皆さんこんにちは!
シュークリーム大好きエンジニアのくろちゃんです。
こちらの記事は、CA21 Advent Calendar 2020の7日目の記事です!
最近QiitaやTwitterでのアウトプットが全くできていなかったので、アドベントカレンダーを良いきっかけにできたら嬉しいなと思っています![]()
背景
実は、3週間ほど前から23卒サーバサイドエンジニアの子を鍛え上げるというプロジェクトでメンターをやらせていただいています。
当面の目標をGo言語を用いたAPIサーバ開発ができるようになることを目標に置き、Go言語の基本構文から勉強してもらっています。
その中で、抽象化について学んでもらおうと思った際に上手い教え方ができず、**結局何が便利だから抽象化するんだっけ?**というところまで伝えられませんでした。
この体験を元に、自分自身抽象化についてもう一度学び直しました。
この記事を読んだ23卒の子が抽象化について少しでも理解を深めてくれたら良いなと思って記事にまとめます。
そもそも抽象化って?
プログラミング以外の場面でも、「抽象化して考えてみよう!」などと言ったりしますが、そもそも抽象化とは具体的に何をしたら抽象化できた事になるのでしょうか?
まずは抽象化の意味について調べてみました。
▼抽象化の意味(Wikipediaから引用)
思考における手法のひとつで、対象から注目すべき要素を重点的に抜き出して他は捨て去る方法である
何だかわかりそうで分からない・・・・。
個人的な解釈でいうと、要は「グルーピングする事」なのではないかと考えています。
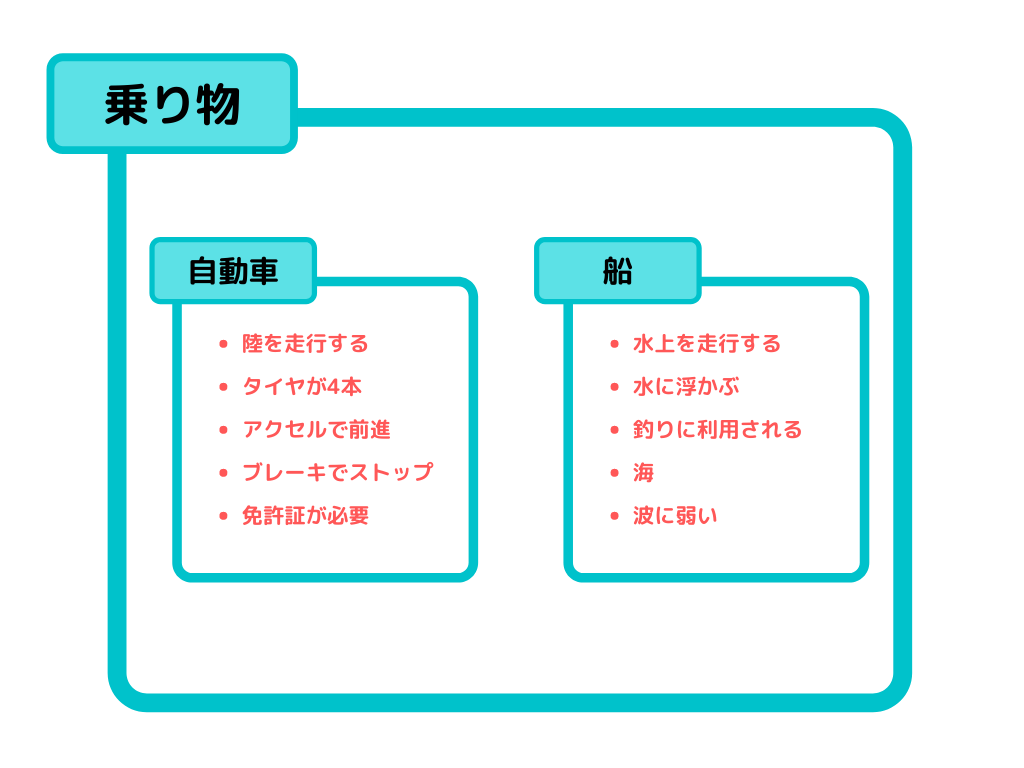
例えば、自動車を抽象化する時のことを考えてみましょう。
まずは、具体的な自動車を2台頭に浮かべます。スポーツカーと軽自動車を思い浮かべてみてください。

この2台比較したときに共通の要素を抜き出してみてください。
- アクセルを踏むと前進する
- ブレーキを踏むと止まる
- ライトが付いている
- 乗るには免許証が必要
などでしょうか?今回はスポーツカーと軽自動車を比べましたが、ここにトラックや電気自動車なども加えることで、共通する部分が抜き出しやすくなるのではないでしょうか。
上記で挙げたような要素を満たすモノのことを私たちは一般的に車や自動車と呼んでいますね?
