はじめに
この記事ではYoutub DATA APIを利用して、キーワード検索エンジンを作成しました。
任意のキーワードを入力することで上位10個の動画をランキング形式で表示することができます。
環境構築
実行環境
言語:Python, HTME&CSS(Bootstrap)
OS:Windows11
ツール:Git/GitHub, Docker
Dockerを利用した環境構築
Dockerを利用したDjangoの環境構築は[こちらの記事]を参考にしてください。
今回はDockerfile, docker-compose.yml, requirements.txtを以下のように記述します。
Django==3.1
psycopg2-binary==2.8.6
FROM python:3
ENV PYTHONUNBUFFERED 1
RUN mkdir /code
WORKDIR /code
COPY requirements.txt /code/
RUN pip install -r requirements.txt
COPY . /code/
version: '3'
services:
db:
image: postgres
ports:
- "5432:5432"
volumes:
- ./db_data:/var/lib/postgresql/data
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
web:
build: .
command: python3 manage.py runserver 0.0.0.0:8000
volumes:
- .:/code
ports:
- "8000:8000"
depends_on:
- db
DBの設定をしていますが今回のサイトにはDBは利用しないためsettings.pyでは設定する必要はありません。
またプロジェクト名とアプリ名は任意で構いませんがコード全文を載せているGitHubを参考にしてもらっても大丈夫です。
アプリケーション作成
ここではアプリケーションの作成をします。dockerコンテナ内で以下のコマンドを入力してください。python3 manage.py startapp [app名]
こうするとアプリケーションが作成されるはずです。
続いてsettings.pyですが以下の変更を行なってください。
LANGUAGE_CODE = 'ja'
TIME_ZONE = 'Asia/Tokyo'
USE_I18N = True
USE_L10N = True
USE_TZ = True
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/3.1/howto/static-files/
STATIC_URL = '/static/'
STATICFILES_DIRS = ([os.path.join(BASE_DIR, 'static'),])
APIを利用してYoutubeデータを取得する
Youtube DATA APIの取得方法はこのリンクをご利用ください。
実際にAPI KEYを発行した後のデータ取得方法とDjangoへの反映方法について解説します。
データ取得
今回はPythonを利用しキーワードの検索結果をデータフレーム型で取得しました。
このファイルはアプリケーション内に作成してください。
以下、コードです。
from apiclient.discovery import build
from apiclient.errors import HttpError
from oauth2client.tools import argparser
import pandas as pd
YOUTUBE_API_KEY = 'xxxxxxxxxxxxxxxxxxxx'
YOUTUBE_API_SERVICE_NAME = 'youtube'
def youtube_search(options):
youtube = build(YOUTUBE_API_SERVICE_NAME, 'v3', developerKey = YOUTUBE_API_KEY)
search_response = youtube.search().list(part = 'id, snippet', q = options, maxResults = 10, order = 'viewCount', type = 'video',).execute()
viewcount_list = []
title_list = []
channel_list = []
thumbnail_list = []
videoid = []
for search_result in search_response['items']:
viewcount = youtube.videos().list(part = 'statistics', id = search_result['id']['videoId']).execute()
viewcount_list.append(viewcount['items'][0]['statistics']['viewCount'] + '回')
title_list.append(search_result['snippet']['title'])
channel_list.append(search_result['snippet']['channelTitle'])
thumbnail_list.append(search_result['snippet']['thumbnails']['default']['url'])
videoid.append(search_result['id']['videoId'])
df = pd.DataFrame({
'title':title_list,
'channel':channel_list,
'viewcount':viewcount_list,
'thumbnail':thumbnail_list,
'videoid':videoid
})
return df
if __name__ == "__main__":
#コンソールでキーワードを入力 ⇨ 関数youtube_searchを呼び出し検索
word = input('キーワードを入力')
print(youtube_search(word))
search_responseでYoutubeから情報を取得してきます。その際に引数q = optionsがキーワードであり指定したキーワードの内容のコンテンツデータを取得します。
また、maxResults = 10, order = 'viewCount'とすることでキーワードの中で視聴数Top10の動画を取得できます。
このとき、得られる情報はjson形式で得られるためその中のid, snippetにコンテンツの情報が格納されています。
その後for分で一個ずつ取り出し、各項目ごとにリスト化しデータフレームに格納します。
Djangoに反映する
以上までで、必要なデータの取得ができました。
ここではその結果をDjangoに反映するためのコードを記載します。
今回の仕組みは簡単で、検索前のページでキーワードを入力すると、views.pyでAPIを叩いて検索結果をデータフレームで取得し、それを検索結果のページで表示するというものです。
以下コードです。
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('sample/', include('api_sample.urls')),
]
from django.urls import path
from . import views
app_name = 'sample'
urlpatterns = [
path('', views.YoutubeSearchView.as_view(), name='youtube_search'),
]
