概要
Azure AIのSpeech StudioというWebサービスを使うと、トレーニング済みのモデルを利用して、ブラウザで、音声の解析や、音声とテキストの相互変換のデモを試すことができます。
主な機能
Speech(音声)の主な機能は以下のとおりです。
- テキストを読み上げる。
- 音声合成マークアップ言語(SSML)を利用して、読み上げ方を変える。
- 音声をテキストに変換する。(文字起こし)
- 意図認識を実装する
- 何をして欲しいか、何を教えて欲しいかと言った意図をあらかじめ登録して、それにヒットさせる。
- キーワード認識
- 「Hey, Siri~」のように、ある処理を呼び出す開始合図となる言葉を登録できる。
Speech Studioとは
Copilotに聞いてみました。
AzureのSpeech Studioは、アプリケーションに音声サービスの機能を組み込むためのUIベースのツールセットです。コーディングなしでプロジェクトを作成し、音声テキスト変換、テキスト読み上げ、音声翻訳などの機能を簡単にテストおよび統合できます12。
具体的には、以下のような機能があります12:
リアルタイム音声テキスト変換:音声をリアルタイムでテキストに変換します。
バッチ音声テキスト変換:大量の音声データを一括で文字起こしします。
カスタム音声モデル:特定のボキャブラリや話し方に合わせた音声認識モデルを作成します。
