はじめに
スクレイピングとは~スクレイピングコードの実装までの説明をしていきたいと思います。
コードはpythonで学習コストの低さと汎用性の高さからseleniumを使ってスクレイピングの実装をしていきます。
今回は楽天トラベルのスクレイピングを題材に説明していきます。
スクレイピングでできること
スクレイピングとはwebサイト上に存在するデータを取得することです。
なのでweb上にない情報は取ることができません!(※大事)
事前知識・準備
コードを書く前に必要なものを紹介していきます。
そもそもスクレイピングが必要なのか
APIが公開されてる場合は、そこからデータがとれるかもしれません。
個人の経験則ですがAPIがあるところはスクレイピング対策されている傾向があり、コードの実装が難しくなります。(こちらは今回の趣旨とずれるので割愛)
利用規約の確認
サイトによってはスクレイピングを禁止していていたりするので、利用規約を読んで確認をしましょう。
一応会員登録していなければ同意を利用規約に同意をしていないので問題はないそう?ですが、グレーな気がします。
デベロッパーツール
ブラウザ(google)の三点からその他ツールを選ぶとデベロッパーツールがあると思います。
スクレイピングではHTMLソースからデータを抜き取るのがメインです。
デベロッパーツールを使いHTMLソースを確認します。
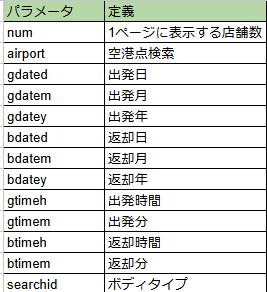
パラメータ
URLの理解も必要になります。例えば、楽天レンタカーの検索後のパラメータが下記になります。
https://cars.travel.rakuten.co.jp/cars/rcf010a.do?tid=1&num=30&type=1&ac=&rno=&campagin=&hotel=&display=0&jcid=&cgrid=&nccampaign=0&pretype=1&bcid=&rprate=&jid=&gdatey=2024&gdatem=06&gdated=03>imeh=10>imem=00&bdatey=2024&bdatem=06&bdated=04&btimeh=17&btimem=00&subtype=1&airport=ISG&goflg=0&rbt=6&searchid=1&searchid=9&searchid=5&atmt=1
?以降(...rcf10a.do?のところ)はパラメータとなります。上記のパラメータはレンタル開始日や車種などの条件が入っています。このパラメータの値を渡すことで欲しい検索結果が手に入ります。
つまり、複数の検索結果が欲しい場合、例えば複数の出発日時や車種で検索したいときなどは、このパラメータの値を変えることで瞬時に欲しい情報を取ることができ、コードの量を減らすことができます。
例えば、楽天トラベルのパラメータはこんな感じです。
seleniumの超基本
最低限のスクレイピングに必要なコードの説明をします。
driver = webdriver.Chrome()
これでドライバーインスタンスを作成します。これのメソッドを使うことで、スクレイピングを実行できます。基本的に新しいseleniumを使っていてローカル環境の場合はwebdriverのインストールなどは不要です。
driver.get(url)
指定されたurlの場所に飛ぶことができます。
element = driver.find_element(By.CLASS_NAME, "shopName")
これでhtmlソース上にあるクラス名がshopNameのタグを指定することができます。
返り値としてそのタグの情報を返します。
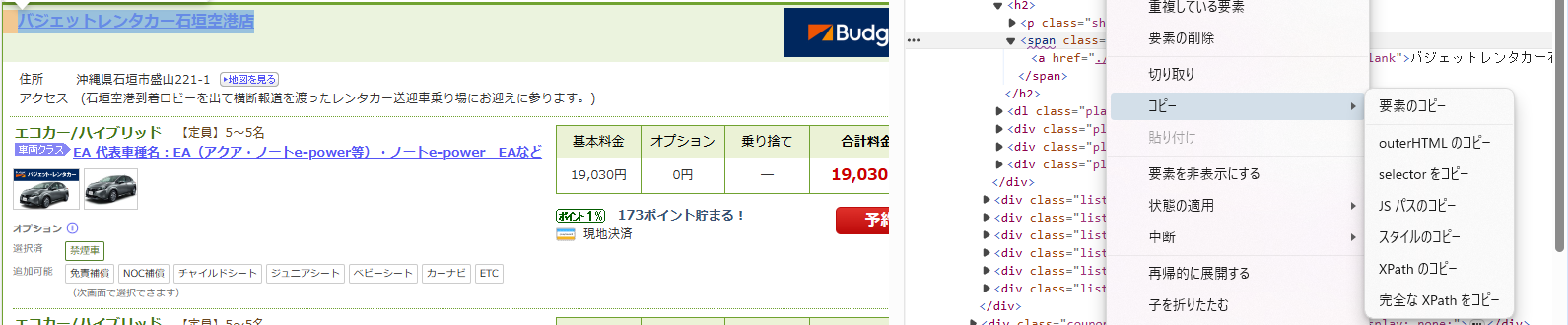
見方はデベロッパーツールを開いて、取得したい箇所のタグを調べることでクラス名等が分かります。

Byクラスは他にも
- ID
- XPATH
- NAME
- TAG_NAME
- CSS_SELECTOR
などたくさんあります。
また、css_selectorとxpathは該当のタグを右クリックすることで簡単に取ることができます。
可読性は下がりますがコードを読む必要がないため実装は楽です。
element.text
これで指定したタグに記載されている文字を取得出来ます。
seleniumには他にもたくさんの機能があります。
例えばクリックやスクロールでの画面操作、ドライバーのオプション、処理の遅延(後述しています)などがあります。
詳しくはドキュメントを見てください。
https://kurozumi.github.io/selenium-python/index.html
実装
今回は作成した検索条件にヒットした店舗名を取得していきます。
まずはコード全体。
