はじめに
弊社で運営しているDot to Dotというサービスの一部モジュールで、同時実行性能を求めてSpring WebFluxを採用しています。
従来の実装方式と比べると、特に日本語の情報が少なくとっつきにくいところがあると思いますが、この記事が手助けになれば幸いです。
Spring WebFluxとは?
ノンブロッキングなリアクティブ処理を実装できるSpringです。従来のWeb MVCとくらべて非同期イベントループなのでCPUリソースを無駄にせず、同時実行性能が良くなります。
どれくらい速いの?という話については、こちらの記事が参考になります。
リアクティブなプログラミング基礎
ひとまずは・・・
- 基本はreturnしてメソッドチェーンで一気にやりきる
- ストリームに流れてるデータを意識
- データを変換しつつ後ろに流していくので、あとからあのデータが欲しかったとならないように
- データがなくなると処理が終わる。EmptyとかMonoとかに注意
- こんなことやりたいけどどれ使えばいい?
- 1データはMono、複数データはFlux
- 並列処理はzip、逐次処理はflatmap/map
- データに変更を加えない副作用処理→doOnXX
- ストリームが終わったら別のデータで開始→thenEmpty、thenReturn
- RestTemplateはWebClientに置き換え
- まぁここを見ましょう⇒https://projectreactor.io/docs/core/release/reference/#core-features
順にみていきましょう。
概念
ストリームと呼ばれるデータの流れに対して、処理(operator)を通して、変換後のデータを持ったストリームに変換していくモデルになっています。
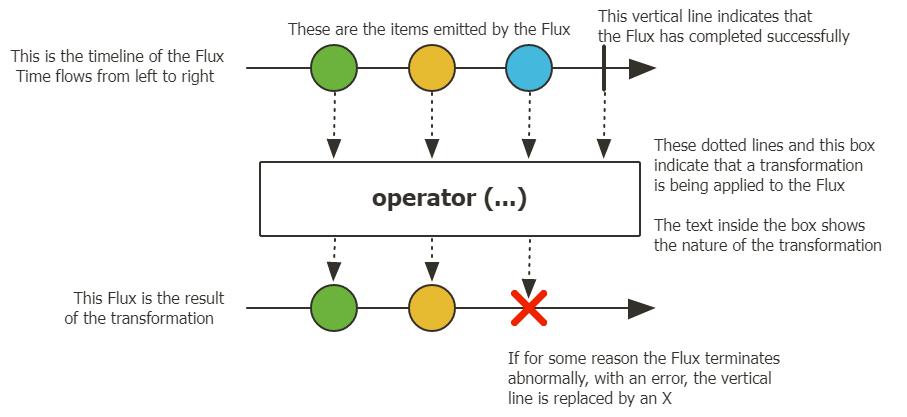
(画像の出典:https://projectreactor.io/docs/core/release/reference/#core-features)
ストリームはsubscribeしてから動く
Mono/Fluxのチェーンは、subscribeが呼ばれたタイミングで初めて実行されます。
Spring WebFluxでは、Controllerの戻り値としてMono/Fluxを返すように実装し、subscribeはSpring側の処理にまかせます。
そのため、Controller処理のステップ時点で実行されるわけではないこと、ストリームのチェーンに登録していないストリームは実行されないことに注意が必要です。
「デバッグ実行ではこの部分通るのに、処理されないぞ???」は慣れないうちはあるある事象です。
// パターン① [ステップを記述した時点で実行されない]
Mono<User> user = Mono.just(userId)
.flatMap( userId -> userList.findUser(userId)); // この時点では処理を定義しただけ
// ユーザーが存在するのでセッションにフラグを設定
session.setAttribute("isLogin", true) // ★ここは同期で処理が動くので、
// ユーザーがいなくてもフラグが設定される
return user;
// パターン② [ストリームに流れないストリームは実行されない]
return Mono.just(someRequests)
.flatMap( req -> {
// ★以下2つのMonoは評価されない(戻り値としてチェーンしていない)
hogeInfo.save(req); // Mono<Void>
fugaInfo.save(req); // Mono<Void>
return createSomeResponse(req); // Mono<SomeResponse> こちらは評価される
}
ストリームをストリームで返す
基本は、入ってきたデータを一つづつ処理して、終わったものから返していくモデルがベストです。なので、ストリームで取得してくるものを待ち受けてしまうとメリットは活かせませんが、かといって、データ毎にI/O処理をするのは逆にI/Oに負荷を与えてしまうことになります。
ただし、こだわりすぎるとロジックの見通しが悪くなるので、適度な関数の分割とトレードオフを意識する必要があります。
[よくない例2]のような実装でも、2行目の取得件数が少ないことが確実であれば、採用しても良いでしょう。
// [よくない例1 / 集約処理のためにwaitが発生する]
return userService.selectUsers() // Mono<List<User>>
// ×集約する=待ち合わせなので全部届かないと以降が処理されない
.flatMap(userList -> {
var corporateList = corporateService.selectCorporate(distinctCorporateIdList(userList));
return convertUsersForDisplay(userList, corporateList);
}); // Mono<List<UserViewModel>>
// [よくない例2 / 1件毎の処理こだわりすぎて、同じ処理が何度も走り、逆に高負荷になる]
return userService.selectUsers() // Flux<User>
// 〇ストリームとして届いたデータから順次処理
.flatMap(user -> Mono.zip(
return corporateService.find(user.getCorporateId())
.flatMap(corporation -> UserViewModel.build(user, corporation)); // ×事業者は被る可能性があるが、全ユーザー分事業者情報を取得している
); // Flux<UserViewModel>
ストリームのデータを意識する
ストリームに流れるデータを変換しつつ先に進むので、あとから元々のデータを参照し直すことはできないので、処理順番や必要なデータを意識してロジックを組む必要があります。
// ユーザーIDからユーザー情報を参照⇒そのユーザーの所属するCorporation情報を取得しようとすると・・・
return Mono.just(userId)
.flatMap(userId -> userService.find(userId)) // Mono<User>
.flatMap(user -> corporateService.find(user.getCorporateId)) // Mono<Corporation>
// ここでデータがMono<Corporation>になってしまっているので、Mono<User>は参照できなくなる
処理シーケンス
よくある実装パターンを記載します。これらの組みあわせでメソッドチェーンを構築していきます。
基本
直列に処理するmap/flatMap
// flatMap … ストリーム(MonoやFlux)が返る処理のとき
userService.findUser(userId) // Mono<User>
.flatMap(user -> userService.findAttributes(user.getUserId()))
// Mono<UserAttributes>