発音評価:発音の正確性と流暢性を評価します。
音声翻訳:音声を他の言語に翻訳します。
カスタム音声:独自のカスタム音声を作成し、テキスト読み上げに使用します。
これにより、開発者は音声認識や音声合成の機能を簡単にアプリケーションに組み込むことができます。
URLはこちらです。
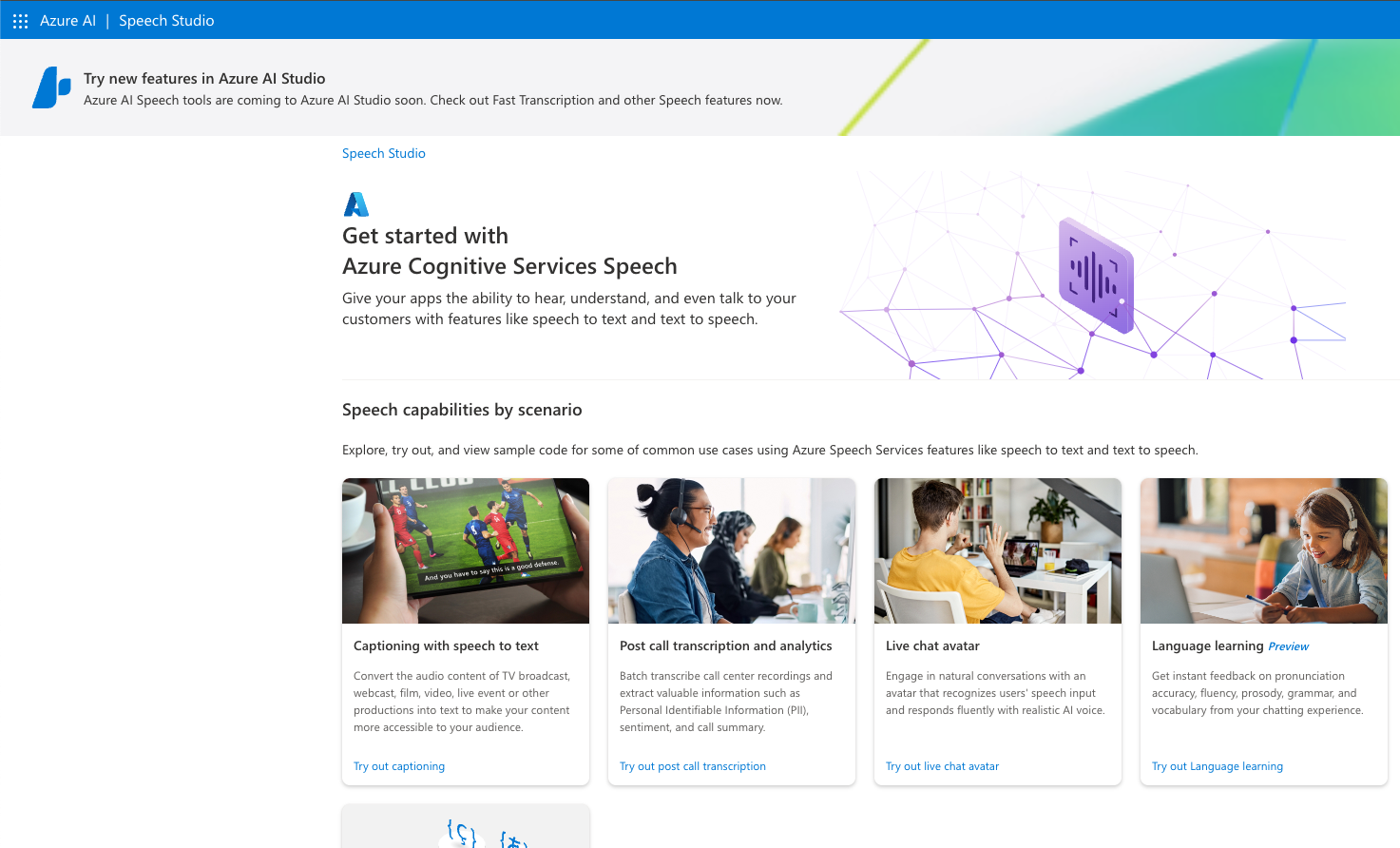
それでは、早速使ってみましょう。
Captioning with speech to text
リアルタイム、またはオフライン(あらかじめ録音(録画)したデータ)に、キャプションをつけることが出来ます。
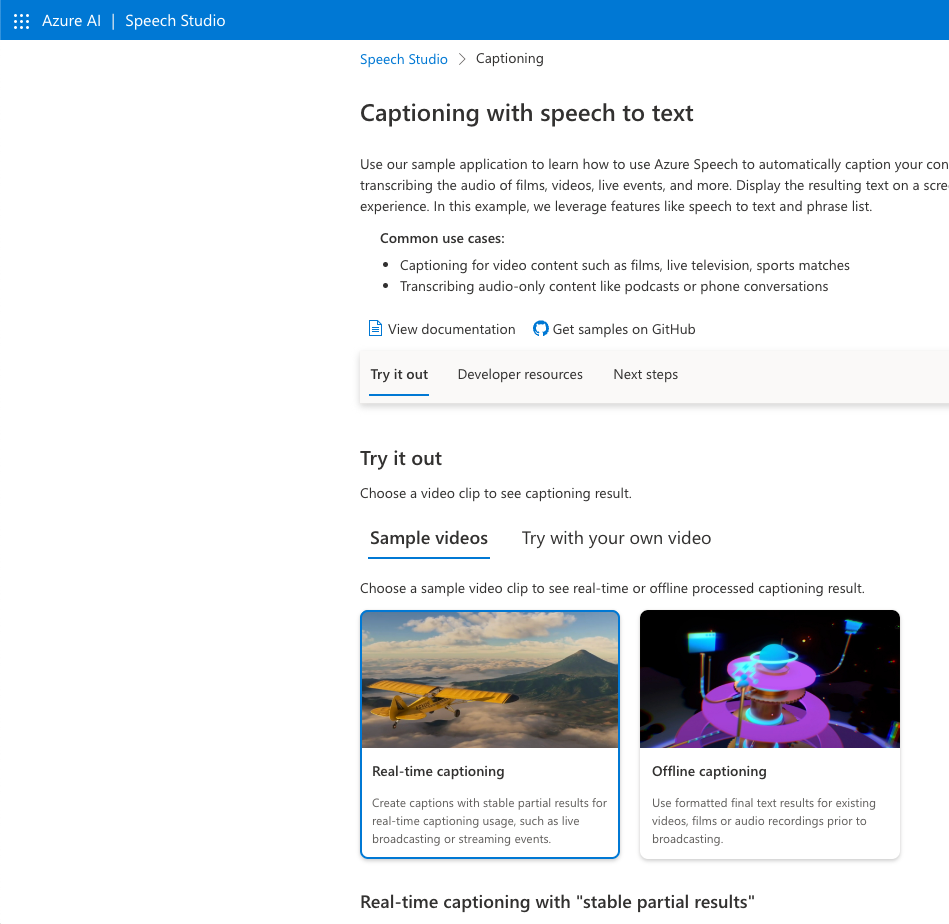

