Java Silver SE 11を現在勉強中のものです。
最近やっと模擬問題で合格点を取れるレベルまでになれたので、これまでのポイントをまとめていこうと思います。
基本データ型と文字列操作
プリミティブ型の型変換について
■プリミティブ型の大小関係
double > long > float > int > short > byte
の順番。
■小リテラルを大型の変数へ代入 = 暗黙的に変換。
小さい型のリテラルを大きい型の変数に代入すると、暗黙的に変換され代入することができる。
これは、接尾辞がついていても暗黙的変換は適応される。
double d = 3.0;
long l = 2;
d = l;
System.out.println(d); // 2.0が出力。
■大リテラルを小型の変数へ代入 = 明示的なキャストが必要。
大きい型のリテラルを小さい型の変数に代入する場合、明示的なキャストを行わないとコンパイルエラーになる。
double d = 3.0d;
float f = d; // コンパイルエラー。
float f2 = (float)d;
System.out.println(f2); // 3.0が出力。
float f3 = 3.0; // javaの浮動小数点のデフォルトはdouble型なので、コンパイルエラー。
■文字 ⇄ 数値の変換は必ずキャストが必要。
char c = 89;
System.out.println(c); // Yが出力。
byte b = 89;
char c = b; // コンパイルエラー。
System.out.println(c);
byte b = 89;
char c = (char)b;
System.out.println(c); // Yが出力。
char c = 89;
byte b = (byte)c;
System.out.println(b); // 89が出力。
char は文字型。
byte~ はデータ型。
charは0 ~ 65535まで数値を入れることができるが、charの意味する数値は文字を表している。
byte~ は数値を表している。
charの初期化の際に数値を代入することは良いが、
byte等のデータ型に数値を一度代入した後にcharに代入すると、同じ数値でもそれぞれ意味が異なるため、明示的なキャストが必ず必要になる。
接頭辞と接尾辞
■接頭辞の種類
| 進数 | 接頭辞 |
|---|---|
| 2進数 | 0b |
| 8進数 | 0 |
| 10進数 | なし |
| 16進数 | 0x |
.........................................................................................................................................
■接尾辞の種類
| 進数 | 接頭辞 |
|---|---|
| double | 「D」 もしくは 「d」 |
| long | 「L」 もしくは 「l」 |
| float | 「F」 もしくは 「f」 |
※他のプリミティブ型に対応する接尾辞はない。
整数リテラルのルール
①アンダースコア「_」を利用することができる。
②リテラルの先頭と最後には記述できない。
③記号の前後には記述できない。
int a = 100_000_000; // ①問題なし。
int b = _100_000_000; // ②コンパイルエラー
int c = 100_000_000_; // ②コンパイルエラー
int d = 0b_00111; // ③コンパイルエラー
int e = 0x_00111; // ③コンパイルエラー
float f = 1._0; // ③コンパイルエラー
float f2 = 1.0_f; // ③コンパイルエラー
識別子のルール
①予約語での宣言はできない。
int int = 10;
②使える記号はアンダースコア「_」、通貨記号のみ
int _a = 20;
int $a = 30;
int _ = 40; // コンパイルエラー。
③数字から始めることはできない。(2文字目以降であれば可能)
int 01 = 20; // コンパイルエラー。
int $1 = 20; // OK
int _0 = 20; // OK
varのルール
①varは右辺の代入演算子から型を推論する。
public class Main {
public static void main(String[] args){
var i = 10;
var m = new Main(); // OK
var array = new int[]{1,2,3}; // OK
var array2 = {1,2,3} // new演算子での生成でないと推論が出来ずコンパイルエラー
var value = sample(); // メソッドの戻り値から推論も可能。
var value2 = () -> {}; // ラムダ式では型推論は使えないのでコンパイルエラー
// ラムダ式の引数には使えるので注意!