単体で見れば、スポーツカーと軽自動車では出せるスピードが違ったり、燃費も違ったりします。
ですが、共通点として挙げた「アクセルを踏むと前進する」といった特徴はスポーツカーや軽自動車特有の特徴ではありません。
自動車というグループに所属するモノ全てが持ち合わせている特徴です。
僕はこのように、具体的な1つ1つのモノ同士を比べて共通点を探し、グルーピングする事が抽象化するという事だと考えています。
プログラミングにおける抽象化
前章で抽象化そのものの考え方について見てきました。
プログラミングにおける抽象化も、先ほど説明した考え方とほぼほぼ一緒で、基本的には共通項を切り出してグルーピングするというモノになります。
ですが、プログラミングにおける抽象化はどちらかというと、実装の詳細を隠蔽化して利用できるようにするという文脈で使われる事が多いように感じており、そこを説明しなかったからこそ、今回抽象化の必要性を感じてもらえなかったのかなーと考えています。
ここからは、Go言語のサンプルコードをお見せしながら、
- 共通項を切り出してグルーピングする抽象化
- 実装の詳細を隠蔽する抽象化
の2つについて詳しく説明します!
共通項を切り出してグルーピングする抽象化
こちらの抽象化は、僕たちが普段日常生活などでも行っている抽象化に近い考え方であるため、比較的簡単にイメージする事が可能です。
しかし、抽象化をするメリットがよく分からないという落とし穴にハマりがちなのかなとも感じています。
僕がトレーニーから「抽象化については何となくわかったけれど、何が便利なのか分かりません!」と言われた例を示します。よくある、動物を題材に取り上げたサンプルコードとなっています。
package animal
type Animal interface {
Bark()
Eat()
Die()
}
まずは、動物というグルーピングをした時に、
- 鳴く
- 食べる
- 死ぬ
という3つの動作は共通化して切り出せそうなので、interfaceとして切り出します。
次に、animalインターフェースを満たすDogとCatの詳細実装をします。
package dog
import (
"fmt"
"interface/animal"
)
type Dog struct {
Name string
Age int
FavoriteFood string
}
func New() animal.Animal {
return &Dog{
Name: "taro",
Age: 10,
FavoriteFood: "dog food",
}
}
func (d *Dog) Bark() {
fmt.Println("わん!")
}
func (d *Dog) Eat() {
fmt.Printf("%sは大好物の%sを食べた\n", d.Name, d.FavoriteFood)
}
func (d *Dog) Die() {
fmt.Printf("%sは%d歳で生涯を終えた\n", d.Name, d.Age)
}
package cat
import (
"fmt"
"interface/animal"
)
type Cat struct {
Name string
Age int
FavoriteFood string
}
func New() animal.Animal {
return &Cat{
Name: "tama",
Age: 8,
FavoriteFood: "マグロ",
}
}
func (c *Cat) Bark() {
fmt.Println("ニャァ!")
}
func (c *Cat) Eat() {
fmt.Printf("%sは大好物の%sを食べた。\n", c.Name, c.FavoriteFood)
}
func (c *Cat) Die() {
fmt.Printf("%sは%d歳で生涯を終えた\n", c.Name, c.Age)
}
Go言語の場合、Javaなどに見られるimplementsは存在せず、独自の型(今回で言うとstruct)をインターフェースにキャストするタイミングで自動的にインターフェースを満たしているかをチェックしてくれる。(←今回の例だとNew()にあたります)
※インターフェースを満たしている = interfaceで定義したメソッドを全て持っている状態。
インターフェースを満たしていない場合:下記のようなコンパイルエラーになる!
dog/dog.go:15:9: cannot use &Dog literal (type *Dog) as type animal.Animal in return argument:
*Dog does not implement animal.Animal (missing Bark method)
main関数では、単純にdogとcatのNew()を使ってインスタンスを生成し、生成したインスタンスの持っているメソッド(Bark(), Eat(), Die())を呼び出しています。
package main
import (
"interface/cat"
"interface/dog"
)
func main() {
animal1 := dog.New()
animal2 := cat.New()
animal1.Bark()
animal2.Bark()
animal1.Eat()
animal2.Eat()
animal1.Die()
animal2.Die()
}
いかがでしょうか?
共通項を切り出してグルーピングする抽象化についてイメージを持っていただけましたでしょうか?