リアルタイムの方は、後から、単語が書き換えられることがあり、やや読みにくいです。
オフラインの方は、よくある洋画の字幕のように表示され、表示タイミングが絶妙で読みやすいです。
手元のmp3, mp4ファイルなどをアップロードして、文字起こしもできます。
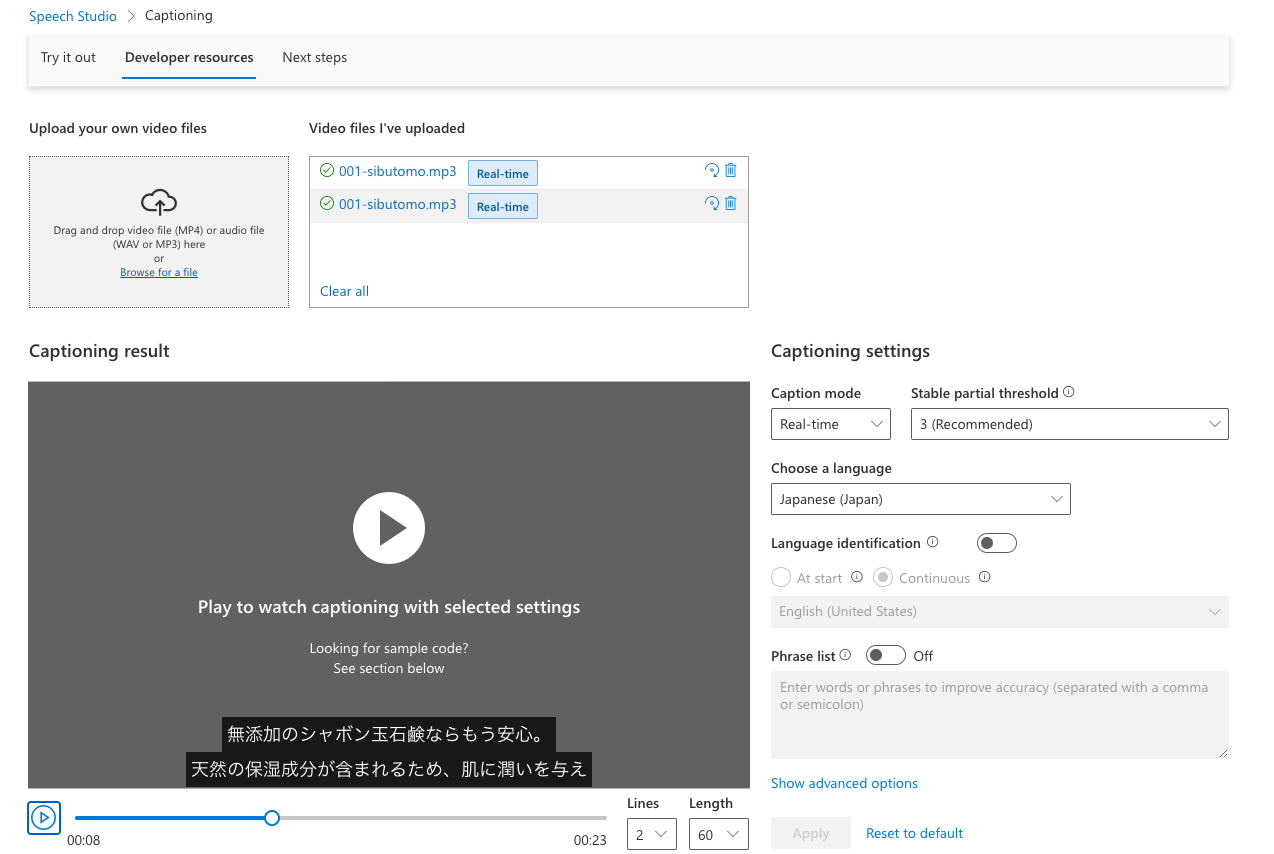
日本語のサンプルmp3ファイルをダウンロードして試してみました。
Language learning
マイクとスピーカーを使って、AIと話ができます。
いずれは、言語学習の教材になりそうです。
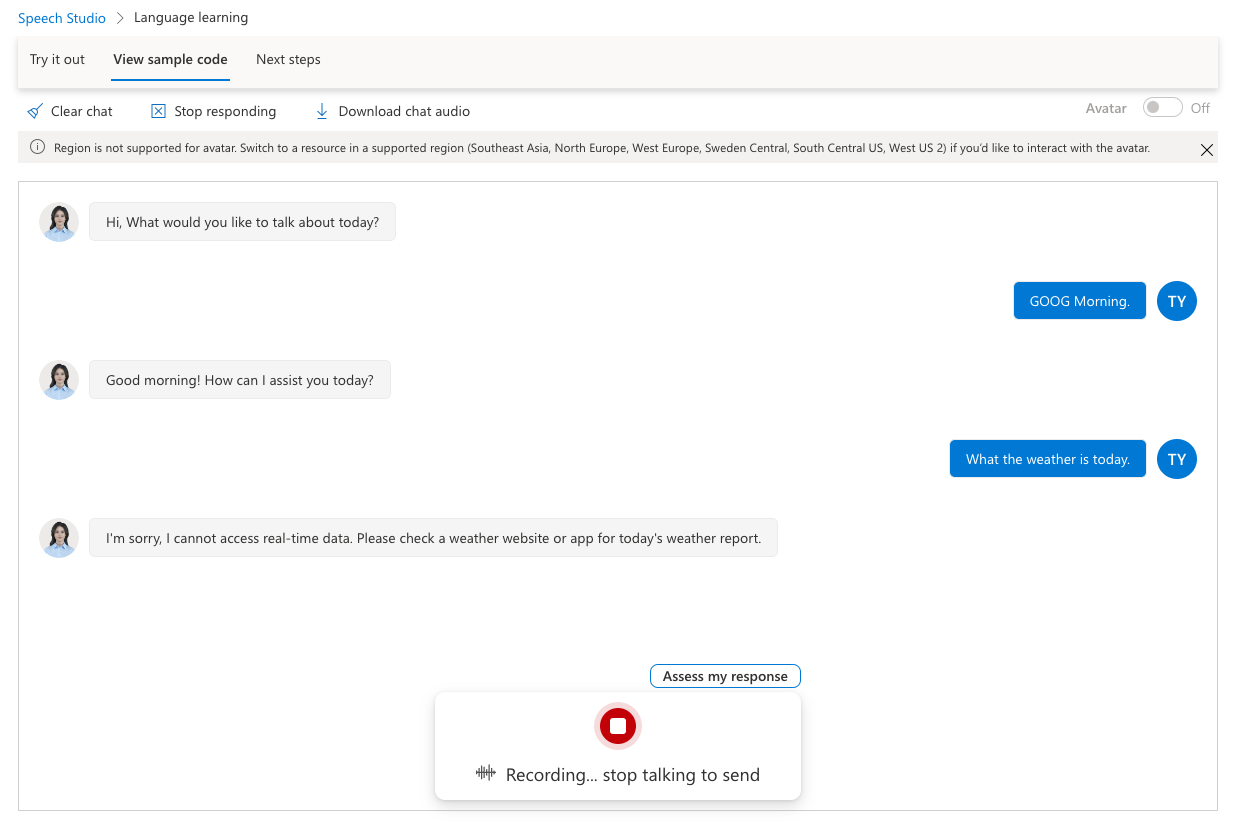