var list = new ArrayList<String>(); // OK (varはArrayList<String>型になる)
var list = new ArrayList<>(); // OK (ジェネリクス内なしはObject型になる)
}
public static String sample(){
return "java";
}
}
②ローカル変数でしか利用できない。
public class Main {
private var value; // フィールド宣言では使えないのでコンパイルエラー
public static void main(String[] args){
var i = 10;
}
public static void sample(var value){ // 引数宣言では使えないのでコンパイルエラー
System.out.println("hello");
}
}
③複合宣言もできない
public class Main {
public static void main(String[] args){
var i = 10, i2 = 20; // コンパイルエラー
}
}
Stringクラス
Stringオブジェクトの生成方法
①""(ダブルクォーテーション)を使った文字列リテラルで生成
②newを使ってインスタンス化で生成
③StringクラスのvalueOfメソッドを使用する。
public class Main {
public static void main(String[] args){
String str = "Java"; // ①
String str2 = new String("Java"); // ②
String str = String.valueOf("Java"); // ③
}
}
Stringクラスのメソッド
■charAtメソッド
文字列の中から、引数で指定したindex番号の文字を戻す
public class Main {
public static void main(String[] args) {
String str = "Java";
System.out.println(str.charAt(2)); // vが出力
System.out.println(str.charAt(4)); // index番号より多い数値を指定すると実行時エラー
}
}
■indexOfメソッド
文字列の中から、引数で指定した文字のindex番号を返す。
指定した引数の文字が文字列にない場合、-1を返す。
public class Main {
public static void main(String[] args) {
String str = "Java";
System.out.println(str.indexOf("J")); // 0 が出力。
System.out.println(str.indexOf("S")); // -1 が出力。
}
}
■substringメソッド
文字列の中から、引数で指定した数値内の文字を抽出して返す。
public class Main {
public static void main(String[] args) {
String str = "Java";
System.out.println(str.substring(1,3)); // av が出力。
System.out.println(str.substring(3,5)); // 実行時エラー。StringIndexOutOfBoundsException
}
}
substringメソッドの仕組み
| J | a | v | a |
0 1 2 3 4
↑ ↑
1 - 3 の間なので av
■replaceメソッド・replaceAllメソッド
文字列内の文字を、引数で指定した文字に置き換えるためのメソッド。
replaceメソッドは、char型の引数を2つ受け取る方と、
replaceメソッドは、charSequence型の引数を2つ受け取る方の2通りがある。
char型とcharsequence型を一つずつ受け取るものはないので、コンパイルエラーとなる。
public class Main {
public static void main(String[] args) {
String str = "Java";
System.out.println(str.replace('a','b')); // Jbvb が出力。
System.out.println(str.replace("av", "b")); // Jba が出力。
System.out.println(str.replace("av", 'b')); // コンパイルエラー。
}
}
replaceAllメソッドもreplaceメソッドと同様に、文字列内の文字を引数で指定した文字に置き換える。
違いとしては、replaceAllは第一引数に正規表現を使用することができ、正規表現にマッチした全ての文字を全て指定の文字(文字列)に変換できる。
public class Main {
public static void main(String[] args) {
String str = "Java, html, css, python";
System.out.println(str.replaceAll("[a-z]", "Go"));
// JGoGoGo, GoGoGoGo, GoGoGo, GoGoGoGoGoGo が出力される。
}
}
■startsWith・endsWithメソッド
文字列が引数で指定した文字から始まるか(終わるか)どうかを判定し、真偽を返す。
public class Main {
public static void main(String[] args) {
String str = "Java";
System.out.println(str.startsWith("J")); // true
System.out.println(str.endsWith("a")); // true
}
}
■concatメソッド
文字列に文字を連結するメソッド。
public class Main {
public static void main(String[] args) {
String str = "Java";
str = str.concat("Go");
System.out.println(str); // JavaGoが出力。
}
}
Stringクラスの罠
①Stringクラスは不変のオブジェクトである。
Stringクラスで生成した文字列は不変なオブジェクトになる。
なので、Stringで文字列を変更を加えた時は、
新しい文字列インスタンスを都度生成している。
public class Main {
public static void main(String[] args) {
String str = "Java";
str += "Go"; // この時strの文字列にGoを追加しているのではなく、
// JavaGoという新しい文字列インスタンスを生成し、strに代入している。
}
}
その他のStringメソッドも同様。
Stringメソッドで既存の文字列に変更を加えるメソッドは、都度文字列インスタンスを新たに生成している。
この時、生成した文字列は変数に代入しないと、利用することはできない。
public class Main {
public static void main(String[] args) {
String str = "Java";
str.concat("Go");
str.replace('a','b'));
str.substring(1,3);
System.out.println(str); // Javaが出力。
}
}
.................................................................................................................................................
