はじめに
例えば、あるシステムに対して、直接 Power BI や Dataverse のデータフロー、または、Power Apps や Power Automate のコネクターで接続ができない場合があるとします。
この場合、該当のシステムから一旦データを csv や Excel に対してエクスポートし、そのデータを活用する方法がございます。

しかし、元のデータが定期的に更新される場合、その差分をどう取り込めば良いのか、毎回手動で取り込むのは大変といったことで悩むこともあると思います。例えば、上記の図のように、毎月、その月のデータのみ含んだ csv ファイルがエクスポートされるみたいなときです。
そのため、今回は、以下のような条件を満たしていることが前提ですが、こちらの作業を効率化する方法を、Power BI での例や Dataverse での例を元に紹介します。
- 該当のシステムから定期的に Excel や csv のファイルを別ファイルとしてエクスポートする
- その際、ファイル名は異なるもののデータの形式は同じ
Power BI で SharePoint のフォルダー内に存在する Excel ファイルを元にレポートを自動更新する
レポートの元となる Excel ファイルを SharePoint のフォルダーなどのクラウド上に置き、Power BI でスケジュール更新しようと思います。
Power Autoamte でリストにデータを取り込むフローを作成し、SharePoint リストのデータをマスターにする方法も考えられますが、毎回ファイルが異なることなどから、色々考慮して作り込む必要があります。また、データの行数が多い場合、API 要求数を気にする必要があり、処理に時間を要す可能性もあります。
もしくは、SharePoint リストには取り込まず、マスターとなる Excel ファイルをテーブル化しておき、そこに手動で行を追加し、データフローで同期するというアプローチも考えられますが、毎回 Excel ファイルを編集する必要があるため、少し効率悪いと思います。
データを取得から、SharePoint フォルダーを選びます。