from django.http import HttpResponse
from django.shortcuts import render
from django.views.generic import View
from . import get_data_api
import json
# Create your views here.
class YoutubeSearchView(View):
def get(self, request, *args, **kwargs):
if 'word' in request.GET:
keyword = request.GET['word']
youtube_df = get_data_api.youtube_search(keyword)
json_record = youtube_df.reset_index().to_json(orient='records')
data = []
data = json.loads(json_record)
context = {
"word":keyword,
'data':data
}
print(context)
return render(request, 'result.html', context)
return render(request, "search.html")
{% load static %}
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8" />
<title>Youtube検索エンジン</title>
<link rel="stylesheet" href="{% static 'css/style.css' %}">
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-EVSTQN3/azprG1Anm3QDgpJLIm9Nao0Yz1ztcQTwFspd3yD65VohhpuuCOmLASjC" crossorigin="anonymous">
</head>
<body>
<header>
<div class = 'header-area'>
<h1><a href = '{% url 'sample:youtube_search' %}' style = 'text-decoration: none;'>
Youtube検索エンジン</a></h1>
</div>
</header>
<form action='' method = 'get' onsubmit='doSomething();return false;'>
{% csrf_token %}
<input type="text" class = 'form_control' name="word" placeholder = 'キーワードを入力してください' value='{{ word }}'>
<input type='submit'class = 'btn btn-primary' value="検索する">
</form>
{% block contents %}
{% endblock %}
</body>
{% extends 'search.html' %}
{% load static %}
{% block contents %}
<div class = "main-container">