今回の場合で言うと、犬と猫それぞれの共通点を考え、鳴く・食べる・死ぬと言う3つの振る舞いを取り出しました。
この時、鳴く・食べる・死ぬと言う振る舞いは犬と猫に限った話ではなく、動物というグループで見たときも同じ事が言えます。
そこで、鳴く・食べる・死ぬという振る舞いをまとめてanimalというインターフェースにまとめました。
現実世界での抽象化と同じような思考プロセスを辿るため、比較的すんなり理解できたのではないでしょうか?
しかし、この例では抽象化という考え方は学べても、プログラミングする上で何が嬉しいのか正直よく分かりません。(よね?)
実装の詳細を隠蔽する抽象化
個人的にプログラミングする中で得られる抽象化のメリットと感じているのは、実装の詳細を隠蔽して、関数を使わせることができることだと思っています。
実装の詳細とは、関数内部で行っている具体的な処理のことを指します。
例えば、ユーザを作成するという機能について考えたときの実装の詳細は下記のような一連の処理を指します。
- ユーザから受け取った値をバリデーションする
- UUIDを生成する
- ユーザモデルにマッピングする
- MySQLのUserテーブルに対して
INSERTを実行する
この時、この関数を使う側からすると、「中身の処理がどうなっていようと、そんなことはどうでもいいからユーザを作成してください!」と思うのではないでしょうか?
実装の詳細を隠蔽することで得られる実装上のメリット
開発者にとっても、実装詳細の隠蔽化をすることで得られるメリットがあります。
それは、コードの柔軟性を上げられるというメリットです!
まずは、設計者になったつもりで次のようなことを考えてみましょう。
ユーザに関するいくつかの仕様が固まったとします。今回は仮に、
- ユーザ作成
- ユーザ情報取得
- ユーザ情報更新
- ユーザと講座情報紐付け
という4つの機能を実装することになりました。
この時、設計者であるあなたが仕様通りの機能を全て実装するのは非常にナンセンスです。
できればチームメンバーに中身の実装はお願いしたいところですね!
そんな時役立つのが抽象化です!
設計者であるあなたは、上記4つの機能の入力と出力だけ定めたインターフェースを作成するだけで、あとの中身の実装は他の人に任せることができます。
任された人も、インターフェースを満たすようにさえすれば良いので、機能ごとの詳細な実装に集中することができます。
また、インターフェースを満たすものであれば同じインターフェースから複数個インスタンスが生成できるため、MySQLへの操作に使うインスタンス・Redisへの操作を行うインスタンスなどのように、中で使用している技術に応じてインスタンスを分けていくことが可能です。
そうしておけば、使う側も用途に合わせて適切なインスタンスを生成し、利用することで「あくまでユーザを作成するなどのような粒度」で扱うことができます。
上記のような抽象化のメリットを少しでも感じていただけるように、サンプルコードを作成しました。
GitHubにてコードを公開していますので、そちらも合わせてご覧ください。
まずはUserInterfaceという名前のインターフェースを定義します。
type UserInterface interface {
PrintMyData()
UpdateBaseData(entity.UserData)
}
これを見ただけで、ユーザは自分のデータを出力する機能と基本データを更新するための機能が存在することが分かりますね。
このインターフェースの詳細実装を見ていきましょう。
今回実装されているのは、adultとchildの2つです。
package adult
import (
"encoding/json"
"fmt"
"golearninterface/interface/user"
"golearninterface/model/user/entity"
"io/ioutil"
"log"
)
const filename = "user.json"
type Adult struct {
entity.UserData
Phone string `json:"phone"`
Married bool `json:"married"`
}
func New(userData entity.UserData, phone string, married bool) user.UserInterface {
return &Adult{
UserData: userData,
Phone: phone,
Married: married,
}
}
func (a *Adult) PrintMyData() {
if a.Age <= 18 {
fmt.Println("18歳以下の方はご利用になれません.")
return
}
file, err := json.MarshalIndent(a, "", " ")
if err != nil {
log.Fatalln(err)
}
if err := ioutil.WriteFile(filename, file, 0644); err != nil {
log.Fatalln(err)
}
fmt.Printf("%s様のデータを %s に保存しました.\n", a.Name, filename)
}
func (a *Adult) UpdateBaseData(data entity.UserData) {
if a.Age <= 18 {
fmt.Println("18歳以下の方はご利用になれません.")