# 楽天レンタカーに出店している他社のレンタル料金をスクレイピングするスクリプト
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import pandas as pd
def main():
try:
num = 50 # 1ページに表示する店舗数
airport = "ISG" # 空港点検索
gdated = "07" # 出発日
gdatem = "06" # 出発月
gdatey = "2024" # 出発年
bdated = "08" # 返却日
bdatem = "06" # 返却月
bdatey = "2024" # 返却年
gtimeh = "10" # 出発時間
gtimem = "00" # 出発分
btimeh = "17" # 返却時間
btimem = "00" # 返却分
searchid = "1" # 軽自動車
# 変数の定義
url = f"https://cars.travel.rakuten.co.jp/cars/rcf010a.do?num={num}&type=1&hotel=&gdarea=&bdarea=&gsarea=&bsarea=&display=0&l-id=top_pc_car_search-dated&gdated={gdated}&gdatem={gdatem}&gdatey={gdatey}&subtype=1&airport={airport}&bcid=&bdated={bdated}&bdatem={bdatem}&bdatey={bdatey}&goflg=0&bairport=&searchid={searchid}&atmt=1>imeh={gtimeh}>imem={gtimem}&btimeh={btimeh}&btimem={btimem}"
driver = setup_driver()# ドライバーオブジェクトの定義
scrape(driver, url) # スクレイピング
except Exception as e: # todo: エラーが発生したらslackとかに飛ぶようにしたい
msg = f"エラーが発生しました:{e}"
print(msg)
raise e
finally:
print("プログラムを終了します")
if driver:
driver.quit() # ドライバーを閉じる
def setup_driver():
# webdriverの準備をする
options = Options()
options.page_load_strategy='eager' # 処理速度を速める
options.add_argument('--disable-extensions') # エクステンションをなくす
options.add_argument("--headless=new") # cheome above 109
driver = webdriver.Chrome(
# command_executor='http://localhost:8888/wd/hub',
options=options
)
return driver
def scrape(driver, url):
shop_name = (By.CLASS_NAME, "shopName") # 店の名前を特定するのに使用
driver.get(url)
wait_element_detection(driver, shop_name, max_wait_time=10) # ページの読み込みが完了するまで待機
elements = driver.find_elements(shop_name[0], shop_name[1])
for ele in elements:
print(ele.text)
def wait_element_detection(driver, locator, max_wait_time=10):
wait = WebDriverWait(driver, max_wait_time)
wait.until(EC.presence_of_element_located(locator))
if __name__ == "__main__":
main()
コードを分けて処理を見ていきたいと思います。
try:
num = 50 # 1ページに表示する店舗数
airport = "ISG" # 空港点検索
gdated = "07" # 出発日
gdatem = "06" # 出発月
gdatey = "2024" # 出発年
bdated = "08" # 返却日
bdatem = "06" # 返却月
bdatey = "2024" # 返却年
gtimeh = "10" # 出発時間
gtimem = "00" # 出発分
btimeh = "17" # 返却時間
btimem = "00" # 返却分
searchid = "1" # 軽自動車