StringBuilderクラス
Stringクラスと同様に文字列を扱うクラス。
違いとしては、StringBuilderクラスは生成時に内部にバッファーを持った文字列を扱うことができる。
StringBuilderクラスは生成時、16文字分の余分なバッファーを持って文字列を扱おうとする。
しかし、StringBuilderクラス生成時にコンストラクタで文字を指定して生成した場合、
16文字分 + コンストラクタ内の文字列の長さ分のバッファーを持って生成される。
public class Main {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
StringBuilder sb2 = new StringBuilder("Java");
System.out.println(sb.capacity()); // 16
System.out.println(sb2.capacity()); // 20
}
}
StringBuilderクラスのメソッド
■appendメソッド
StringBuilder用の文字を連結するメソッド。
public class Main {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder("Java");
sb.append("GO");
System.out.println(sb); // JavaGoが出力。
}
}
StringBuilderクラスのポイント
StringBuilderクラスは可変オブジェクトである。
StringBuilderはStringクラスと違い可変長なので、代入せずとも文字列の変更ができる。
public class Main {
public static void main(String[] args) {
String str = "GET";
StringBuilder sb2 = new StringBuilder("Java");
str.concat("POST");
sb2.append("GO");
System.out.println(str); // GETが出力
System.out.println(sb2); // JavaGoが出力
}
}
.................................................................................................................................................
配列と操作
配列の宣言方法
パターン①
大括弧とnew演算子を利用した宣言
int[] array = new int[3];
int[][] array = new int[2][2];
ポイント
// ①大カッコの中は整数しか記入できない。
int[] array = new int[2.3]; // コンパイルエラー
// ②配列の中で変数や計算ををすることができる。
int x = 3;
int y = 2;
int[] array = new int[x * y];
/*
* ③多次元配列の場合、
* 変数宣言時の大カッコの数と、代入する側の大カッコの数が違うと
* コンパイルエラーになる。
*/
int[][] array = new int[2];
int[] array = new int[2][3];
/*
* ④多次元配列の場合、
* 一次元配列目を空で宣言すると、二次元以降の宣言はできず、
* コンパイルエラーになる。
*/
int[][] array = new int[][2];
/*
* ⑤new演算子の場合、
* 変数宣言時と同時に宣言しなくても良い。
*/
int[] array;
array = new int[3];
パターン②
{}を使用して初期化宣言
int[] array = {1,2,3};
int[][] array = { {1,2},{3,4} };
ポイント
/*
* ①new演算子 + 大カッコと一緒に宣言ができる。
* 一緒に宣言する場合、大カッコの中には整数値を入力してはいけない。
* 整数値を入力するとコンパイルエラーになる。
*/
int[] array = new int[]{1,2}; //OK
int[] array = new int[2]{1,2}; //コンパイルエラー
/*
* ②多次元配列の場合、
* 変数宣言時の大カッコの数と、代入する側の{}の数が違うと
* コンパイルエラーになる。
*/
int[][] array = { {1,2},{3,4} }; //OK
int[] array = { {1,2},{3,4} }; //コンパイルエラー
/*
* ③初期化子の場合、
* 変数宣言時と同時に宣言しなくてはならない。
*
* 分けて宣言したい場合、new演算子と大カッコも合わせて記述する。
*/
int[] array;
array = {1,2,3,4}; //コンパイルエラー
int[] array;
array = new int[]{1,2,3,4}; //OK
配列変数と配列要素
配列変数の出力
配列変数を直接出力すると、ハッシュコードが出力される。
public class Main {
public static void main(String[] args) {
int[] array = new int[2];
System.out.println(array); //[I@722c41f4 が出力
}
}
配列の要素のデフォルト値
配列の要素はデフォルト値で、以下のように用意されている。
| 型 | デフォルト型 |
|---|---|
| 変数型 | 0 |
| 浮動小数点数型 | 0.0 |
| 真偽型 | false |
| 文字型 | ¥u0000 |
| オブジェクト型 | null |
要素に値を明示的に代入しない限りは、上記の値がセットされる。
public class Main {
public static void main(String[] args) {
int[] array = new int[2];
System.out.println(array[0]); //0 が出力
}
}
演算子と判定構文
