はじめに
この記事で取り上げる内容
- CUDA、cuDNN、TensorRTの簡単なインストール方法
- ROS 2を使用してカメラから画像を取得する方法
- Text to Image (Blip) AIモデルをROS 2に接続する方法
必要なもの
- NVIDIA GPU(VRAM 6GB以上)
- Ubuntu 22.04(ドライバを含む)
ROS 2とは
この記事を実行するために深い理解は必要ありませんが、より詳細な情報は次のリンクを参照してください。
ドライバ、CUDA、cuDNN、TensorRTの簡単なインストール
Autowareのツールを使用する理由
Autowareという自動運転ソフトウェアの環境構築用Ansibleスクリプトを使用すると、簡単で確実に環境を構築できるため、おすすめです。Autowareを使用する目的でなくても、ぜひ試してみてください。
インストールできるもの:
- CUDA
- cuDNN
- TensorRT
- ROS 2
- ROS 2 Dev Tools
- Autoware依存パッケージ
実際の手順
Ubuntuのターミナルを開き、以下のコマンドを実行してください。
-
gitとcurlをインストール
sudo apt install git curl -
Autowareをクローン
git clone https://github.com/autowarefoundation/autoware.git -b main --single-branch -
スクリプトを実行(内容を確認し、質問にはすべて "y" と答えます)
cd autoware ./setup-dev-env.sh -
システムを再起動
これで、nvidia-smiコマンドやnvcc --versionが実行できるようになります。
ROS 2を使用してカメラから画像を簡単に取得する方法
ROS 2を使用すると、カメラなどのセンサーから簡単にデータを取得できます。
ウェブカメラを使用する場合
-
ツールをインストール
sudo apt install ros-humble-v4l2-camera -
カメラを接続して確認
一つ目のターミナルros2 run v4l2_camera v4l2_camera_node二つ目のターミナルros2 run rqt_image_view rqt_image_view終了する場合は、Ctrl+Cを使用してターミナルで停止してください。
起動したウィンドウにカメラからの映像が表示されない場合、または映像が停止している場合は、一つ目のターミナルで実行しているコマンド(ros2 run v4l2_camera v4l2_camera_node)を停止し、再度実行してみてください。
RealSenseカメラを使用する場合
-
ツールをインストール