# 変数の定義
url = f"https://cars.travel.rakuten.co.jp/cars/rcf010a.do?num={num}&type=1&hotel=&gdarea=&bdarea=&gsarea=&bsarea=&display=0&l-id=top_pc_car_search-dated&gdated={gdated}&gdatem={gdatem}&gdatey={gdatey}&subtype=1&airport={airport}&bcid=&bdated={bdated}&bdatem={bdatem}&bdatey={bdatey}&goflg=0&bairport=&searchid={searchid}&atmt=1>imeh={gtimeh}>imem={gtimem}&btimeh={btimeh}&btimem={btimem}"
こちらは変数の定義をしています。
今回は特定の日付、場所、車種でしかスクレイピングをしませんが、将来的に拡張できるように変数を定義しています。
driver = setup_driver()# ドライバーオブジェクトの定義
...
中略
...
def setup_driver():
# webdriverの準備をする
options = Options()
options.page_load_strategy='eager' # 処理速度を速める
options.add_argument('--disable-extensions') # エクステンションをなくす
options.add_argument("--headless=new") # cheome above 109
driver = webdriver.Chrome(
# command_executor='http://localhost:8888/wd/hub',
options=options
)
return driver
ドライバーインスタンスの作成をしています。このインスタンスのメソッドを使ってスクレイピングをしていきます。定義時にoptions引数を入れることで、細かい設定を追加できます。
ここでは、速度向上を狙ってpage_load_strategy='eager'と拡張機能は不要なので--disable-extensionsを追加しています。
--headless=newはプログラム実行時にブラウザをユーザーが見られるように立ち上げるかどうかを決めます。このオプションを入れないことでブラウザがの挙動が見られるようになります。
scrape(driver, url) # スクレイピング
...
中略
...
def scrape(driver, url):
shop_name = (By.CLASS_NAME, "shopName") # 店の名前を特定するのに使用
driver.get(url)
wait_element_detection(driver, shop_name, max_wait_time=10) # ページの読み込みが完了するまで待機
elements = driver.find_elements(shop_name[0], shop_name[1])
for ele in elements:
print(ele.text)
def wait_element_detection(driver, locator, max_wait_time=10):
wait = WebDriverWait(driver, max_wait_time)
wait.until(EC.presence_of_element_located(locator))
driver.get(url) で引数のurlを開きます。
seleniumは人の操作のようにページがすべて読み込まれたから欲しいデータを取りに行くのような挙動ができません。なので、wait_element_detection関数でページを読み込めるまで待つように命令をしています。
locator引数で取得したいデータの場所を指定(今回だと店舗名)し、max_wait_timeの時間まで表示されるのを待ちます。max_wait_timeを過ぎてもページが読み込めない場合はエラーを返します。
ページが無事に表示されたら、elements = driver.find_elements(shop_name[0], shop_name[1])
ですべての店舗名をリスト形式で取得します。(find_elementで一つのみを取得出来ます。)
最後にfor文でele.textと返すことで店舗名が表示されます。
日産レンタカー石垣空港
美らレンタカー石垣空港店※最終返却18時迄 予約対象者:石垣空港到着便から出発便迄の利用に限る
グッドスピードレンタカー石垣島店
カースタレンタカー石垣島真栄里店
ククルレンタカー 石垣営業所
ルートレンタカー石垣島店(全車免責補償込!最終便対応可能!石垣島空港5分送迎付!)