注記: re:Invent2019でLambda streamアクセス、エラーハンドルの仕方にupdateが入っております。
起動についてはこちら、エラーハンドルはこちらなど、update情報が落ち着いた後、こちらの記事をupdateしようと思いますので、updateが入っている前提で読んでいただければと思います。
はじめに
AWS Lambdaの必要な数を設計するときに、同期/非同期/streamの呼び出しパターンがあるのは、ご存知でしょうか?公式情報はこちら
同期型はイベント駆動型というと理解が早いでしょうか? API Gateway/S3/CloudTrailをトリガーにした場合の呼び出し方法です。
stream型データ= kinesis streams/DynamoDB Streamsをトリガーにした場合です。
同期型の場合、利用量が増えてくるとAWS Lambdaの同時起動数を増やす必要があります。この点は皆さん理解されていることが多いと思います。
ここでは意外に知られていないstream処理(Kinesis streams / DynamoDB streams)をLambdaで処理する時のメリットと情報を整理しておきます。
追記: serverlessの解説ページが作られております。こちらデータ設計・エラー制御・監視/追跡・再利用の項目のlink 開発者におくるサーバーレスモニタリングというところにもまとめています。
非同期/stream型の処理
公式ドキュメントには以下の記載があります。
Lambda 関数をサブスクライブして、Amazon Kinesis ストリームからレコードのバッチを自動的に読み取り、ストリームでレコードを検出した場合にそれを処理できます。AWS Lambda は、新しいレコードを検出するために定期的 (1 秒に複数回) にストリームをポーリングします。
ということは、Lambdaには複数件のデータが取れることを示しています。
さらに、必要な同時実行Lambdaの数はshardの数に依存します。
試してみる
- Kinesis streamsの作成
- テストプログラム配置(EC2想定)
- Lambdaの作成
- テストプログラム実行/確認
という流れです。
kinesis streamsの作成
メニューからkinesisを選択して、テスト用のkinesisを作成します。shard数は1で、stream nameは任意で設定して、Createを押下。
テストプログラム配置
kinesis streamsへデータアップロードするpythonプログラムを配置します。
randomな数値と時刻、シーケンスIDを適当に作成し、JSON化してkinesisにuploadするものです。
ここではEC2の作成方法、aws関連の初期セットアップの手順は省きます。
kinesis stream名の<YOUR_KINESIS_STREAMNAME>部についてはご自分の環境に合わせて修正してください。
import sys
import random
import time
import json
import boto3
client = boto3.client('kinesis')
def dummy_data():