==演算子とequalsメソッドによる比較の違い
概要
Javaに2つの値を比較する方法が2種類ある。
① ==演算子による比較。
② equalsメソッドを使用した比較。
==演算子はデータ型の比較で使用することが基本であり、
equalsメソッドは参照型の比較で使用することが基本。
==演算子の場合
データ型の場合 → 値を比較し同値性を判断する。
参照型の場合 → 参照先のアドレスを比較し、同値性を判断する。
public class Main {
public static void main(String[] args) {
int a = 10;
int b = 10;
Sample s1 = new Sample();
Sample s2 = new Sample();
Integer i1 = new Integer("1");
Integer i2 = new Integer("1");
System.out.println(a == b); // true
System.out.println(s1 == s2); // false
System.out.println(i1 == i2); // false
}
}
equalsメソッドの場合
オーバーライドをせずに使用した場合
==演算子と同様の判断をする。
※例外あり。(詳細は後述)
※データ型ではequalsメソッドは使用できない。
public class Main {
public static void main(String[] args) {
int a = 10;
int b = 10;
Sample s1 = new Sample();
Sample s2 = new Sample();
Integer i1 = new Integer("1");
Integer i2 = new Integer("1");
System.out.println(a.equals(b)); // コンパイルエラー
System.out.println(s1.equals(s2)); // false
System.out.println(i1.equals(i2)); // true
}
}
オーバーライドした使用した場合
オーバーライドした内容に沿って、判断する。
public class Sample {
public int num;
public Sample(int num){
this.num = num;
}
public boolean equals(Object obj){
if(obj == null){
return false;
}
if(obj instanseof Sample){
Sample s = (Sample)obj;
return s.num == this.num;
}
return false;
}
}
public class Main {
public static void main(String[] args) {
Sample s1 = new Sample("100");
Sample s2 = new Sample("100");
Sample s3 = new Sample("200");
Integer i1 = new Integer("1");
Integer i2 = new Integer("2");
System.out.println(s1.equals(s2)); // true
System.out.println(s1 == s2); // false
System.out.println(s1.equals(s3)); // false
System.out.println(i1.equals(i2)); // false
}
}
String型の比較の注意点
==演算子の場合
public class Main {
public static void main(String[] args) {
String s1 = "Java";
String s2 = "Java";
String s3 = new String("Java");
System.out.println(s1 == s2); // ①true
System.out.println(s1 == s3); // ②false
System.out.println(s2 == s3); // ②false
System.out.println(s1.equals(s2)); // ③true
System.out.println(s1.equals(s3)); // ③true
System.out.println(s2.equals(s3)); // ③true
}
}
①解説
String型はオブジェクト型だが、==演算子の比較でもtrueが返される。
これは文字列を生成する際、以下のような処理を行なっているからである。
■一度生成された文字列はコンスタントプールと呼ばれる別領域に定数として一度保存される。
■そして、もし同じ文字列が再度生成された場合は、そのコンスタントプールから同じ文字列のものを使い回す。
⇨ 結果としてs1とs2は同じ参照先が代入されており、trueとなる。
②解説
①の解説は、newを使用せず、””(ダブルクォーテーション)を使用して生成された場合に起きる処理となる。
newを使用して文字列を生成した場合は新たなインスタンスとして生成をする。
⇨ s1とs3は別々の参照先が代入されているので、falseとなる。
③解説
equalsメソッドは厳密にはオブジェクトの持つ値を比較し、その値が同じかを判断する。
なので、Integerの持つ数値・Stringの持つ文字列を比較対象としている。
⇨ 結果、s1.s2.s3は全て同じ文字列を持つので、参照先が違っていてもtrueとなる。
Stringのinternメソッドについて
Stringクラスのinternメソッドを使用すると、これまでの解説とは少し違った動きをする。
public class Main {
public static void main(String[] args) {
String s1 = "Java";
String s2 = "Java";
String s3 = new String("Java");
String s4 = new String("Java");
