はじめに
はじめまして、オプティマインドでインターンをしている成川です。
今回お仕事として、 Fireclient というライブラリを作成しました。
このライブラリは Firestore 上のデータを React の Hooks を用いて取得するものです。

実用例
Firestore の /cities/tokyo に存在するドキュメントを React コンポーネントから取得し表示してみます。
Fireclient なら、このデータの取得の部分を1行で書くことができます。
const [tokyo, loading, error] = useGetDoc("cities/tokyo");
<>
{loading ? (
<div>Loading...</div>
) : (
<>
<div>tokyo.id : {tokyo.id}</div>
<div>tokyo.data.name : {tokyo.data.name}</div>
<div>tokyo.data.country : {tokyo.data.country}</div>
<div>tokyo.data.population : {tokyo.data.population}</div>
<div>error : {JSON.stringify(error)}</div>
</>
)}
</>


なぜ作成したのか
まず、オプティマインドではフロントエンドを主に React と Firebase を用いて開発しています。
その中で、React 上で Firestore にアクセスする際には Redux-Saga を使用していました。

しかし、その Redux-Saga 関連のコードの肥大化が問題になっていました。
例えば、Firestore 上の Job という1つのデータを扱うために、
- START_WATCHING_JOBS
- END_WATCHING_JOBS
- UPDATE_JOBS
- CLEAR_JOBS
- UPDATE_JOB
- UPDATE_JOB_SUCCESS
- UPDATE_JOB_FAILURE
という7つの Action を用意し、それぞれに対応する ActionCreator, Reducer を用意していました。
この Job 以外にも扱うデータはいくつかあり、あるページでは Reducer の数が 40 個にまで及んでしまっていました。
このままではメンテナンスが非常に大変になってしまいます。
ライブラリの役割
上記のような問題を解決するため、Fireclient を作成しました。
このライブラリは Redux-Saga の通信部分の役割を代替することができ、
- ページに必要なデータのクエリの宣言的な定義
- スケーラブル、大規模化したアプリケーションにおいても可読性を維持
- View にロジック部分を持ち込まない、シンプルな設計
という考えのもと開発されました。
開発には React 16.8 から実装された Hooks を主に使用しており、コンセプトの部分は GraphQL を用いた Apollo-Client の影響を大きく受けています。

