はじめに
以前この記事で紹介した通り、Power Virtual Agents を使用して Azure OpenAI Service の ChatGPT と連携することが出来ます。
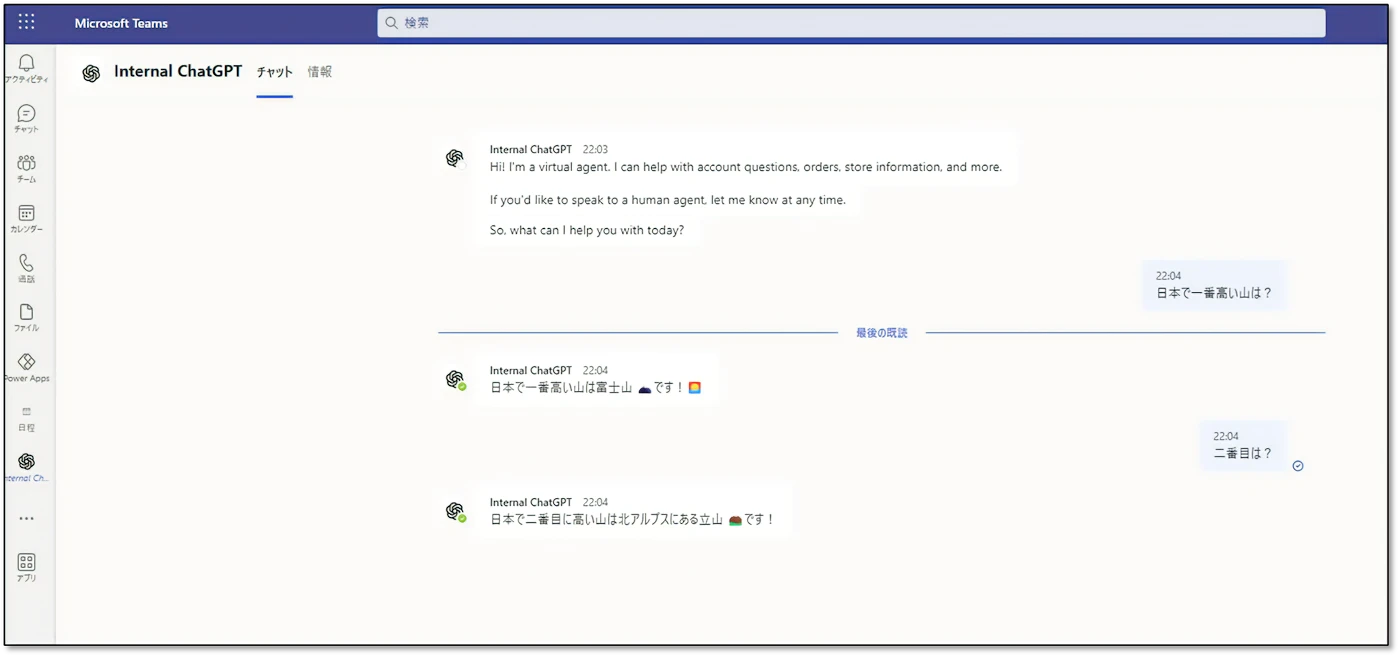
短期間で実装できることや、構築コストを削減できる等のメリットがありますが、会話の履歴が長くなった際、要求トークン数が増えてしまうという懸念があります。
Azure OpenAI の最大要求トークン数については以下の情報を参考になさってください。
そのため、今回は、上記記事で紹介したものをベースに、例えば、会話が長く続いていたとしても、直近 3 つの会話履歴のみを保持してプロンプトに渡すような処理を実装する方法について紹介します。
ChatGPT と会話を長く続けていたとしても、最初の方の会話とは文脈が異なるやり取りをしていこともあると思います。そのような際は新規に会話を始めることが望ましいですが、仮にそのような使い方をしていたとしても、バックグランドで直近いくつかの会話履歴のみプロンプトに渡すようにすることで、最大要求トークン数に抵触しにくくします。