sudo mkdir -p /etc/apt/keyrings curl -sSf https://librealsense.intel.com/Debian/librealsense.pgp | sudo tee /etc/apt/keyrings/librealsense.pgp > /dev/null echo "deb [signed-by=/etc/apt/keyrings/librealsense.pgp] https://librealsense.intel.com/Debian/apt-repo `lsb_release -cs` main" | \ sudo tee /etc/apt/sources.list.d/librealsense.list sudo apt-get update sudo apt-get install librealsense2-dkms librealsense2-utils librealsense2-dev librealsense2-dbg sudo apt install ros-humble-realsense2-* -
カメラを接続して確認
一つ目のターミナルros2 launch realsense2_camera rs_launch.py二つ目のターミナルrviz起動後、「add」ボタン -> 「By topic」タブ ->
/camera/color/image_raw/Imageを選択して「OK」をクリックします。
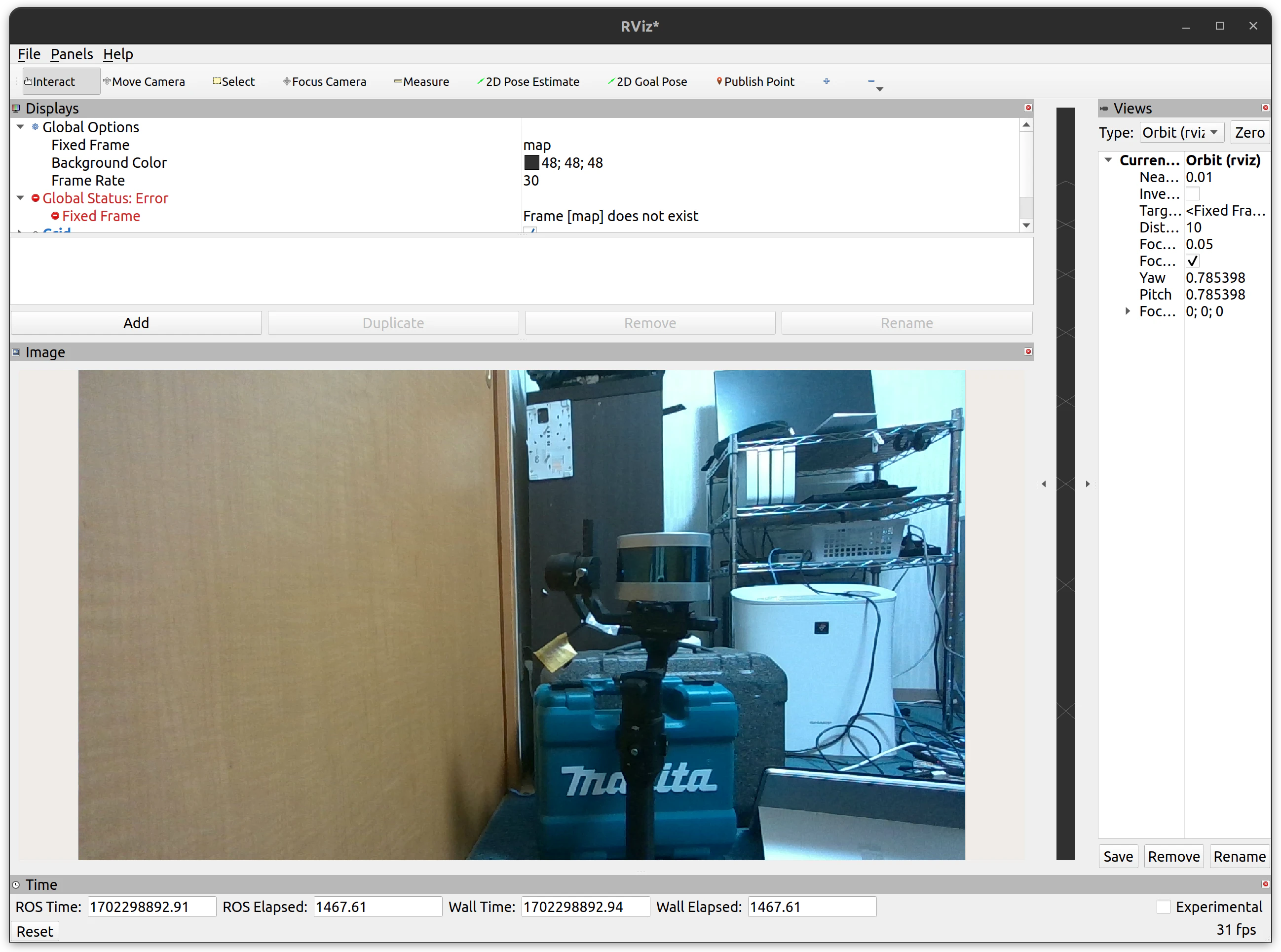
これで映像を表示できるはずです。
Text to Image (Blip) AIモデルをROS 2に接続する方法
環境構築を行います。
mkdir ml_ws
cd ml_ws
python3 -m venv env
source ./env/bin/activate
python3 -m pip install -U torch torchvision torchaudio git+https://github.com/huggingface/transformers accelerate
wget https://gist.githubusercontent.com/TakanoTaiga/eae37b30c34b19fe0d595908bb2a810f/raw/a1465becce2d269b8c236853140680b06a9df6e8/i2t.py
実行するには以下のコマンドを使用します。
python3 i2t.py
:二つ目のターミナル(RealSenseを使用する場合)
ros2 launch realsense2_camera rs_launch.py
ダウンロードしたPythonファイルの32行目を'/camera/color/image_raw',から'/image_raw',に変更します。
ros2 run v4l2_camera v4l2_camera_node
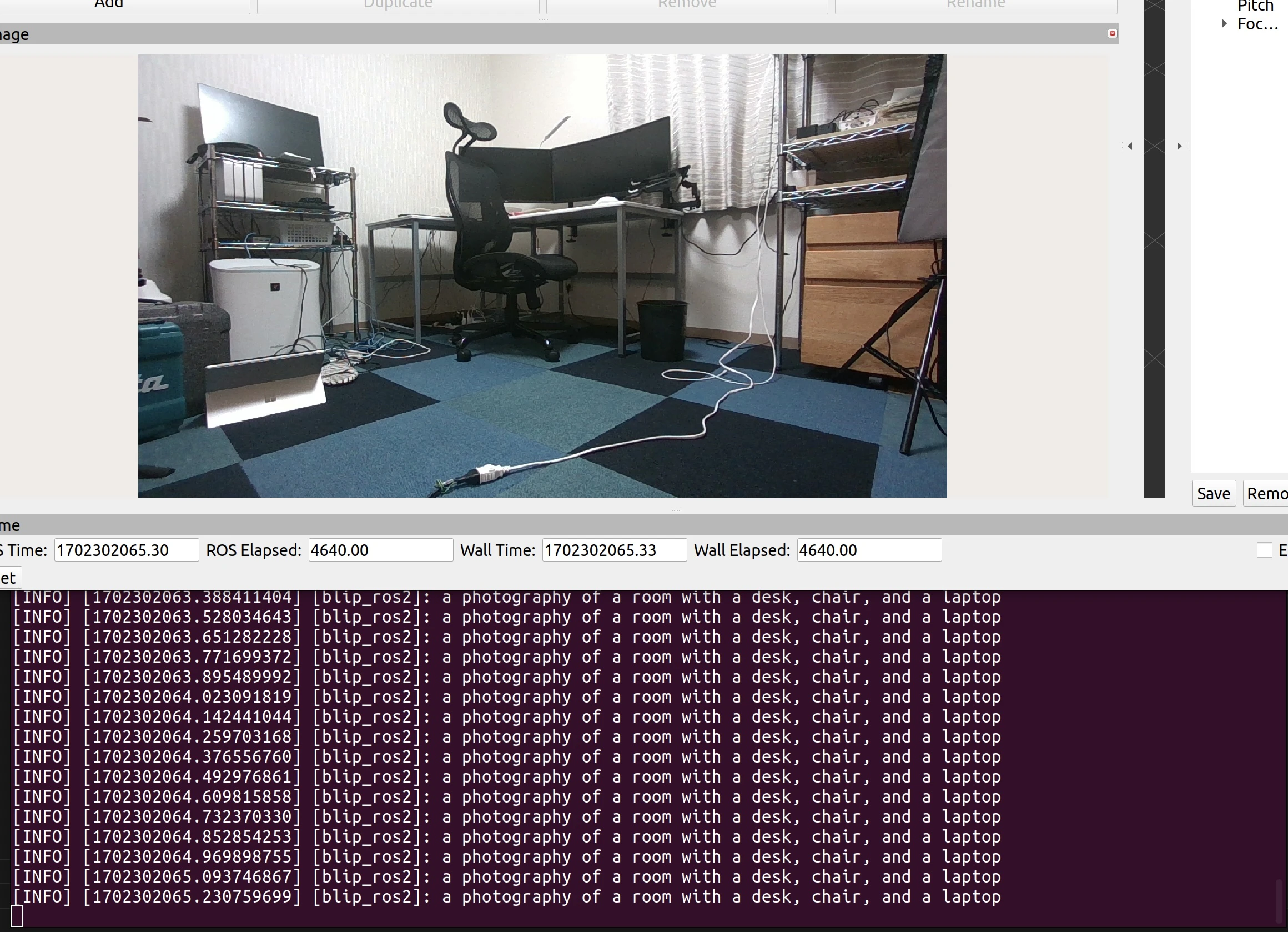
これで、上記の画像のように表示されるはずです。
コードについて
import torch #pytorchをインポートする