System.out.println(s1.intern() == s2.intern()); // true
System.out.println(s1.intern() == s3.intern()); // true
System.out.println(s2.intern() == s3.intern()); // true
System.out.println(s3.intern() == s4.intern()); // true
}
}
internメソッドを使用すると、newで生成したs3インスタンスを==演算子で比較してもtrueとなる。
これはinternメソッドが、変数の持つ文字列をコンスタントプールを含むメモリの中から探し出し、再利用するという処理をするからである。
同じ文字列を持つインスタンスが複数あったとしても、internメソッドで返す参照先は常に同じで1つだけである。
よって、s1~s4には全て同じ参照先がreturnとして返されているため、全てtrueとなる。
if文
■if文はカッコ{}を省略できるが、省略した場合if文の処理として見なされるのは条件式の直後の処理だけ
public class Main {
public static void main(String[] args) {
if(false)
System.out.println("hello");
System.out.println("See you");
} // See youだけが表示
}
switch文
■switch文の条件式が戻せる型には制限があり、戻せるのは以下の型だけ
・int型以下のデータ型(int,short,byte,char)
・String型
・列挙型
■switch文のcase値として利用できるのは、
・定数(finalで宣言された変数かリテラル)かコンパイル時に値を決められるもの
・条件式の戻す値と同じ型か互換性のある型
・nullではない※
の3つの決まりがある。
※条件式にnullを使用すると、NullpointerExceptionが返される。
悪い例(全てコンパイルエラー)
public class Main {
public static void main(String[] args) {
double d = 3.14;
switch(d){
case "100.0": System.out.println("OK"); // 互換性がないので×
break;
case 3.14 : System.out.println("OK"); // double型は返せないので×
break;
case null : System.out.println("OK"); // nullは使用できない
break;
case d : System.out.println("OK"); // 定数じゃないので×
break;
}
}
}
良い例
public class Main {
public static void main(String[] args) {
final int NUM = 100;
switch(NUM){
case NUM: System.out.println("OK"); // 定数
break;
case 1000 : System.out.println("OK"); // リテラル
break;
case 2*20 : System.out.println("OK"); // コンパイル時に確定する数値
break;
case '9' : System.out.println("OK"); // 互換性
break;
case 'a' : System.out.println("OK"); // 互換性
break;
}
}
}
インスタンスとメソッド
staticについて
staticがついたフィールドを、クラス変数という。
クラス変数はクラス毎に作られる変数。
クラス単位の変数なので、インスタンスを作成してもクラス変数は全てのインスタンス間で共有される。
// Aクラス
public class A {
public static int num = 10;
}
// Mainクラス
public class Main {
public static void main(String[] args) {
A a = new A();
A a2 = new A();
a.num = 10;
a2.num = 50;
System.out.println(a.num); // 50
System.out.println(a2.num); // 50
System.out.println(A.num); // 50
}
}
ポイント
①staticで修飾されたフィールドやメソッドは、static領域という領域に配置される。
②staticなフィールドはインスタンスを作らなくても使用できる。
③staticなフィールドにアクセスするには方法は2つ。
①クラス名.フィールド名
②インスタンス名.フィールド名
④staticで修飾されたフィールドやメソッド が アクセスできるのは、
staticで修飾されたフィールドやメソッド だけ である。
public class Main {
static int a = 10;
public static void main(String[] args){
// static から static
System.out.println(Main.a);
}
}
⑤staticで修飾されたフィールドやメソッド には 、
staticで修飾されていないフィールドやメソッドもアクセスできる。
public class Main {
static int a = 10;
public int b = 20;
public static void main(String[] args){
// static から static
System.out.println(Main.a); // 10
/*
* コンパイルエラー。
* 変数bはインスタンス変数なので、インスタンス化しないとそもそも呼び出せない。
*/
System.out.println(Main.b);
}
}
オーバーロード
オーバーロードとは
メソッドの多重定義。同名のメソッドを複数宣言すること。