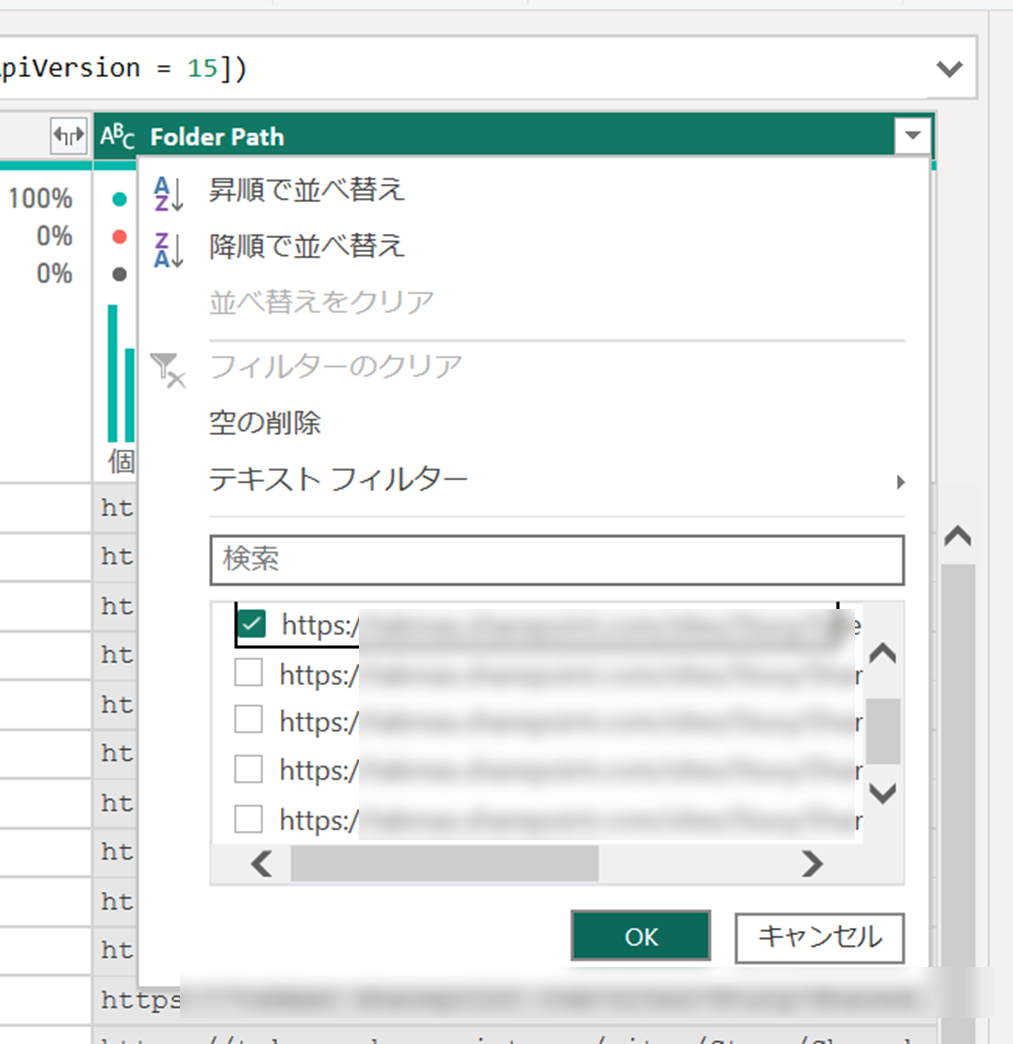
一旦、サイト内の全てのドキュメントライブラリ内のファイルが取り込まれるので、該当のファイルが含まれているフォルダーでフィルターをします。
その上で、ファイルを結合します。
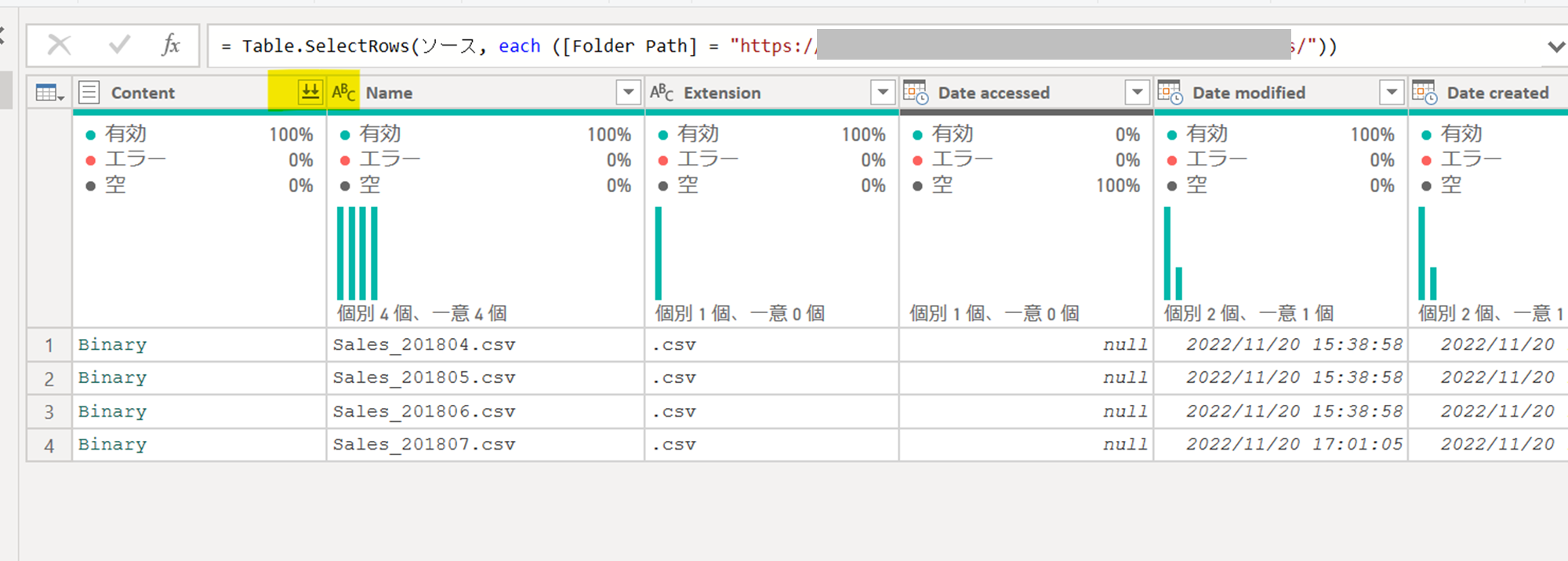
必要に応じてモデリングをします。一旦、行数だけ表示させます。