return
}
a.UserData = data
}
package child
import (
"fmt"
"golearninterface/interface/user"
"golearninterface/model/user/entity"
)
type GenderType = int
const (
Man GenderType = 1
Woman GenderType = 2
Unknown GenderType = 0
)
type Child struct {
entity.UserData
Gender GenderType `json:"gender"`
}
func New(userData entity.UserData, gender GenderType) user.UserInterface {
return &Child{
UserData: userData,
Gender: gender,
}
}
func (c *Child) PrintMyData() {
if c.Age > 18 {
fmt.Println("19歳以上の方はご利用になれません.")
return
}
switch c.Gender {
case Man:
fmt.Printf("ようこそ!%sさん(♂).あなたの誕生日は%sですね!\n", c.Name, c.Birthday)
case Woman:
fmt.Printf("ようこそ!%sさん(♀).あなたの誕生日は%sですね!\n", c.Name, c.Birthday)
case Unknown:
fmt.Printf("ようこそ!%sさん.あなたの誕生日は%sですね!\n", c.Name, c.Birthday)
}
}
func (c *Child) UpdateBaseData(data entity.UserData) {
if c.Age > 18 {
fmt.Println("19歳以上の方はご利用になれません.")
return
}
c.UserData = data
}
Adult(大人)とChild(子供)で全く異なる実装がされていることがわかりますか?
まずは、PrintMyData()について。
もちろん大人と子供で年齢の条件が異なるため、別々のバリデーションがかかっています。
また、Adult(大人)は自分自身のデータをJSON形式に変換してuser.jsonという名前のファイルに出力しているのに対して、Child(子供)は性別に合わせて文字列を生成し、標準出力にプリントしています。
異なるのは関数の内部処理だけではありません。
大人と子供で構造体の中身が違うことがわかると思います。
type Adult struct {
entity.UserData
Phone string `json:"phone"`
Married bool `json:"married"`
}
type Child struct {
entity.UserData
Gender GenderType `json:"gender"`
}
インターフェースを基にしてそれぞれ異なった構造体をもち、それぞれの要件に合わせた実装がされていると見ることができます。
これらの生成されたインスタンスを使う側は、特に実装の中身を意識することなく、生成したインスタンスで公開されている関数を利用することができます。
package main
import (
"fmt"
"golearninterface/model/user/adult"
"golearninterface/model/user/child"
"golearninterface/model/user/entity"
)
func main() {
fmt.Println("-------- Child --------")
childUser := child.New(
entity.UserData{
Name: "kuro",
Age: 18,
Birthday: "2001/12/07",
},
child.Man,
)
childUser.PrintMyData()
childUser.UpdateBaseData(
entity.UserData{
Name: "黒澤",
Age: 17,
Birthday: "1998/03/07",
},
)
childUser.PrintMyData()
fmt.Println("-------- Adult --------")
adultUser := adult.New(
entity.UserData{
Name: "Shiro",
Age: 22,
Birthday: "1998/12/07",
},
"080-1111-2222",
true,
)
adultUser.PrintMyData()
adultUser.UpdateBaseData(entity.UserData{
Name: "白澤",
Age: 23,
Birthday: "1997/12/07",
})
adultUser.PrintMyData()
}
-------- Child --------
ようこそ!kuroさん(♂).あなたの誕生日は2001/12/07ですね!
ようこそ!黒澤さん(♂).あなたの誕生日は1998/03/07ですね!
-------- Adult --------
Shiro様のデータを user.json に保存しました.
白澤様のデータを user.json に保存しました.
今回は触れませんでしたが、インターフェースを定義するメリットの1つとして、テスタビリティが上がるというのもあります。
インターフェースは、実装してほしい関数の入力と出力の形だけを定めたものであるため、モック化してテストに利用することができます。
モック化とテストについてもいつか書きたいなと思っています!
まとめ
Go言語のサンプルコードを示しながら、抽象化することのメリットについて話してきました。
抽象化というと、日常で何気なく使っている、「ものごとの要素部分だけを抽出してわかりやすくする」という思考法を思い浮かべがちですが、プログラミングにおける抽象化はもっと幅広い意味を持っています。
皆さんの作っているアプリケーションのコードを見直してみてください。
もし、関数の中身が膨大になっていたり、1つの関数が異常に多くの責務を担当しているように感じたなら、抽象化の出番かもしれませんよ!!
ここまで読んでいただいたみなさん、ありがとうございました!
是非この後もCA21 Advent Calendar 2020をお楽しみください!!
みなさんにとって今年の締め括りが素晴らしいものになることを心から祈っています。ではっ![]()
PR
内定先のCyberAgentでは22卒のエンジニア採用を行っています!
僕たちと一緒に21世紀を代表する企業をつくりましょう!
▼エントリーはこちらから
https://www.cyberagent.co.jp/careers/news/detail/id=25511