オーバーロードの条件は、メソッドの引数が異なることであり、
①引数の型
②引数の数
③引数の順番
が異なればオーバーロードである。
注意
オーバーロードにおいて、戻り値が同じか同じではないかは条件には入らない。
戻り値が違っていても、引数が同じならオーバーロードにはならない。
戻り値が同じでも、引数が違うならオーバーロードになる。
◆引数の変数名だけが違う
◆戻り値だけが違う
はコンパイルエラーになる。
public class Main {
public static void main(String[] args){
}
// オーバーロード
public static void main(int[] args){
}
// オーバーロード
public static void main(String[] args,int num){
}
// 戻り値だけ違う。 コンパイルエラー
public static String main(String[] args){
return "hello";
}
// 引数名だけが違う。 コンパイルエラー
public static void main(String[] arg){
}
}
オーバーロードの優先順位について
オーバーロードの際引数は異なるが引数に互換性にがある場合、一番近いもの(
厳密な方)が優先されて呼び出される。
import java.util.List;
import java.util.Collection;
import java.util.ArrayList;
public class Sample {
public void message(Collection collection) {
System.out.println("A");
}
public void message(List list) {
System.out.println("B");
}
}
public class Main {
public static void main(String[] args){
List<String> list = new ArrayList<>();
Sample s = new Sample();
s.message(list); // Bが出力
}
}
コンストラクタ
インスタンスが利用される前に前処理を行うメソッドのこと。
ポイント
コンストラクタの3つのルール
①メソッド名はクラス名と同じにすること
②戻り値は記述できない
③newと一緒にしか使えない(インスタンス生成時以外は呼び出せない)
注意
コンストラクタにアクセス修飾子の制限は特にないので、基本的にどのアクセス修飾子も付与できる。
コンストラクタの初期化
初期化子
初期化子を使うことで、コンストラクタが実行される前に実行される処理を記述することができる。
初期化子を記述すると、オーバーロードしたコンストラクタ全てで初期化子の処理が一度実行される。
※初期化子はインスタンスが呼び出された時にしか利用されない。
public class Sample {
// 初期化子
{
System.out.println("B");
}
public Sample(){
System.out.println("A");
}
public Sample(String str){
System.out.println("A");
}
}
static初期化子
インスタンス生成時ではなく、クラスがロードされた段階で何らかの処理を実装してほしいときは、static初期化子を利用する。
// 初期化子
static {
System.out.println("B");
}
public Sample(){
System.out.println("A");
}
public Sample(String str){
System.out.println("A");
}
}
デフォルトコンストラクタ
コンストラクタを明示的に定義しなかった場合、コンパイラが引数なしのコンストラクタをコンパイル時に追加する。
このコンストラクタをデフォルトコンストラクタという。
注意
①引数なしのコンストラクタをデフォルトコンストラクタというわけではない。
②デフォルトコンストラクタは、明示的にコンストラクタを定義した場合は追加されない。
※引数ありのコンストラクタを定義してしまうと、それもデフォルトコンストラクタが追加されない条件に当てはまってしまうので、引数有りのコンストラクタ以外を呼び出せなくなってしまう。
解決するには、引数なしのコンストラクタを明示的に定義しなければいけない。
public class Sample {
private String name;
// public Sample(){
// }
public Sample(String name){
this.name = name;
}
}
public class Main {
public static void main(String[] args){
Sample s = new Sample(); // コンパイルエラー
}
}
コンストラクタとthis
コンストラクタ内でオーバーライドした別のコンストラクタを呼び出すには、コンストラクタ内でthisを記述する。
public class Sample {
private String name;
public Sample(){
// 下のコンストラクタを読んでいる。
this("AAA");
System.out.println("A");
}
public Sample(String name){
this.name = name;
}
}
注意
コンストラクタ自体の記述の順番は関係ないが、thisは一番最初に記述しなければならない。
thisを使って別のコンストラクタを呼び出す際は、呼び出す前に何らかの処理を記述してはいけない。
public class Sample {
private String name;
// コンパイルエラー
public Sample(){
System.out.println("A");
this("AAA");
}
public Sample(String name){
this.name = name;
}
}
thisの使い方の注意点