該当のSharePointフォルダーにファイルを追加します。データを更新すると、行数が増えています

Dataverse のデータフローで SharePoint フォルダー内の csv ファイルを元にデータを自動更新する
先に、受け皿となるテーブルを作成しておきます。ChatGPT にテストデータを作成してもらい、Excel ファイルにしてアップロードしてサクッと作成しました。


SharePoint 側には、以下のようにいくつか csv ファイルを格納しておきます。

それでは、データのインポートを行います。以下のように、データの種類で SharePoint フォルダーを選択します。
最初は SharePoint サイト内の全てのファイルが表示されるため、フォルダーでフィルターをします。
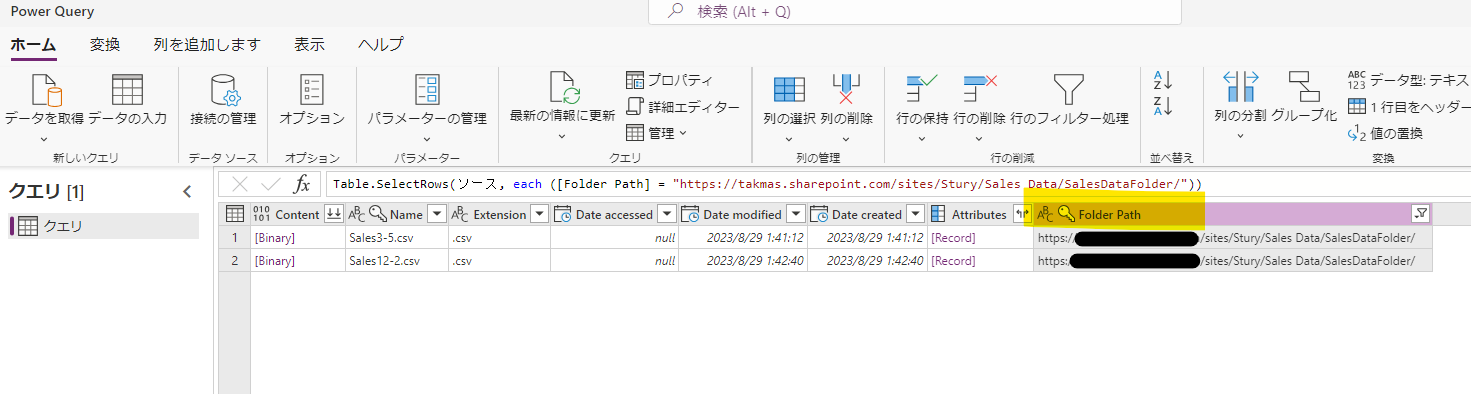
ファイルを結合します。
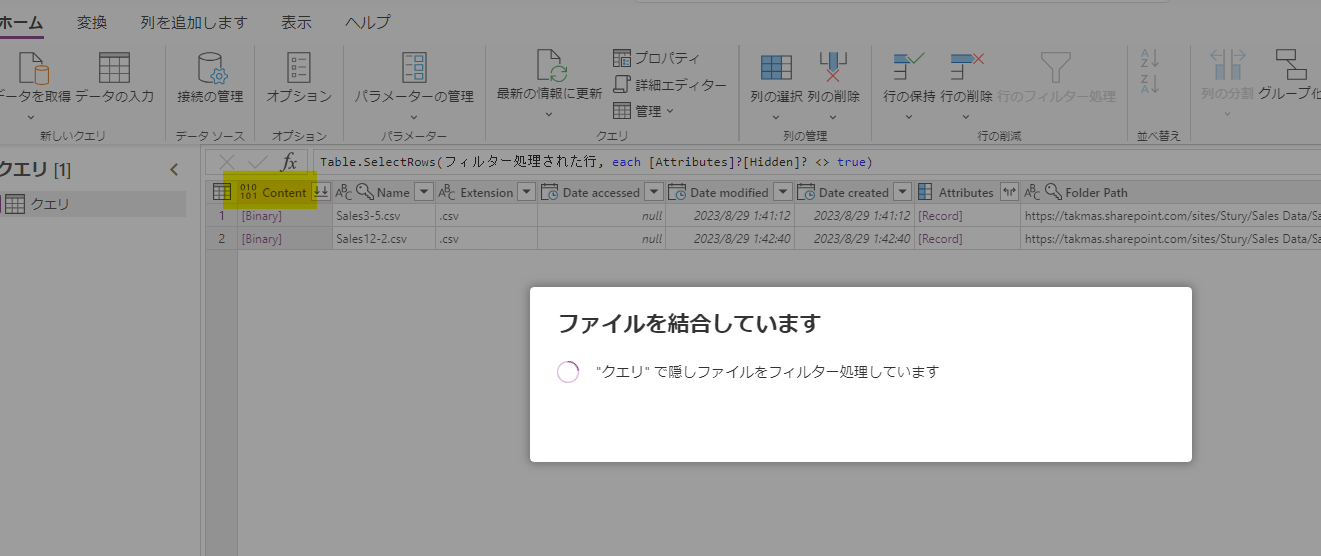
今回は、特別加工はせずに先に進みます。