public Mono<UserAttributes> findAttributes(String userId) // ★呼び出してる処理がFluxを返す
// map … 値が返ってくる処理のとき(非同期処理じゃないことが前提)
userService.findUser(userId) // Mono<User>
.map(user -> setUserLastLoggedIn(user))
// Mono<User>
private User setUserLastLoggedIn(User user) // ★呼び出してる処理がUserを返す
並列に処理するMono.zip / Flux.zip
Mono.zip(
userService.findAttributes(userId), // T1 ★並列に処理される
corproateService.findByUserId(userId) // T2 ★並列に処理される
).flatMap(tuple2 -> {
var userAttributes = tuple2.getT1(); // UserAttributes
var corporation = tuple2.getT2(); // Corporation
return Profile.builder(UserAttributes, corporation);
})
Flux.zip(
userService.selectIn(userIdList), // T1 ★同じID順でin句でリスト取得 Flux<UserAttributes>
corproateService.selectInUserId(userIdList), // T2 ★同じID順でin句でリスト取得 Flux<Corporation>
).flatMap(tuple2 -> {
var userAttributes = tuple2.getT1(); // UserAttributes ★2つの結果で同じ要素順のオブジェクトが
var corporation = tuple2.getT2(); // Corporation ★tuple2でまとめられる
return doSomething();
});
変換処理
- 縮小変換:reduce(前の値を引き継いで順次処理しながらMonoにまとめる。いわゆるreduce)
- 中間値変換:scan(前の値を引き継いで逐次結果を返す。いわゆるscan)
- カウントに変換:count
- bool値に変換:all/any/hasElements/hasElement
- 重複排除:distinct
条件処理
- 空になったら別のストリームで継続:switchIfEmpty
- フィルタリング:filter
- 非同期処理の条件でフィルタリング:filterWhen
ストリームの切り替え
データを変換せずに処理して継続:delayUntil
※Monoを返す非同期処理の実行
return Mono.just(request)
.flatMap(req -> convertProfile(req)) // Mono<Profile>
.delayUntil(profile -> profileService.save(profile)) // saveはMono<Void>を返すが、
.flatMap(profile -> doSomething()) // Mono<Profile>で処理が継続できる
// thenReturnで元のデータに戻すこともできるが、新しいストリームに切り替えているので、
// 厳密にはコストが高い
.flatMap(profile -> profile.Service.save(profile).thenReturn(profile))
今のストリーム処理を一旦完了して次のストリームの処理につなげる:then/thenMany
return userService.findAttributes(userId) // ユーザーの属性を検索して削除
.delayUntil(userAttributeService::delete)
.thenMany(hogeService.selectByUser(userId)) // ★FluxにつなげるときはthenMany
.delayUntil(hogeService::delete) // ユーザーがらみのhoge情報を削除
.then(userService.find(userId)) // ★Monoにつなげるときはthen
.delayUntil(userService::delete) // ユーザーを削除
WebAPIを呼ぶ
WebClientがノンブロッキングなAPI呼び出しに対応しています。
呼び出しのサンプルはこちら。
WebClient webclient = WebClient.builder()
.baseUrl("http://localhost:8080")
.defaultCookie("cookieKey", "cookieValue")
.defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.defaultUriVariables(Collections.singletonMap("url", http://localhost:8080"))
.build();
// post
webclient.post()
.uri("/api/v1/users")
.contextType(MediaType.APPLICATION_JSON)
.bodyValue(params)
.retrieve()
.bodyToMono(User.class);
// パラメーターの設定
webClient.get()
.uri(uriBuilder - > uriBuilder
.path("/users/{id}")
.queryParam("details", true)
.build(userId))
.retrieve()
.bodyToMono(User.class);
// ボディ設定
webClient.post()
.uri("/api/v1/services")
.bodyValue(params)
.retrieve()
.bodyToFlux(User.class)
// レスポンスボディ以外も処理したい場合
webClient.post()
.uri("/api/v1/users")
.exchangeToFlux(res -> {
var headers = res.headers(); // ヘッダやステータスコードなどの処理
return res.bodyToFlux(User.class) // オブジェクトに変換
});
リダイレクトする(非WebAPIエンドポイント)
RedirectViewのMonoを生成すればOK!
return Mono.just(new RedirectView("https://example.com/path/to/redirect?foo=foo&bar=bar"));
おわりに
従来の実装方式に慣れていると、最初はとっつきにくいところもありますが、実際やってみるとすぐに慣れていきました。
この記事が何かの手助けになれば幸いです。
ここまで読んでいただき、ありがとうございました!
We are Hiring!