BaseTmp = 20
dummyTmp = BaseTmp + random.randint(-5,5)
return dummyTmp
def put_kinesis(json):
try:
res = client.put_record(
StreamName = 'YOUR_KINESIS_STREAMNAME',
Data = json,
PartitionKey = 'test'
)
print res
except Exception as e:
print 'Kinesis put record excption'
print e.message
sys.exit
print '----------start-------------'
for i in range(200):
try:
#fake data
dummy = {}
dummy['ID'] = i
dummy['Tmp'] = dummy_data()
dummy['TimeStamp'] = int(round(time.time()*1000))
put_kinesis(json.dumps(dummy))
#time.sleep(1)
except Exception as e:
print 'Exception exit'
print e.message
sys.exit
AWS Lambdaの設定
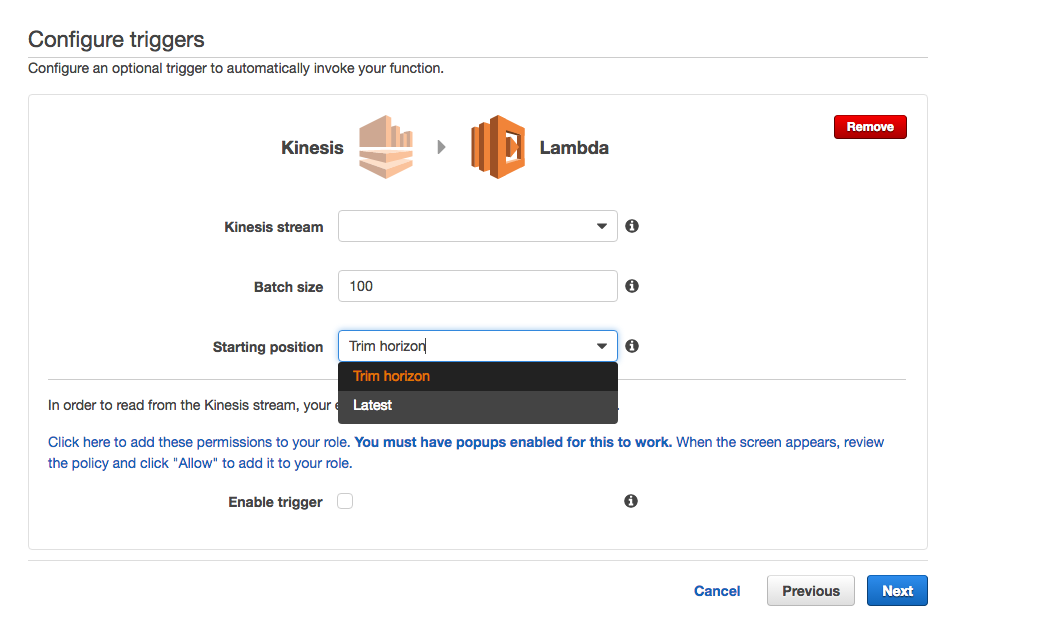
Lambdaのメニューから、blueprintは使いませんのでskip押下後、イベントにkinesisを設定し Next

次の画面で、作成したkinesisのstream名を入力し、Batch sizeはdefaultで100(※1)、Starting postionにTrim horizon(※2)
※1:一回の処理で受け取るイベントの最大数
※2:Trim/古い方から順番、Latest/最新から順番 でデータを取得します。
エンジンをpythonにして、以下のLambda用コードを貼り付けます。
roleにはkinesisのread権限を付与しています。以下2つ
AmazonKinesisReadOnlyAccess
AWSLambdaKinesisExecutionRole
以下のプログラムは、単純にLambdaがeventとして受け取った kinesis dataの件数とデータをそのまま表示するものです。
from __future__ import print_function
import base64
import json
def lambda_handler(event, context):
print ('Loading function')
cnt = len(event['Records'])
print ('Get record count:')
print (cnt)
for record in event['Records']:
# Kinesis data is base64 encoded so decode here
payload = base64.b64decode(record['kinesis']['data'])
