概要
C++アプリの取得データをKafka経由でKibanaで可視化するシステムの構築手順を説明します。構築する環境は以下です。
C++アプリ → Kafka → Logstash → Elasticsearch → Kibana
C++アプリで取得したデータをKafkaでキューイングし、LogstashによりElasticsearchに書き込み、Kibanaのダッシュボードで可視化するという流れです。
私のC++アプリは信号処理の過程をデータとして取得するもので、それをKibanaで可視化すると以下のようにきれいに表示することができました。最短5秒周期のリアルタイムでデータを可視化することも可能です。
↓5秒周期で動きます。
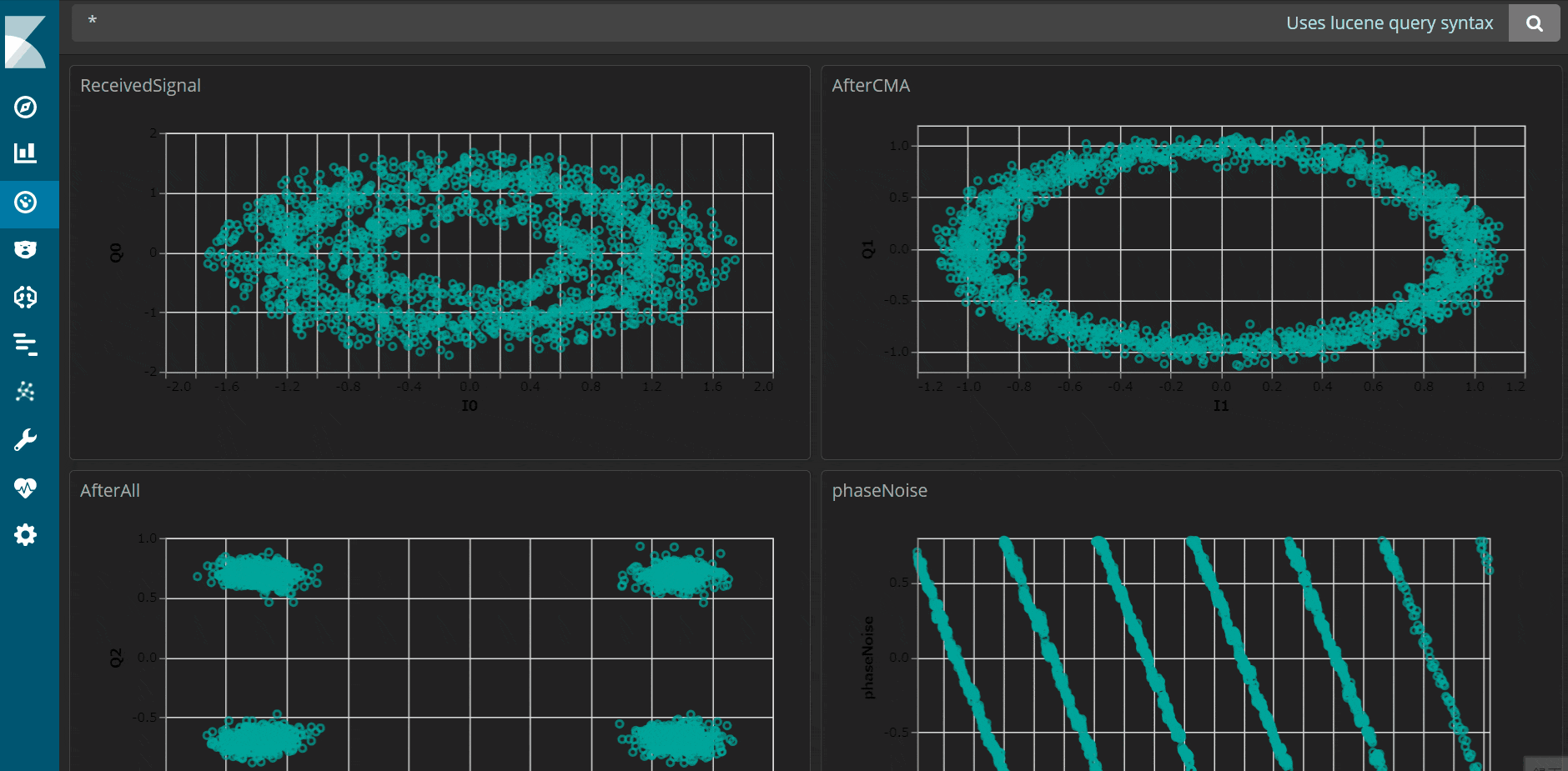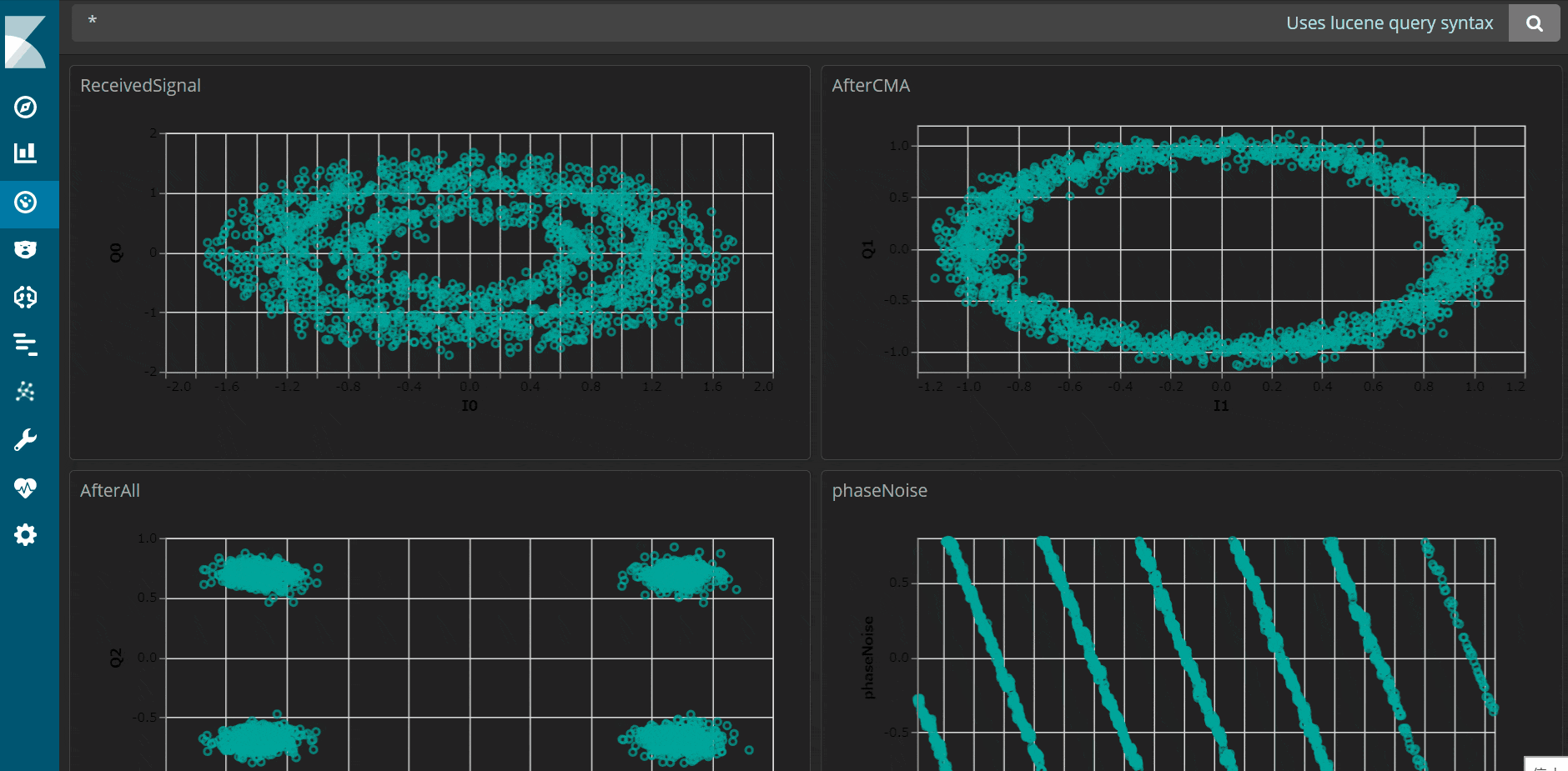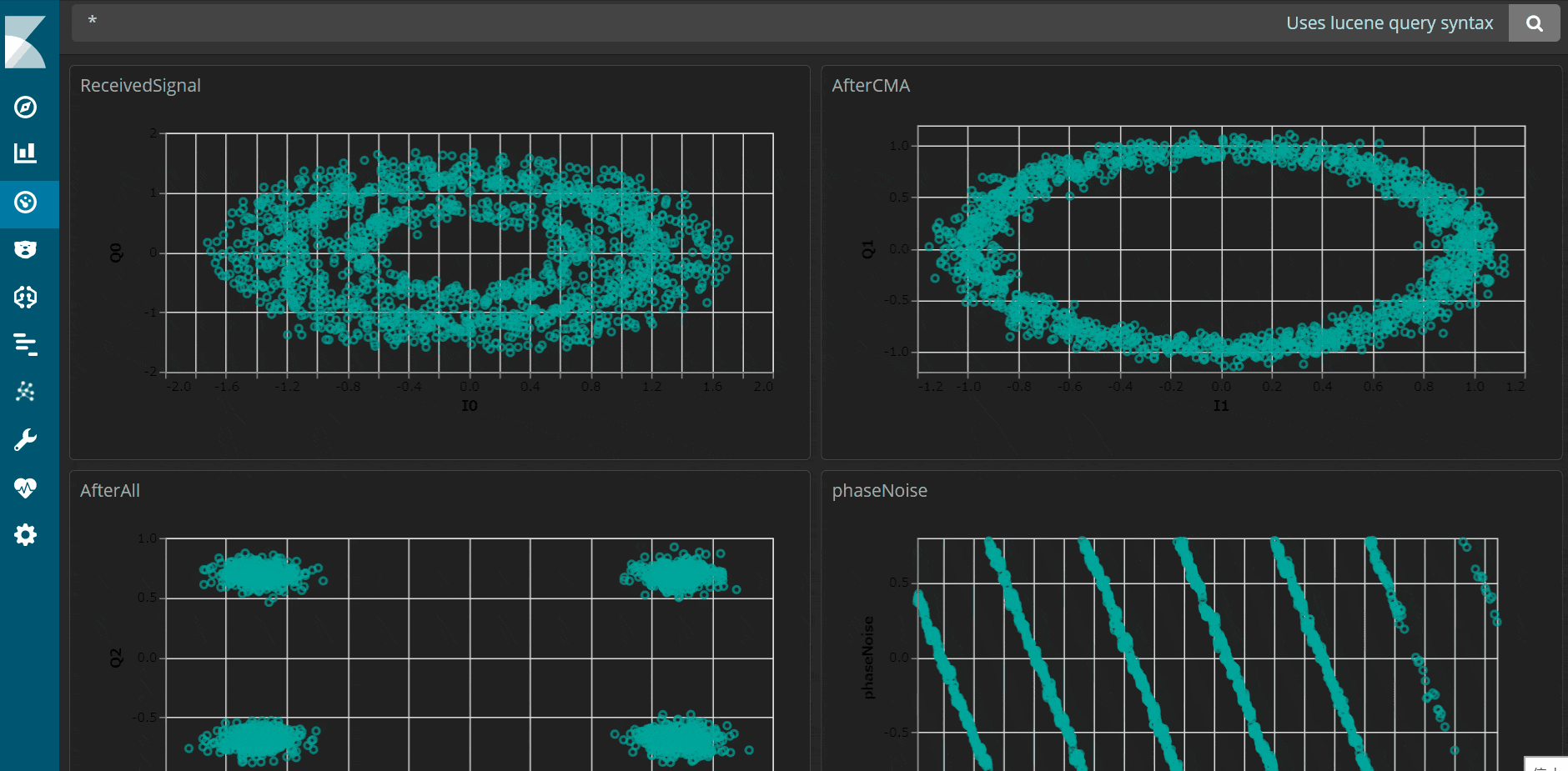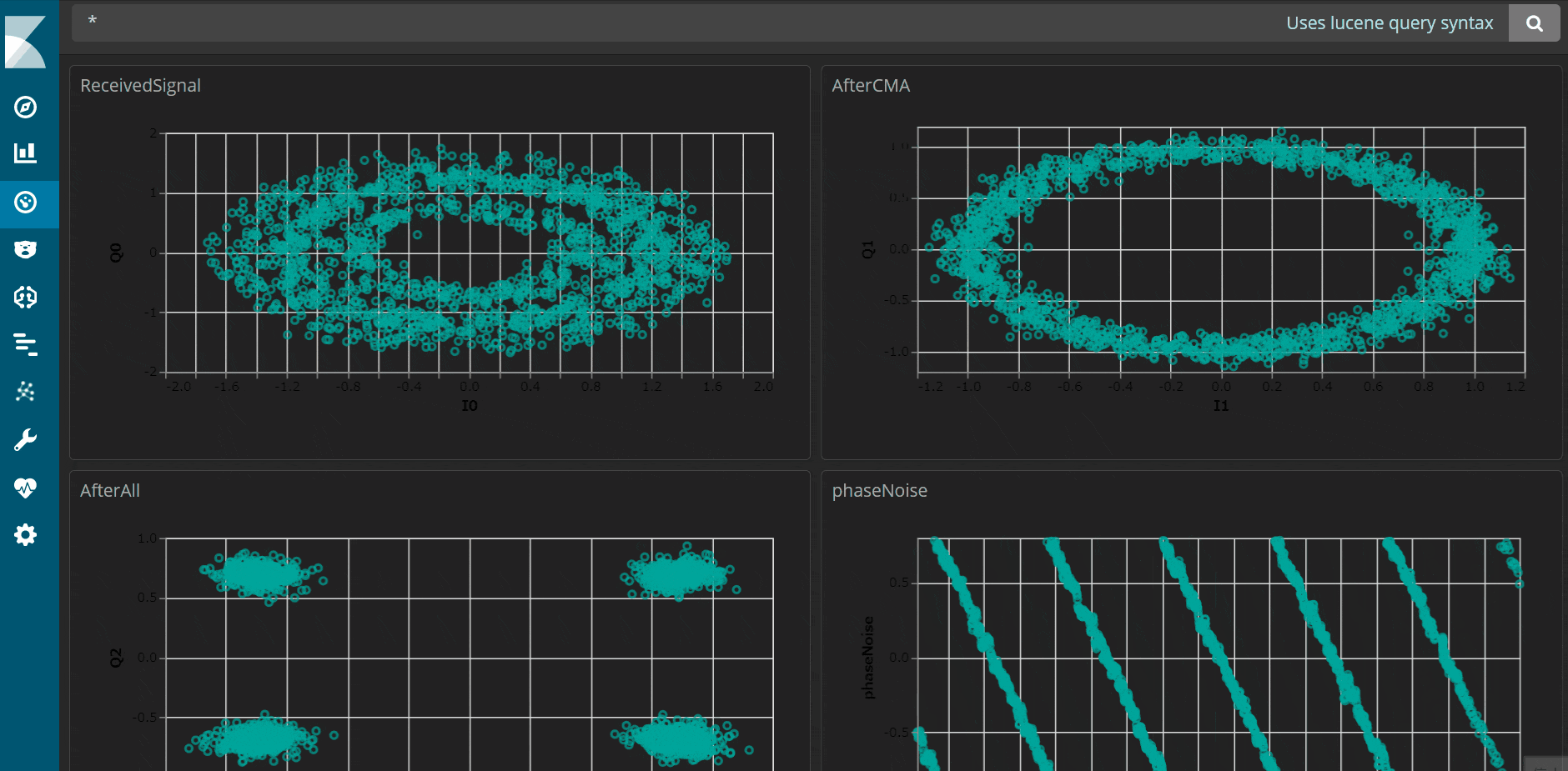
システムの構築手順としては、以下3点が必要です。
- C++アプリにKafkaへのデータ(メッセージ)への書き込み機能を実装すること(Producerの実装)
- DockerでKafka、Logstash、Elasticsearch、Kibanaをデプロイすること
- Kibanaでデータを可視化すること
主に以下の環境での構築方法です。
- OS: Ubuntu 20.04
- Docker インストール済み
- アプリの言語: C++
C++アプリへのKafka Producerの実装
Kafkaと取得データのフォーマットとしてJSON形式をC++で扱うためのパッケージをインストールします。