列のマッピングをして公開します。

本当は複数テーブルが存在したり、キーを設定したりすると思いますが、今回はその辺は省きたいと思います。この辺については以下の記事も参考にしてください。
最新の情報に更新し、データが取り込まれたことを確認します。

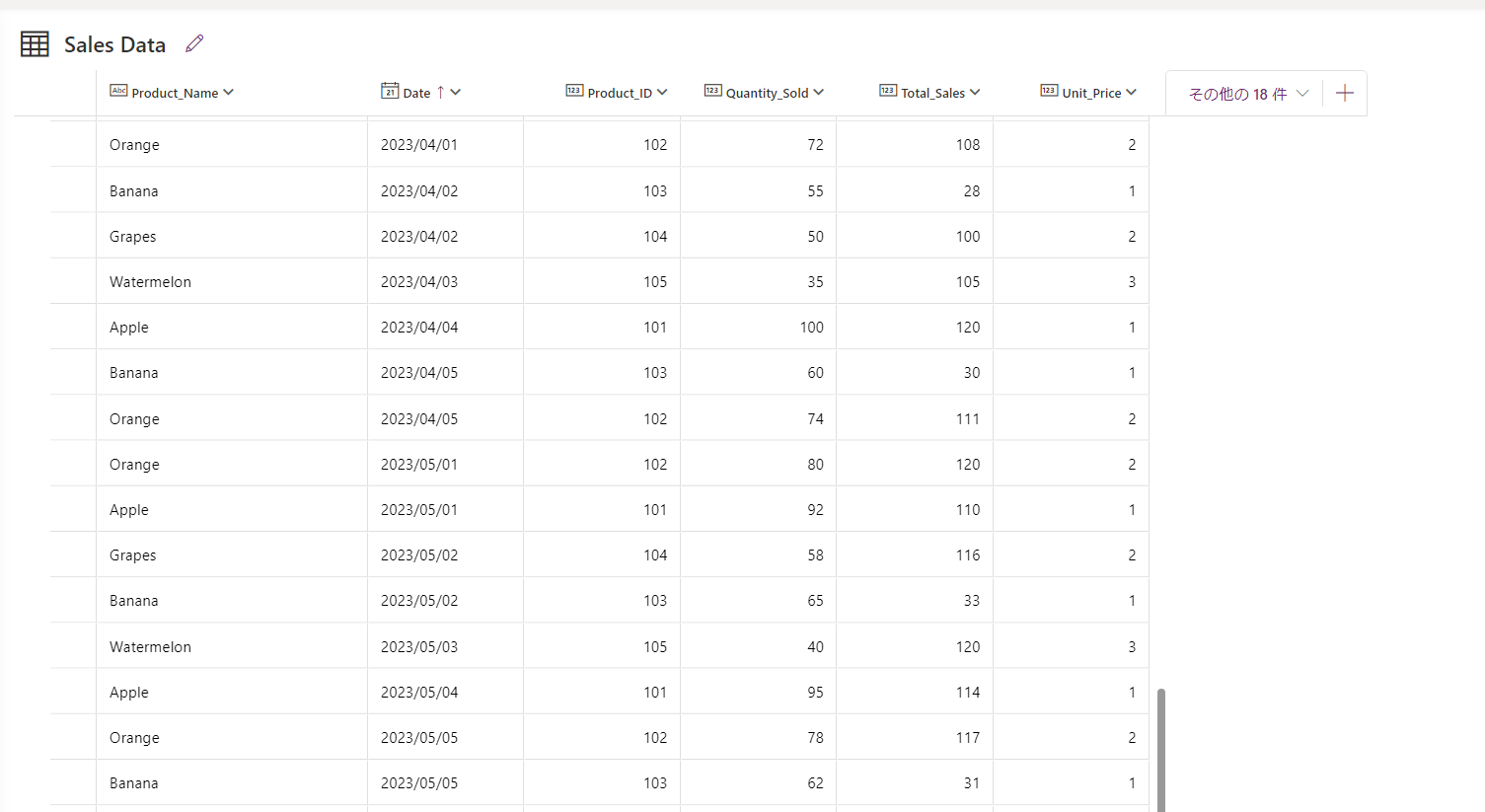
SharePoint 側に csv ファイルを追加します。もう一度データフローを動かすと以下の 6 から 8 月分のデータが取り込まれる想定です。

