらもScikit learnがよく活用されます
・試験運用→今までは、は既知のデータである初期のExcelデータ(2000~3000)で予測していましたが、
未知のデータで実行する必要があります。
*モデルを作る段階では、入力していないデータなど
*評価がうまくいかない場合は、プロセスを見直し再実行する必要がある
・結果利用→試験運用の結果、実業務に利用可能なデータの精度が確保できれば、学習モデルを保存し、実業務に
モデルの予測結果を取り入れ、引き続き、予測精度の継続や評価やデータを追加して行うなどの運用が検討されます。
★参考書籍:Pythonによるあたらしいデータ分析の教科書 https://www.yodobashi.com/product/100000086600721250/
こちらの記述内容を参考にしました。
例:モデル最適化指標・評価指標の選び方
実際にデータから機械学習モデルを作成し、デプロイした効果を測定していくまでのステップ
・モデリング
・チューニング
・比較・評価
・ビジネス判断
・ビジネスインパクトの計算
参考事例:DataRobot:データロボット
https://blog.datarobot.com/jp/モデル最適化指標-評価指標の選び方

7 CADを活用している主な企業
★株式会社ミスミグループ本社
3D CADデータのみで機械加工品が調達できるプラットフォーム「meviy(メヴィー)」などのサービスを展開している。https://meviy.misumi-ec.com/
3D データには様々な3DCAD のフォーマットをサポート。
・ネイティブフォーマット Autodesk Inventor (.ipt), CATIA V5・V6 ( .CATPart), Creo (.neu/.prt/.xpr), Pro/Engineer (.prt/.neu/.xpr), Siemens PLM-NX (.prt), SolidEdge (.par/.pwd), SOLIDWORKS (.sldprt),I-deas (.arc/.unv)
・中間フォーマット STEP(.step / .stp), Parasolid( .x_t / .x_b /.xmt_txt /.xmt_bin), ACIS(.sat/.sab), JT(.jt), PRC(.prc) ※ICAD は STEP もしくは Parasolid を推奨
複数部品のアップロードも可能
1ファイルに複数の部品が保存されているファイルでも見積もりが可能
★見積の受発注プラットフォーム「CADDi」キャディ株式会社
(国内の事例)
特注板金加工品の3DCADデータをCADDiにアップロードすると、瞬時に見積・納期が表示され、
数クリックで購買が可能→https://corp.caddi.jp/service/
8 機械学習のライブラリ調査
参考資料。各機械学習ライブラリの比較をまとめております。
https://qiita.com/jintaka1989/items/bfcf9cc9b0c2f597d419
・scikit-learn
機能としては、分類 (Classification)や回帰 (Regression) 、クラスタリング (Clustering) 、次元削減(Dimensionality reduction)などが実装されています
→機械学習を含むデータマイニングなどで活用。
・Chainer
参考文献:
http://qiita.com/icoxfog417/items/96ecaff323434c8d677b
http://nonbiri-tereka.hatenablog.com/entry/2015/06/14/225706
Chainerは、Preferred Networksが開発したニューラルネットワークを実装するためのライブラリである。
・Caffe
参考文献:
http://caffe.berkeleyvision.org/
CaffeはPython向けの代表的なディープラーニングライブラリである。C++で実装され、GPUに対応しているため、高速な計算処理が可能であります
9 前処理、欠損地への対応例(*ここではサンプルソースとデータをあげます)
import numpy
import pandas as pd
# サンプルデータセット
df= pd.DataFrame(
{
'A':[1,np.nan,3,4,5],
'B':[6,7,8,np.nan,10],
'C':[11,12,13,14,15]
}
)
df
*機械学習のアルゴリズムを適用する前に、データの特性を理解して前処理を行うことが必要です。
・欠損地への対応
データの収集などで測定や通信などで生じる値の不備などを指します。
*上のサンプルソースでは npやnan、と記載しているところが欠損値です。
*上記のようなPDFやdxfファイルから角度や大きさや重要要素を抽出する際の前処理におけるパラメータの取得の際にデータを補う必要があります。やり方は色々とありますが
・欠損値への対応
・カテゴリー変数のコーディング
・特徴量の正規化などがあります
欠損値の除去など
isnullメソッドなどを用いた方法などがあります。
*他にもデータを収集したり加工するなかで、対応していく必要があります
df.issull()
# 各要素が欠損値か確かめる
★参考書籍:Pythonによるあたらしいデータ分析の教科書 https://www.yodobashi.com/product/100000086600721250/