なお、Power Virtual Agents のセッションが終了する条件については以下の情報を参考になさってください。セッションが終了した際は、会話履歴は一旦クリアされます。利用者はあまり意識しない部分もあるため、念のため後述するような処理をバックグラウンドで行うことが望ましいと考えます。
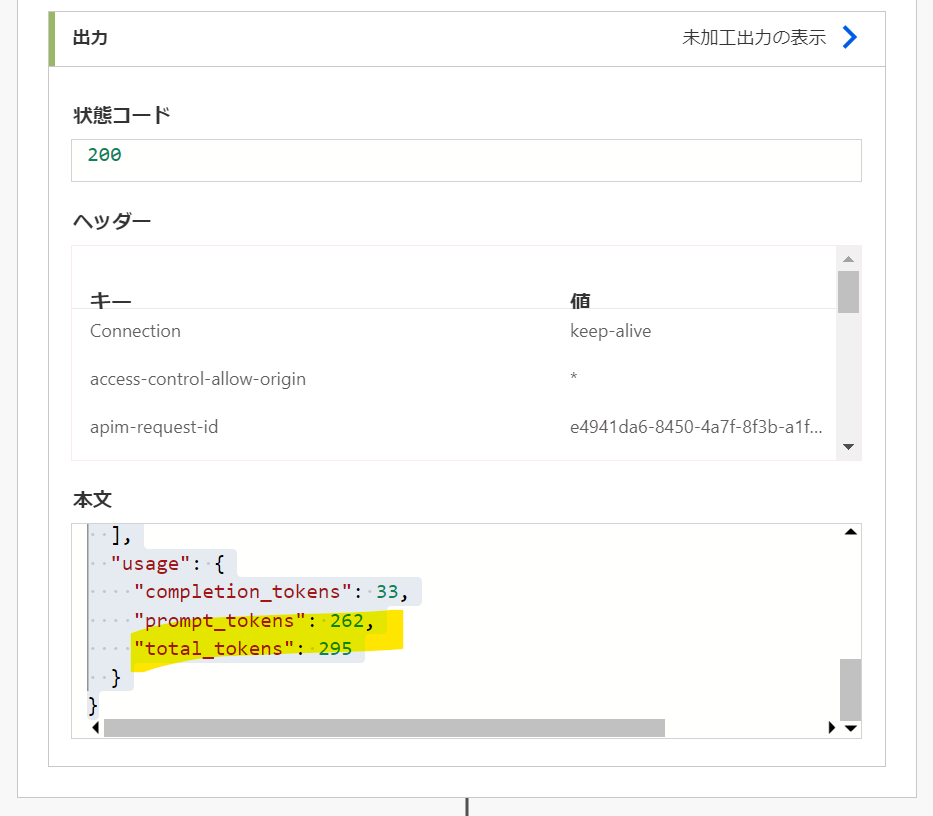
それ以外では、以下のような "total_tokens" をベースに、一定のトークン数を超えたら、直近 3 つの会話履歴のみを保持してプロンプトに渡すようなアプローチも考えられます。
裏ではそのような動きをしつつ、ユーザーには文脈を読んで回答しているように見せる感じでしょうか。
実装
まず、全体像としては以下のような感じです。前回の記事で紹介した内容の説明については割愛し、変更点のみ紹介いたします。
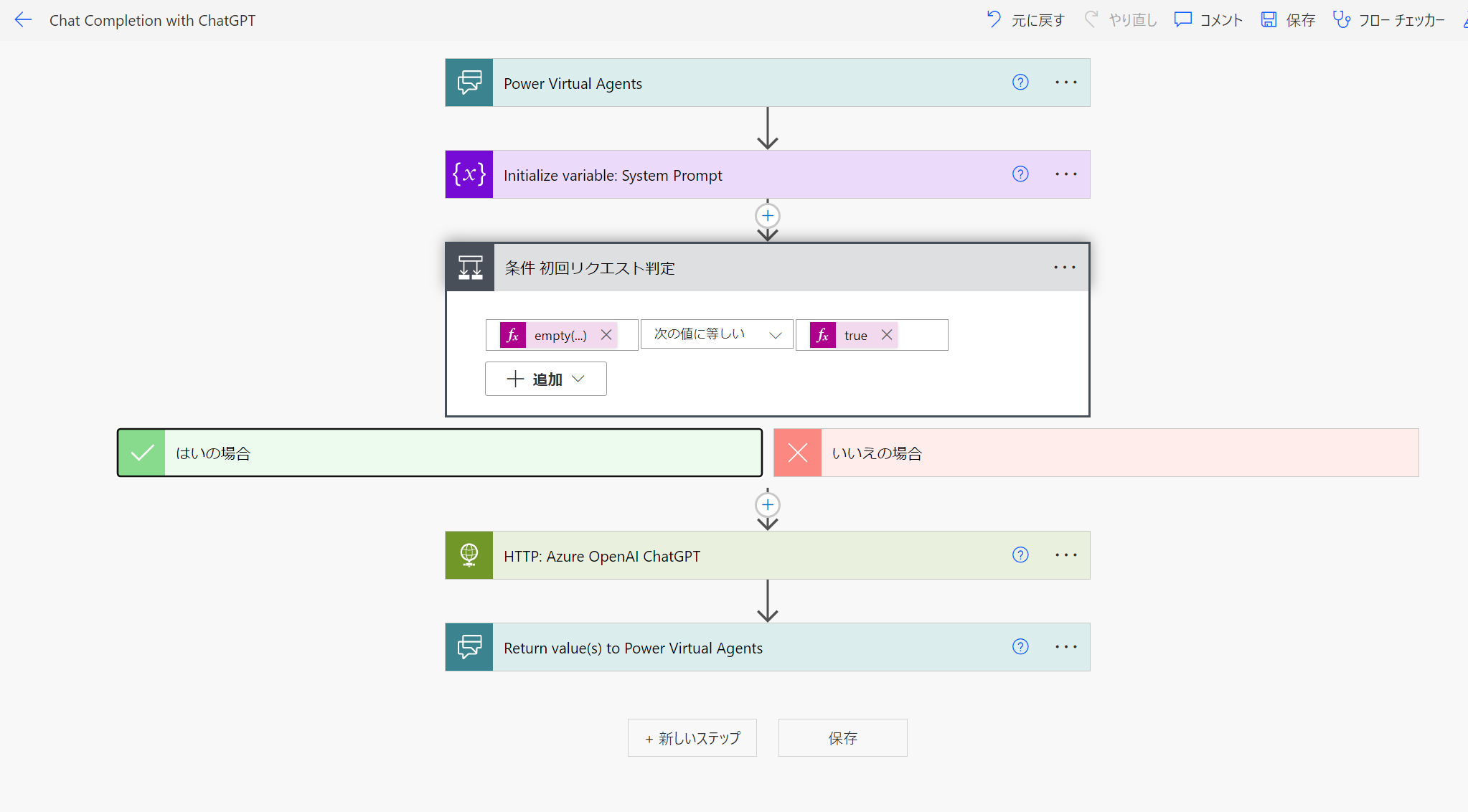
初回リクエスト判定
初回リクエストの際は、会話履歴がなく、後続の処理が不要になるため、以下のような条件式を書きます。
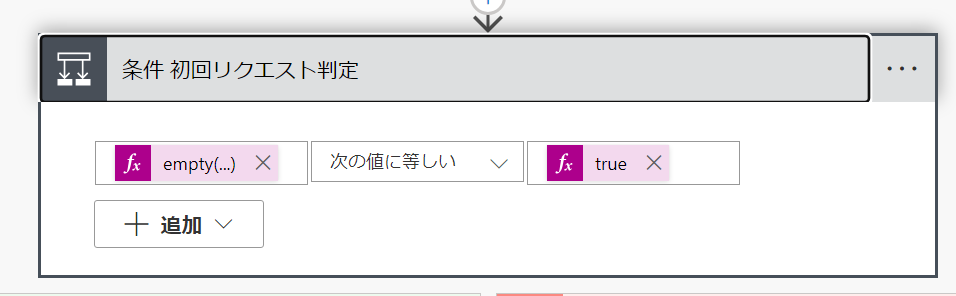
初回リクエストの場合は、以下の FullDialog が空のため、以下のような条件式を書きます。
empty(triggerBody()['text_1'])
直近 3 つの会話履歴のみ保持する
こちらが処理のメインとなります。今回は、直近 3 つの会話履歴のみ保持するようにしています。

まず、入力値が文字列のため、以下のような式で配列に加工します。
json(concat('[', replace(triggerBody()?['text_1'], '}{', '},{'), ']'))
会話が 3 回以上続いているかどうかの判定は以下のような感じで、配列の長さを元に判定します。質問と回答があるので、配列の長さが 6 より大きい場合は会話が 4 回以上になっていると判断します。
length(outputs('作成_配列変換'))
「はい」の場合の処理は以下のような感じです。

skip(outputs('作成_配列変換'), sub(length(outputs('作成_配列変換')), 6))
skip 関数は、先頭から任意の数の要素を削除する関数のため、配列の長さから 6 を引いた数の要素を削除する感じになります。例えば、以下のような入力値の場合の出力値は以下のような感じになります (8-6 で最初の会話が履歴が削除されています)。
■入力値
[
{
"role": "user",
"content": "日本で一番高い山は?"