print("Decoded payload: " + payload)
return 'Successfully processed {} records.'.format(len(event['Records']))
実行結果
EC2から、先程設置したテストプログラムを実行します。
$ python dummyData_upload.py
上記のままなら、200件のデータがkinesis putした結果が表示されます。不要ならコメントアウトしておいて下さい。
Lambdaのmonitorから実行結果を確認
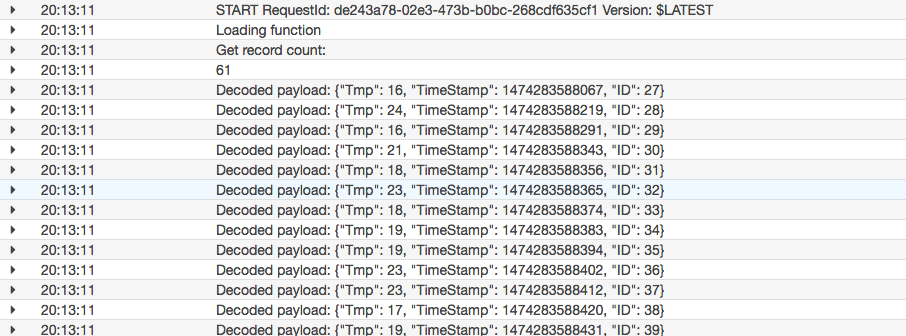
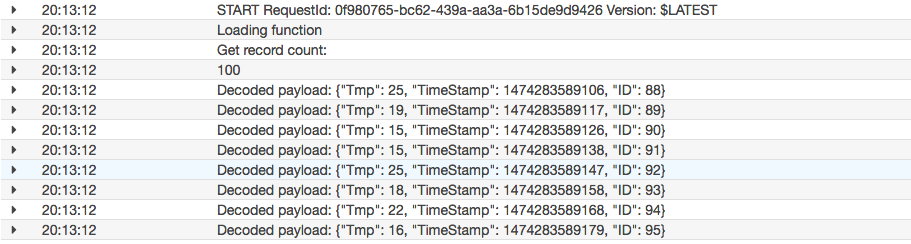
200件のデータpushに対して、4回のLambdaコールが発生しています。
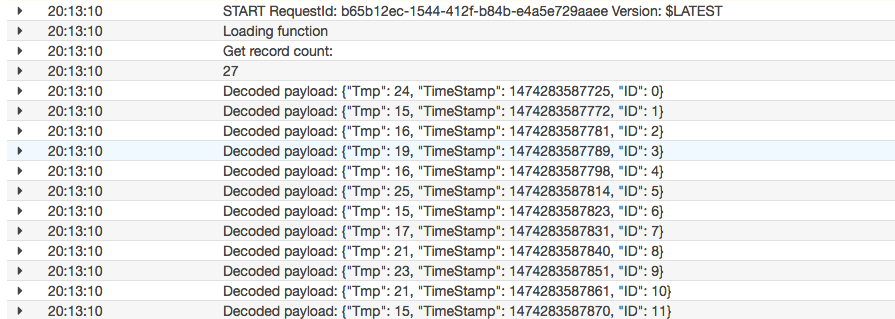
実際の取得がどうなっていたかというと、一回目のポーリングのタイミングで27件、二回目のポーリングのタイミングで61件、三回目で一回で取得する限界の100件、と言った感じでイベント単位で複数のLambdaが起動するのではなく、一回のLambda起動でstreamデータを逐次読んでいることがわかります。
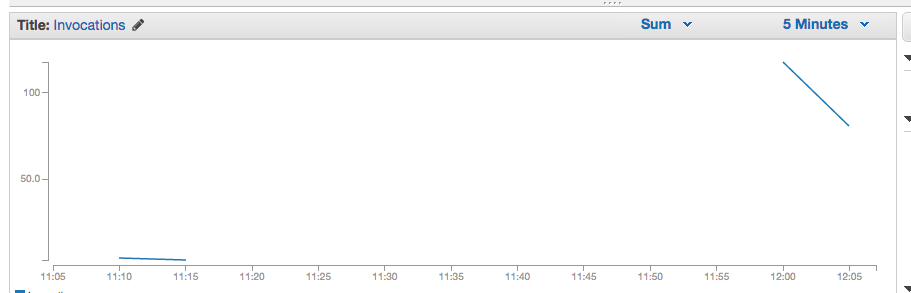
kinesisへのアップロードサンプルのsleepのコメントアウトを解除すると、kinesisへのuploadに一秒のwaitが入ります。
この場合、ポーリングの間隔以上にwaitが長いので、約200回の呼び出しになるかと思いますが、これも逐次で処理されているので、Thresholdに達することはありません。
ログはこんな感じ
まとめ
というわけでkinesis streams経由でLambda起動をするとLambdaの起動がどう動くのかを可視化してみました。
アーキテクチャ上、裏側にRDBなどのコネクション数の制約があるものなどにワンクッションとしてkinesisを置くとDB connection数との関係がスッキリするかと思います。
データupload数が多くなった場合には、shardを分割することでLambdaの実行起動数を増やすことができるので、kiensisのshardを分割できるような設計を考えておくといいかと思います。
逆に言うと同期型(イベント型)を利用する場合は、Lambdaの後ろ側にあるシステムもイベント数に応じてスケールできること(DynamoDBやS3をつかうなど)や、API−Gatewayでスロットリングを設定もしくはエラーが発生してもよい設計などが必要になります。
何れにしても、Lambdaを利用する場合はThrottled invocationsの監視を忘れずに。
kinesisベースのLambdaの設計には、当然kinesisの制約/上限もご理解をお願いします。
Shard数/Lambdaの関係についてはよくある質問にもあります。
Q: AWS Lambda は Amazon Kinesis ストリームおよび Amazon DynamoDB ストリームからのデータをどのように処理しますか?