最新の情報に更新します。もちろん、自動によるスケジュール更新でも良いですし、コネクターのアクションで更新をすることも出来ます。
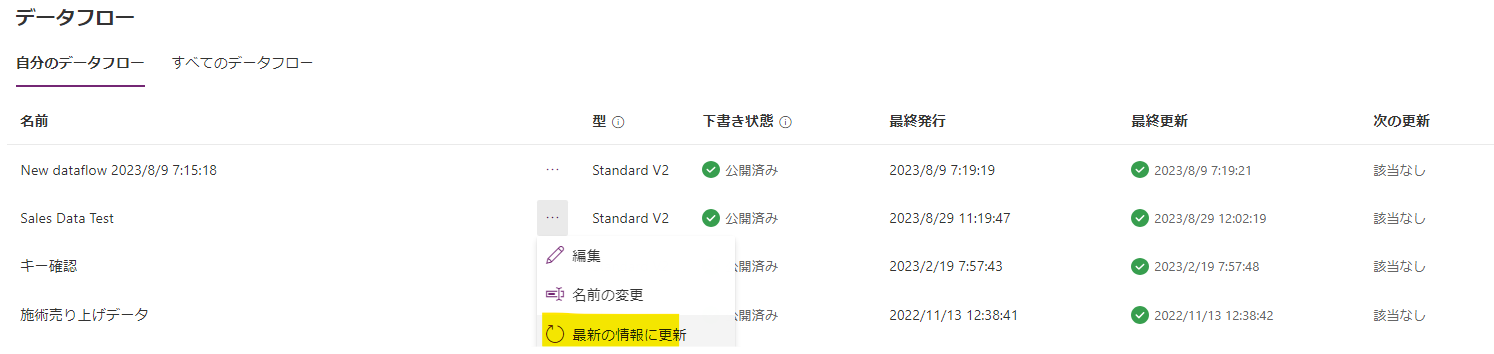

フォーマットが同じ 6 から 8 月分の csv ファイルをフォルダーに格納しただけですが、自動でデータが取り込まれました。
まとめ
今回は、データフローで SharePoint フォルダ内に存在する複数のファイルを取り込む方法について紹介しました。
データの元に直接接続出来ることが望ましいですが、何らかの理由でそれが難しいものの、同じデータ形式のファイルを定期的にエクスポート出来る場合は、紹介した方法で少なからず効率化出来ると思いますので、参考にしていただけると幸いです。
なお、SharePoint のフォルダーにファイルを格納するまでについては、該当システムからの csv や Excel ファイルのダウンロード作業含めて RPA で自動化することをご検討いただくのが良いかと思います。