},
{
"role": "assistant",
"content": "富士山🗻が日本で一番高い山です!👍"
},
{
"role": "user",
"content": "二番目は?"
},
{
"role": "assistant",
"content": "二番目に高い山は北海道にある「旭岳🗻」です!🏔️"
},
{
"role": "user",
"content": "3番目は?"
},
{
"role": "assistant",
"content": "日本で3番目に高い山は、中部山岳国立公園に位置する「北アルプス🗻」の最高峰、槍ヶ岳🏔️です!"
},
{
"role": "user",
"content": "4番目は?"
},
{
"role": "assistant",
"content": "日本で4番目に高い山は、南アルプスに位置する「鳳凰三山🏔️(御嶽山、伊吹山、蓼科山)」の最高峰、御嶽山🗻です!"
}
]
■出力値
[
{
"role": "user",
"content": "二番目は?"
},
{
"role": "assistant",
"content": "二番目に高い山は北海道にある「旭岳🗻」です!🏔️"
},
{
"role": "user",
"content": "3番目は?"
},
{
"role": "assistant",
"content": "日本で3番目に高い山は、中部山岳国立公園に位置する「北アルプス🗻」の最高峰、槍ヶ岳🏔️です!"
},
{
"role": "user",
"content": "4番目は?"
},
{
"role": "assistant",
"content": "日本で4番目に高い山は、南アルプスに位置する「鳳凰三山🏔️(御嶽山、伊吹山、蓼科山)」の最高峰、御嶽山🗻です!"
}
]
リクエスト部分
以下のリクエスト部分も少し変更します。3 回以上会話していない場合としている場合で条件分岐しています。

json(
if(
empty(triggerBody()?['text_1']),
concat(
'[{"role": "system","content": "',
variables('System Prompt'),
'"}, {"role": "user","content": "',
triggerBody()?['text'],
'"}]'
),
if(
empty(outputs('作成_直近3つの会話履歴を取得')),
concat(
'[{"role": "system","content": "',
variables('System Prompt'),
'"}, ',
triggerBody()?['text_1'],
' {"role": "user","content": "',
triggerBody()?['text'],
'"}]'
),
concat(
'[{"role": "system","content": "',
variables('System Prompt'),
'"}, ',
replace(replace(string(outputs('作成_直近3つの会話履歴を取得')), '[', ''), ']', ''),
', {"role": "user","content": "',
triggerBody()?['text'],
'"}]'
)
)
)
)
まとめ
今回は、Power Virtual Agents を使用して Azure OpenAI Service の ChatGPT と連携する際、会話履歴の保持を制御する方法について、直近 3 つの会話履歴のみを保持してプロンプトに渡す例を元に説明しました。
無限に会話履歴を保持することはあまり処理効率がよくないことや、最悪、最大要求トークン数に達してしまう可能性もあるため、バックグラウンドで何かしらの制御をする需要はあると思うので、少しでもその観点での参考になれば幸いです。