sudo apt install librdkafka-dev
sudo apt install nlohmann-json3-dev
C++アプリに以下のようなProducer機能を付け足します。
ヘッダー部分:
# include "librdkafka/rdkafkacpp.h"
# include <nlohmann/json.hpp>
using json = nlohmann::json;
初期化部分:
std::string brokers = "192.168.1.10:9092";//KafkaのbrokerのIPアドレス
std::string errstr;
std::string topic_str = "log";
int opt;
std::string jsn_str;
json jsn[INPUT_CODING];
RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);
RdKafka::Conf *tconf = RdKafka::Conf::create(RdKafka::Conf::CONF_TOPIC);
conf->set("metadata.broker.list", brokers, errstr);
RdKafka::Producer *producer = RdKafka::Producer::create(conf, errstr);
if (!producer) {
std::cerr << "Failed to create producer: " << errstr << std::endl;
exit(1);
}
std::cout << "% Created producer " << producer->name() << std::endl;
JSON作成部(jsn[i]に対して{I2: data_Rx_i[i], Q2: data_Rx_q[i]}のようなJSONを作成したい時の例):
for(i = 0; i < num; i++) {
jsn[i]["I2"] = data_Rx_i[i];
jsn[i]["Q2"] = data_Rx_q[i];
}
書き込み部分:
for(i = 0; i < num; i++) {
jsn_str = jsn[i].dump();
RdKafka::ErrorCode resp = producer->produce(topic_str, partition,
RdKafka::Producer::RK_MSG_COPY,
(void *) jsn_str.c_str(), jsn_str.length(),
NULL, 0, 0, NULL);
producer->flush(10);
}
コンパイル方法:
g++ simulation.cpp -o simulation -lrdkafka++
DockerでKafka、Logstash、Elasticsearch、Kibanaをデプロイ
Dockerを起動する。(docker-compose.ymlを以下のリポジトリに上げています。logstash.confは必要であれば編集して下さい。docker-compose.yml中のKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://172.17.0.1:9092のIPアドレスを動作させるサーバのアドレス(192.168.1.10)に変更すると他のサーバからのKafkaメッセージも受信できるようになります。)