こちらの記述内容を参考にしました。
*データ加工編集の例の一部ソース。主に価格帯の設定についてのソースです
"source": [
"cols = ['price', 'x_ans','y_ans','z_ans', '個数', '品名', '材質', '表面処理', '最小公差'] + \\\n",
" zumen_data.options_material_df.columns.values.tolist() + \\\n",
" zumen_data.options_surface_df.columns.values.tolist() + \\\n",
" zumen_data.options_materialgroup_df.columns.values.tolist()\n",
"df = zumen_data.teaching_df[cols]\n",
"df = shuffle_df(df)\n",
"\n",
"#必要に応じて値段でフィルターをかける\n",
"df = df.query('price < 10')\n",
"#df = df.query('price < 1')\n",
"#df = df.query('price > 1')\n",
"\n",
"'''\n",
"print('品名')\n",
"print(len(df.dropna(subset=['品名'])))\n",
"print('個数')\n",
"print(len(df.dropna(subset=['個数'])))\n",
"print('材質')\n",
"print(len(df.dropna(subset=['材質'])))\n",
"print('表面処理')\n",
"print(len(df.dropna(subset=['表面処理'])))\n",
"'''\n",
"\n",
"#質の良いデータにするための指定\n",
"#df = df.dropna(subset=['個数'])\n",
"df = df.dropna(subset=['表面処理'])\n",
"df = df.dropna(subset=['材質'])\n",
"y_df = df['price']\n",
"\n",
"#文字を含むor必要のないデータ列は削除する\n",
"df = df.drop('個数', axis=1)\n",
"df = df.drop('品名', axis=1)\n",
"df = df.drop('材質', axis=1)\n",
"df = df.drop('表面処理', axis=1)\n",
"df = df.drop('price', axis=1)\n",
"df = df.drop('end', axis=1)\n",
"cols"
10 分類を実行するアルゴリズムの紹介
分類を実行するアルゴリズム
・サポートベクターマシン
・決定木
・ランダムフォレスト
→CADの候補検索から、一致しているものを抽出しているのに、最適なアルゴリズムを調査中。
学習用データとテストデータにわけています
"source": [
"import numpy as np\n",
"import sklearn\n",
"from sklearn.cross_validation import train_test_split\n",
"length = len(df)\n",
"val_size = len(df)//10\n",
"x_train, x_test = df[val_size:], df[:val_size]\n",
"y_df = np.array(y_df).reshape((length,-1))\n",
"y_train, y_test = y_df[val_size:], y_df[:val_size]\n",
"x_train"
]
11 AWS・SageMakerを活用した本番化
Amazonが提供するサービスのひとつ。科学計算や機械学習の用途で使用されるソフトウェアを構築してくる、
完全マネージド型サービス
AWS SageMakerによって構築された環境は、機械学習のためのモデル訓練やデプロイだけでなく、JupyterNotebook、
Jupyter LabによるPythonの開発環境も提供してくれる。
https://aws.amazon.com/jp/sagemaker/
こちらの記事など参照にしてください。
・AWS SageMakerとGCP。機械学習のマネージメントサービス比較
https://qiita.com/Takumamiura/items/79c98a8270fff21e73a6
12 自動見積もりサービスを開発したい方へ
このシステムの汎用性は非常に高そうです。
自動的に見積もりをするためのPDFや重要要素を抽出しアルゴリズムは、考える限りでも複数パターンあります。
また、システム自体を本番化する上でAWSなどのアーキテクチャーも考えなければならないです。その期間がトライ&エラーの日数として大分かかるのかなと思います。
13 興味あるかたはこちらまで
株式会社CAMI & Co.の企業情報・プレスリリース。 株式会社CAMI&Co.は、IoTプロデュース、IoT製造開発、ロボット企画開発、経営コンサルティング、技術コンサルティング、ビッグデータ解析を強みとした企業です
https://cami.jp/