終了時には、スコアが表示されます。
結果が良かったものを貼り付けておきます。
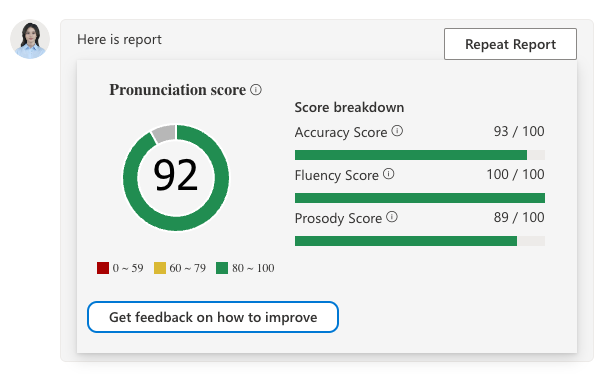
将来は英語のスピーキングテストの本試験を、AIが実施することになるかもしれません・・。人間の試験官を、各試験会場に複数貼り付けるより、公平性が保たれそうです。
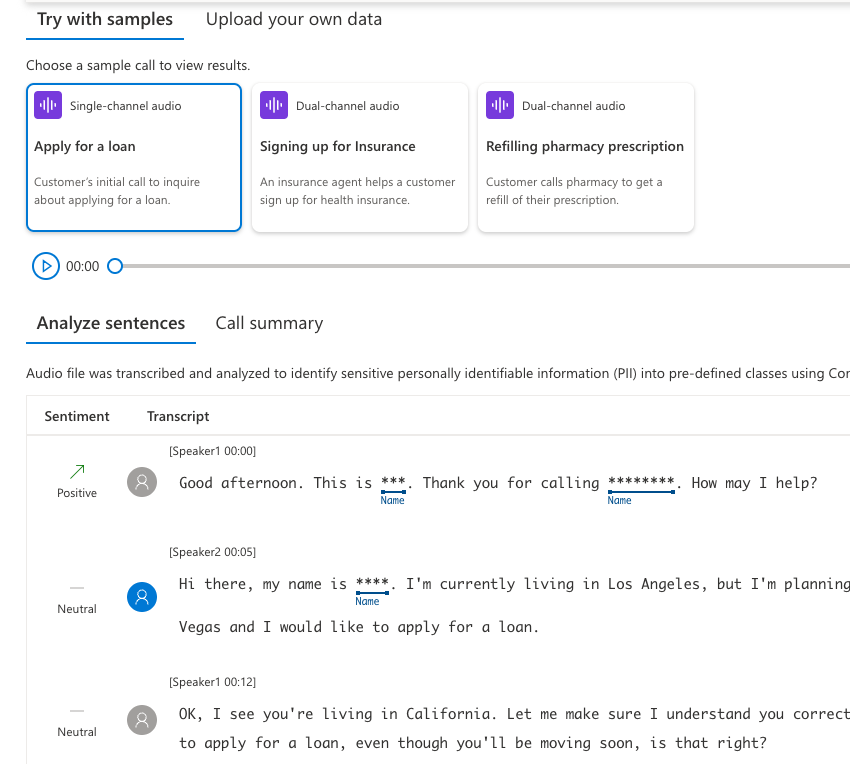
Post call transcription and analytics
コールセンターの録音データを元に、文字起こし、センテンスごとのポジネガ評価、個人情報のマスキング、要約をしています。