git clone https://github.com/takahirosuzuki-0/Kafka-Logstash-Elasticsearch-Kibana.git
cd Kafka-Logstash-Elasticsearch-Kibana
docker-compose up -d
C++アプリからKafka brokerにデータの書き出しが行えているかを以下で確認します。
./simulation
kafkacat -b localhost:9092 -t log
{"I0":0.4826540946960449,"I1":0.7826693654060364,"I2":0.5573457479476929,"Q0":0.25336918234825134,"Q1":0.3076968193054199,"Q2":0.6297733187675476}
Kibanaでデータの可視化
あとはブラウザでlocalhost:5601からKibanaにアクセスし、好きなチャートのフォーマットを選択し、データの可視化を行います。散布図など好きな形式でデータを可視化したい場合はVisualization->Vegaを選択し、任意のグラフが作成できます。
選択後、以下の画面が見えますが、左側の枠にプログラムを書くことでグラフを作成します。

グラフを作成するためのプログラムの例を示します。以下は時間vsデータ(phaseNoise)のグラフ向けのプログラムです。
{
"$schema": "https://vega.github.io/schema/vega-lite/v2.json",
"mark": "point",
data: {
url: {
%context%: true
%timefield%:@timestamp
index: log*
body: {
size: 5000
_source: ["@timestamp", "phaseNoise" ]
}
}
format: { property: "hits.hits" }
}
transform: [
{
calculate: "toDate(datum._source['@timestamp'])"
as: "time"
}
]
encoding: {
x: {
field: time
type: temporal
axis: { title: "time" }
}
y:{
field: _source.phaseNoise
type: quantitative
axis: { title: "phaseNoise" }
}
}
}
以下はデータ(I2)vsデータ(Q2)のグラフ向けのプログラムです。
{
"$schema": "https://vega.github.io/schema/vega-lite/v2.json",
"mark": "point",
data: {
url: {
%context%: true
%timefield%:@timestamp
index: log*
body: {
size: 10000
_source: ["I2", "Q2" ]
}
}
format: { property: "hits.hits" }
}
encoding: {
x: {
field: _source.I2
type: quantitative
axis: { title: "I2"}
}
y:{
field: _source.Q2
type: quantitative
axis: { title: "Q2"}
}
#"color": {"field": "Origin", "type": "nominal"}
}
}
以上で最初に示したようなグラフが作成できます。