from transformers import BlipProcessor, BlipForConditionalGeneration #transformersをインポートする
# 以下ROS2関連
import rclpy
from rclpy.node import Node
from sensor_msgs.msg import Image as rosimg
import cv_bridge
class MinimalSubscriber(Node):
def __init__(self):
# AIモデルの読み込みと展開
self.processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
self.model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large", torch_dtype=torch.float16).to("cuda")
# ROS2の処理
super().__init__('blip_ros2')
self.subscription = self.create_subscription(
rosimg,
'/camera/color/image_raw',
self.listener_callback,
10)
self.subscription
self.bridge = cv_bridge.CvBridge()
def listener_callback(self, msg):
#カメラデータを受けっとた時の処理
cv_image = self.bridge.imgmsg_to_cv2(msg, desired_encoding='bgr8')
text = "a photography of"
#データのセット
inputs = self.processor(cv_image, text, return_tensors="pt").to("cuda", torch.float16)
#推論
out = self.model.generate(**inputs)
self.get_logger().info(self.processor.decode(out[0], skip_special_tokens=True))
def main(args=None):
rclpy.init(args=args)
minimal_subscriber = MinimalSubscriber()
rclpy.spin(minimal_subscriber)
minimal_subscriber.destroy_node()
rclpy.shutdown()
if __name__ == '__main__':
main()
最後に
この記事では簡単に環境構築手順についてまとめてみました。ROS 2を活用することでセンサーデータの取得やAIの応用が簡便に行えるようになります。ROS 2とAIの組み合わせにより、より良い技術ライフを楽しんでください。