何ができるの?
コードのシンプルさ
React 上で Firestore のドキュメントを取得する際、useState を使ってデータを入れる場所を作っておいて、useEffect 内でデータが取得できたらセットする、という形になると思います。
const [tokyo, setTokyo] = useState(null);
useEffect(() => {
db.doc("cities/tokyo")
.get()
.then(doc => setTokyo(doc.data()));
}, []);
しかし、この手法ではコンポーネント側に db.doc(path).get().then() のようなデータ取得のロジック部分が入り込んでしまっており,
もし取得対象がどんどん増えるとコードの可読性が落ちてしまう原因になってしまいます。
これに対し、Fireclient では同じことを1行で実現することができます。
取得結果の tokyo 、読み込み状態を表す loading 、エラーが発生した場合の error を取ってくることができます。
const [tokyo, loading, error] = useGetDoc("cities/tokyo");
宣言的なクエリ定義
Fireclient はクエリ内容を宣言的に書けることを重視して作られています。
1つのページで Fireclient 上の複数箇所からデータを取得する必要がある場合、FQL (Fireclient Query Language) を用いてまとめて取得することができます。
const fql = {
queries: {
post: {
location: `/posts/${postId}`
},
comments: {
location: `/posts/${postId}/comments`,
limit: 15,
order: {
by: "likeCount",
direction: "desc"
}
},
relatedPosts: {
location: `/posts/${postId}/relatedPosts`,
limit: 5
}
}
};
const [response, loading, error] = useQuery(fql);
const { post, comments, relatedPosts } = response;
このようにすることで、取得内容と View の部分を完全に分離することができるようになったので、コードの可読性を上げることができます。
また、取得対象や order などのオプションが1箇所に集約するので、コンポーネントで Firestore から取得しているドキュメントやコレクションが一目瞭然になります。
State の再利用性
Fireclient では無駄なデータの取得を極力減らすように設計されています。
例えば、あるコンポーネントでリッスン(サブスクライブ)しているデータを、別のコンポーネントで取得しようとしたとします。この場合、リッスンされているデータは最新のものであることが分かっているにも関わらず、再度同じデータをサーバーから取得するのは無駄であると言えます。