<h3>「{{ word}}」の検索結果</h3>
<table class="table">
<thead>
<tr>
<th scope="col">タイトル</th>
<th scope="col">チャンネル名</th>
<th scope="col">再生回数</th>
<th scope="col">サムネイル</th>
</tr>
</thead>
{% for elem in data %}
<tbody>
<tr>
<td class = 'elem'><a href = 'http://www.youtube.com/v/{{ elem.videoid }}' style = 'text-decoration: none'>
{{ elem.title | truncatechars:30 }}</a></td>
<td class = 'elem'>{{ elem.channel }}</td>
<td class = 'elem'>{{ elem.viewcount }}</td>
<td><a href = 'http://www.youtube.com/v/{{ elem.videoid }}'>
<img src = "{{ elem.thumbnail }}"></a></td>
</tr>
</tbody>
{% endfor %}
</table>
</div>
{% endblock %}
.header-area h1 {
font-family: "メイリオ";
}
.header-area a {
color: black;
}
.header-area a:hover {
color: black;
}
body {
text-align: center;
}
.main-container {
width: 80%;
text-align: center;
margin: 0 auto;
padding-top: 50px;
}
.elem {
margin: 0 auto;
}
.elem a {
color: black;
}
.elem a:hover {
background-color: azure;
}
.form_control {
width: 30%;
height: 40px;
border-radius: 1rem;
}
完成したサイト
完成したサイトは以下のようになります。
①トップページ
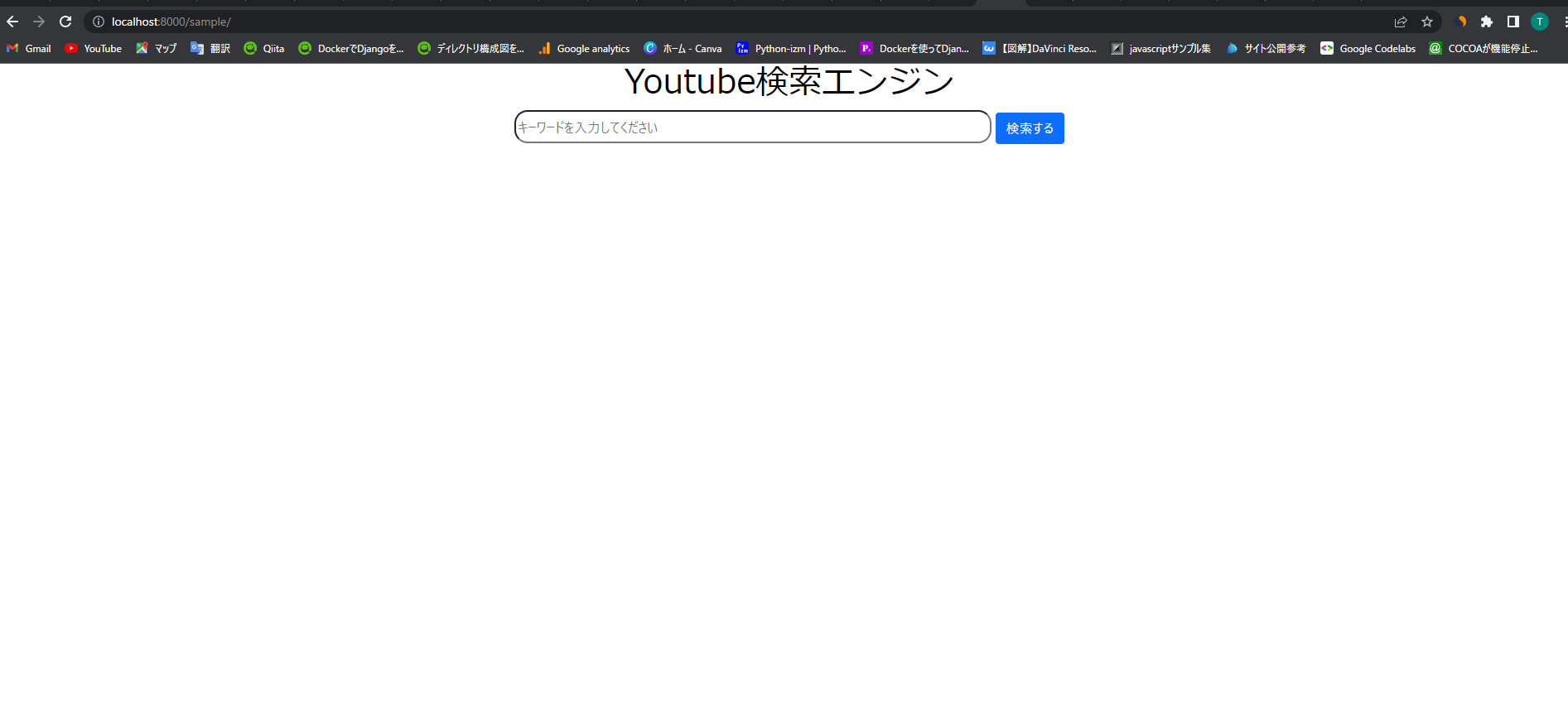
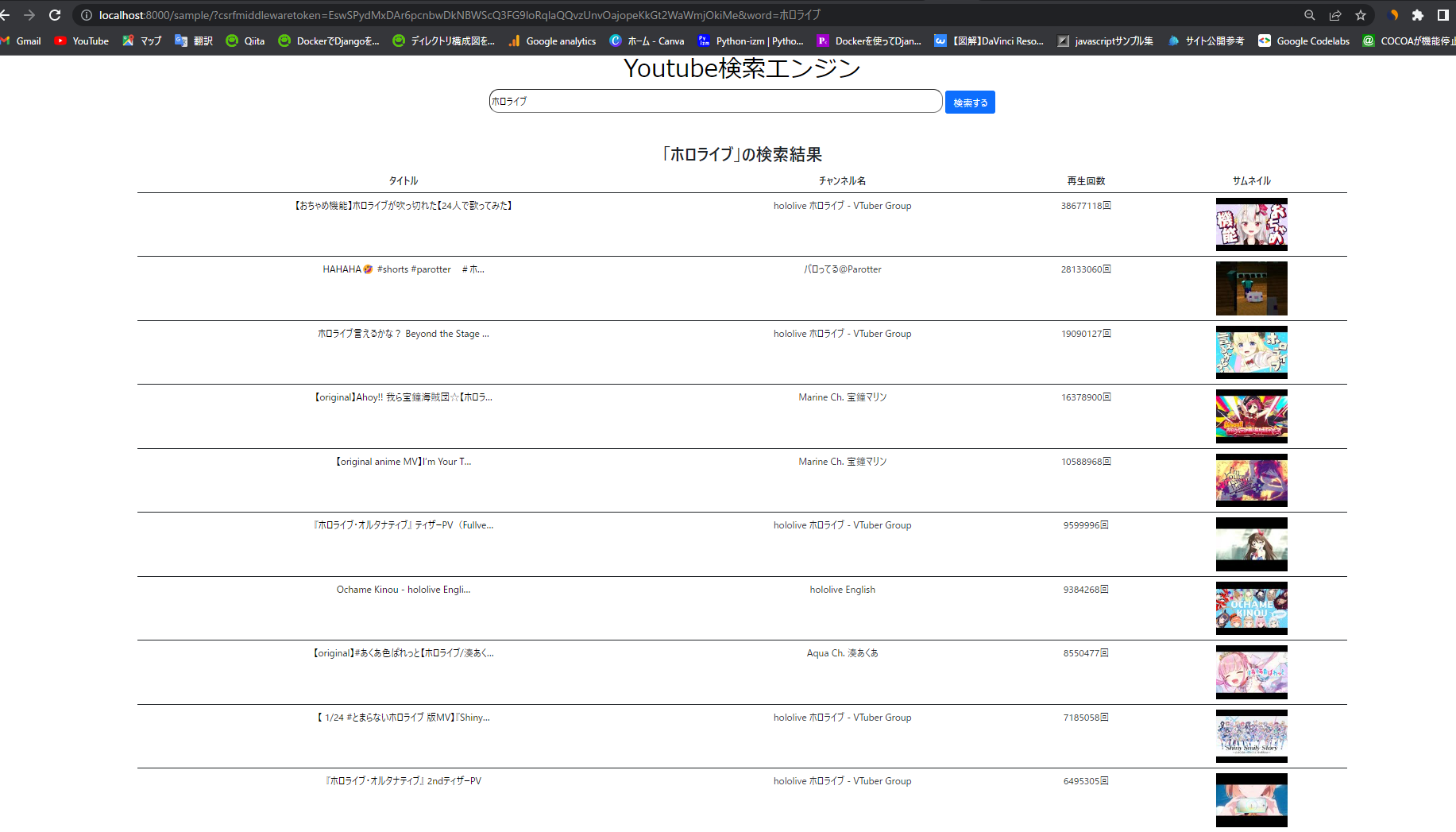
②「ホロライブ」で検索した場合
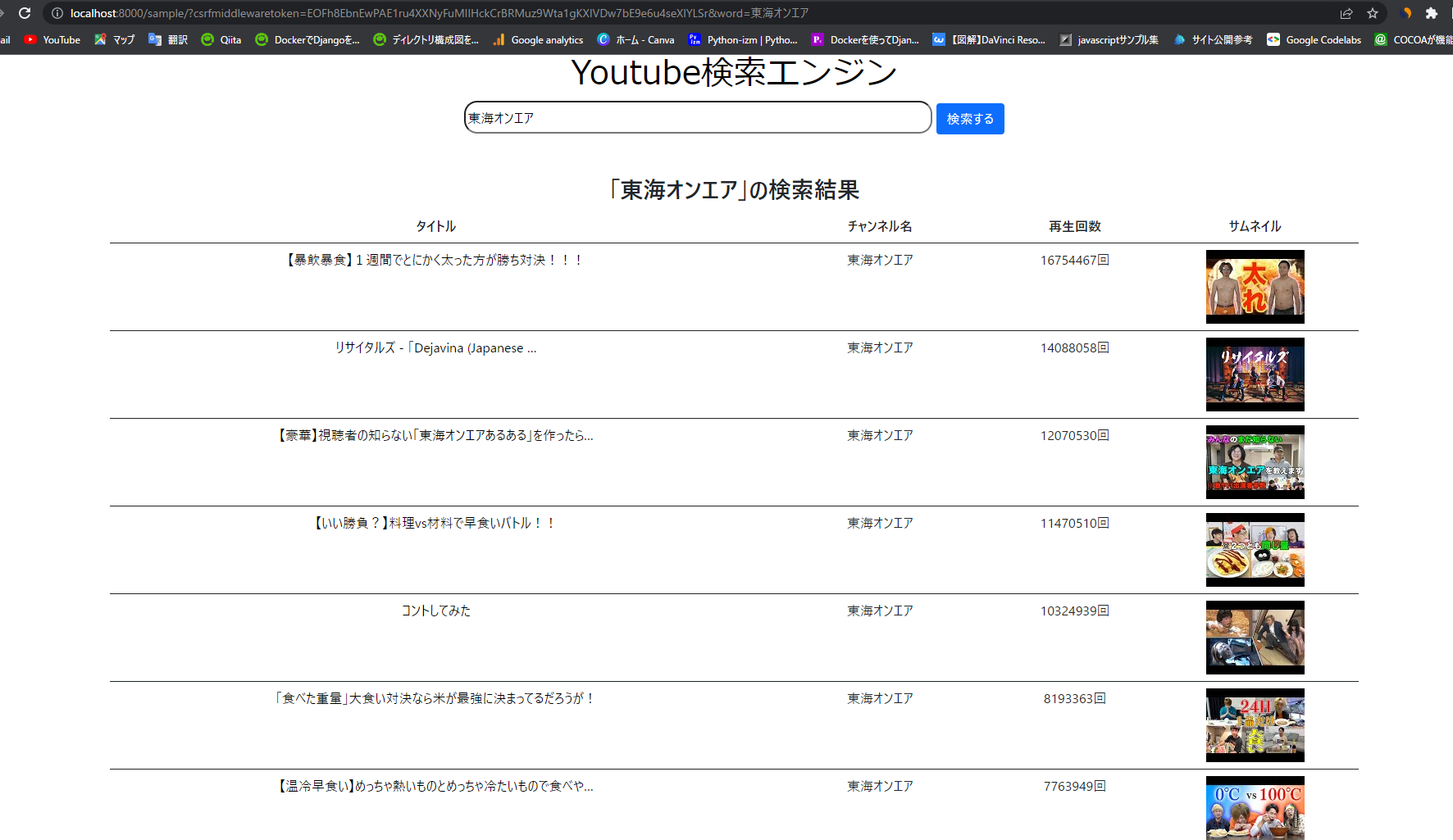
③「東海オンエア」で検索し場合
まとめ
Pythonを利用すればこのコード量でYoutubeから自由にデータを取得できます。 自動取得の方法として「API」と「スクレイピング」があるのですが個人的にはAPIの方が高速でリファレンス等がしっかりしているものが多いのでおすすめです。「スクレイピング」は対象ページのhtml要素からデータ取得するため仕様変更などに対応しないといけないんですね。Youtube DATA APIは他にもいろいろな情報を取得できるので色々試してみたいですね。
ここまで読んでくださりありがとうございました。
コード全文はGitHubに記載しています。