AWS Lambda 関数に送られる Amazon Kinesis ストリームおよび DynamoDB ストリームのレコードは、シャードごとに厳密にシリアル化されます。つまり、Lanbda で同じシャードに 2 つのレコードが置かれた場合、最初のレコードに対する Lambda 関数の呼び出しは、2 つ目のレコードに対する呼び出しより前に実行されることが保証されます。あるレコードに対する呼び出しがタイムアウトになった場合、またはその他のエラーが発生した場合、Lambda は成功するまで(またはレコードが 24 時間の有効期限切れになるまで)次のレコードに移動しません。シャードの異なるレコード間の順序は保証されず、各シャードの処理は並行して行われます。
注意事項
そこそこ読まれている記事なので注意事項を明確に付記します。上記にある、
エラーが発生した場合、Lambda は成功するまで(またはレコードが 24 時間の有効期限切れになるまで)次のレコードに移動しません
はプログラム実装上で、問題となるケースがあります。想定しているデータのレコードタイプや項目を厳格にチェックして、ゴミデータのようなものを拾った際に例外処理が甘く、exceptionなどでLambdaが異常終了すると、データの読み出しが再度同じ箇所から実行され、同じゴミデータを読んで異常終了と処理が進まずにloopしてしまいます。このために想定外のデータを拾った場合には、例えばcloudwatchへわかりやすくErrorとして表示し、プログラム内では正常処理としてバッチサイズ分のデータを読み出し、Lambdaを正常終了させる必要があります。
例えば上記のサンプルプログラムにおいては、dictのkeyアクセスをしていますが、key値が存在しない場合に、Exceptへ処理が流れLambdaがErrorとなります。
ということで、処理を逐次進めていくためにはLambdaは正常終了させる必要があります。エラーデータはエラーとして検出できる仕組みを検討しLambdaの処理は正常終了させてください。
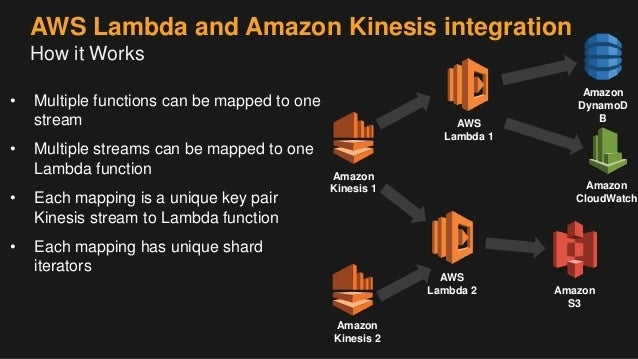
1-kinesis streamに複数のLambda(追記)
2017.01.14
1つのkinesis streams に複数のLambdaイベントを発火する場合の話を聞かれるケースが何度かあったので、そちらの情報です。
streamと各Lambdaに於いては、それぞれユニークなイテレータがあるようなので、安心して利用できますね。
情報の元はこちら
免責
本投稿は、個人の意見で、所属する企業や団体は関係ありません。
また掲載しているsampleプログラムの動作に関しても保障いたしませんので、参考程度にしてください。