このような場合、Fireclient ではリッスンされているデータをそのまま、データを取得しようとした別のコンポーネントに渡すことでサーバーとの無駄な通信をなくしています。
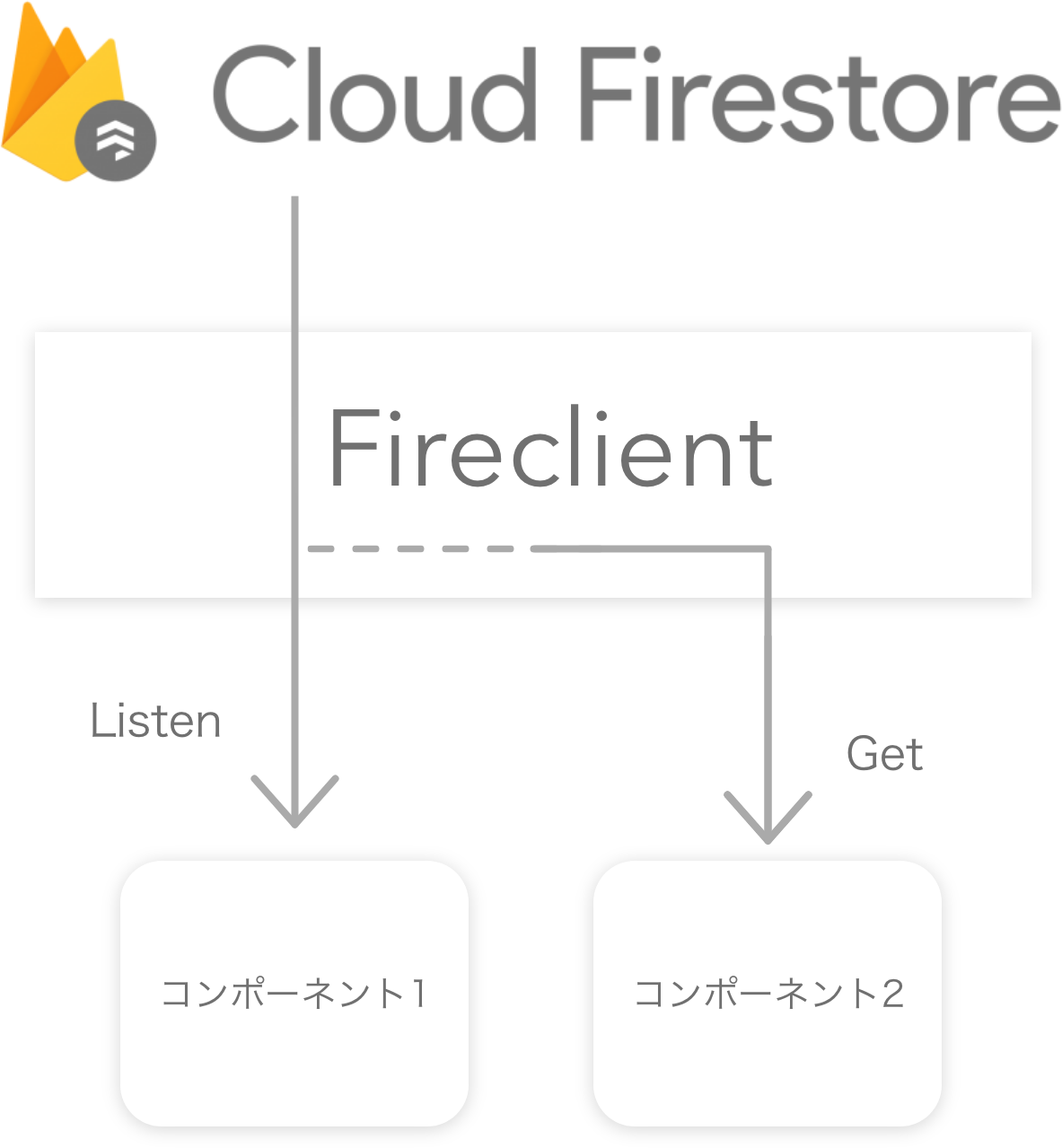
note
厳密にはこの機能は Firebase.js 側にも存在しますが、リッスンされているコレクションに含まれるドキュメントの取得など、対応されていない部分があります。
また、取得するデータの更新頻度が高くないと分かっている場合、useGetDoc や useGetCollection などではオプションで { acceptOutdated: true } を指定することで、保存されたキャッシュを利用してネットワークアクセスを減らすことができます。
カスタム Hooks による様々なタスクへの適応
Fireclient に含まれる useGetDoc や useGetCollection などを組み合わせることで、複雑な処理を 1 つの Hooks として作成することができます。
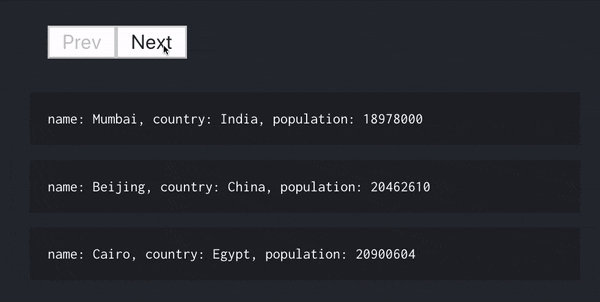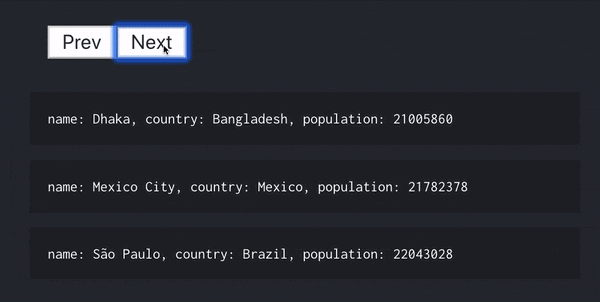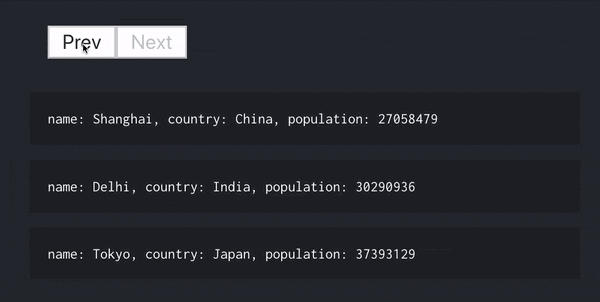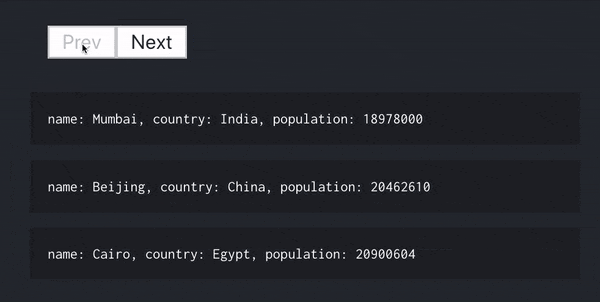
例えば、ページ切り替えを行いたい場合、カスタム Hooks のおかげで次のコードだけで実現でき、ロジックの部分を全てカスタム Hooks で完結させることができています。
populationでソートを行い、3 個ずつ表示させています。
const options = {
order: {
by: "population"
},
limit: 3
};
const [cities, loading, error, prevHandler, nextHandler] = usePaginateCollection(
"/cities",
options
);
return (
<>
<button onClick={prevHandler.fn} disabled={!prevHandler.enabled}>
Prev
</button>
<button onClick={nextHandler.fn} disabled={!nextHandler.enabled}>
Next
</button>
{loading ? (
<div>Loading...</div>
) : (
cities.map(city => (
<div>
name: {city.data.name},
country: {city.data.country},
population: {city.data.population}
</div>
))
)}
</>
);
まとめ
以上 Fireclient の特徴を紹介させていただきました。
より詳しい情報はドキュメントに記載していますので、ご興味あればぜひ御覧ください。