thisは別のコンストラクタを呼び出す以外にも、インスタンス内に定義されたフィールドやメソッドを呼び出す際にも使用する。
public class A {
String name;
public void methodA(String name){
this.name = name;
this.callName();
}
public void callName(){
System.out.println(this.name);
}
}
public class Main {
public static void main(String[] args) {
A a = new A();
a.methodA("sample"); // sampleと出力。
}
}
このthisを仮にローカル内でつけなかった場合、フィールドと引数(ローカル変数)の2箇所あることになるが、この場合、ローカル変数側の利用を優先される。
public class A {
String name;
public void methodA(String name){
name = name; // thisを削除したので、代入式の左辺は引数(ローカル変数)のnameということになる。
// つまりこの式は、引数nameに引数nameを代入するという式になる。
this.callName();
}
public void callName(){
System.out.println(this.name);
}
}
public class Main {
public static void main(String[] args) {
A a = new A();
a.methodA("sample"); // nullと出力。(Aクラスのフィールドnameには何も代入されていないから。)
}
}
しかし、ローカル変数内にフィールド名と同じ変数がなければ、thisを使わなくてもフィールドにアクセスすることはできる。
public class A {
String name;
public void methodA(String str){
name = str;
this.callName();
}
public void callName(){
System.out.println(this.name);
}
}
public class Main {
public static void main(String[] args) {
A a = new A();
a.methodA("sample"); // sampleと出力。
}
}
特にインスタンス内のフィールドにアクセスする問題の場合、
①ローカル変数(引数の宣言)が、フィールド名と同じになっているかどうか
②同じの場合、代入式の左辺にthisが付いているかどうか
を意識するとよい。
アクセス修飾子
| 修飾子 | 説明 |
|---|---|
| public | 全てのクラスでアクセス可能。 |
| protected | 同じパッケージもしくは継承しているサブクラスからのみアクセス可能。 |
| なし | 同じパッケージのみアクセス可能。 |
| private | クラス内からのみアクセス可能。 |
package ex1;
public class Sample {
private String str = "str";
private String str2 = "str2";
private String str3 = "str3";
private String str4 = "str4";
public String getStr(){
return str;
}
protected String getStr2(){
return str2;
}
String getStr3(){
return str3;
}
private String getStr4(){
return str4;
}
}
package ex2;
import ex1.Sample;
public class Sample2 extends Sample {
}
package ex2;
public class Main {
public static void main(String[] args){
Sample2 s = new Sample2();
System.out.println(s.getStr());
// コンパイルエラー。(継承関係なしのMainクラス + 違うパッケージからのアクセス)
System.out.println(s.getStr2());
// コンパイルエラー。(違うパッケージからのアクセス)
System.out.println(s.getStr3());
// コンパイルエラー。(違うクラスからのアクセス)
System.out.println(s.getStr4());
}
}
クラス宣言でつけられるアクセス修飾子は、
public か デフォルト の2つだけ。
変数の初期化について
変数には初期化をしなくても良いケースと、初期化をしなければいけないケースがある。
しなくてはいけないケース
①ローカル変数
②finalで修飾されたインスタンス変数・クラス変数。
これら二つは必ず初期化を行わなければならず、行わなかった場合コンパイルエラーとなる。
インスタンス変数・クラス変数の場合、初期化を行う方法は2つ。
public class Sample {
// 方法①
private final String STR = "str";
// 方法②
private final String STR2;
public Sample(String str2) {
this.STR2 = str2;
}
}
しなくても良いケース
その他インスタンス変数・クラス変数など
こちらの場合は、以下のような初期値がデフォルトで設定される。
| 型 | デフォルト値 |
|---|---|
| int | 0 |
| double | 0.0 |
| boolean | false |
| String等参照型 | null |
クラスの継承・インターフェース・抽象クラス
クラスの継承
継承のイメージは以下の通り。
継承されたクラス(スーパークラス)と、継承したクラス(サブクラス)があり、
サブクラスは、スーパークラスのインスタンスと、 差分 のインスタンスを両方合わせて作られている。
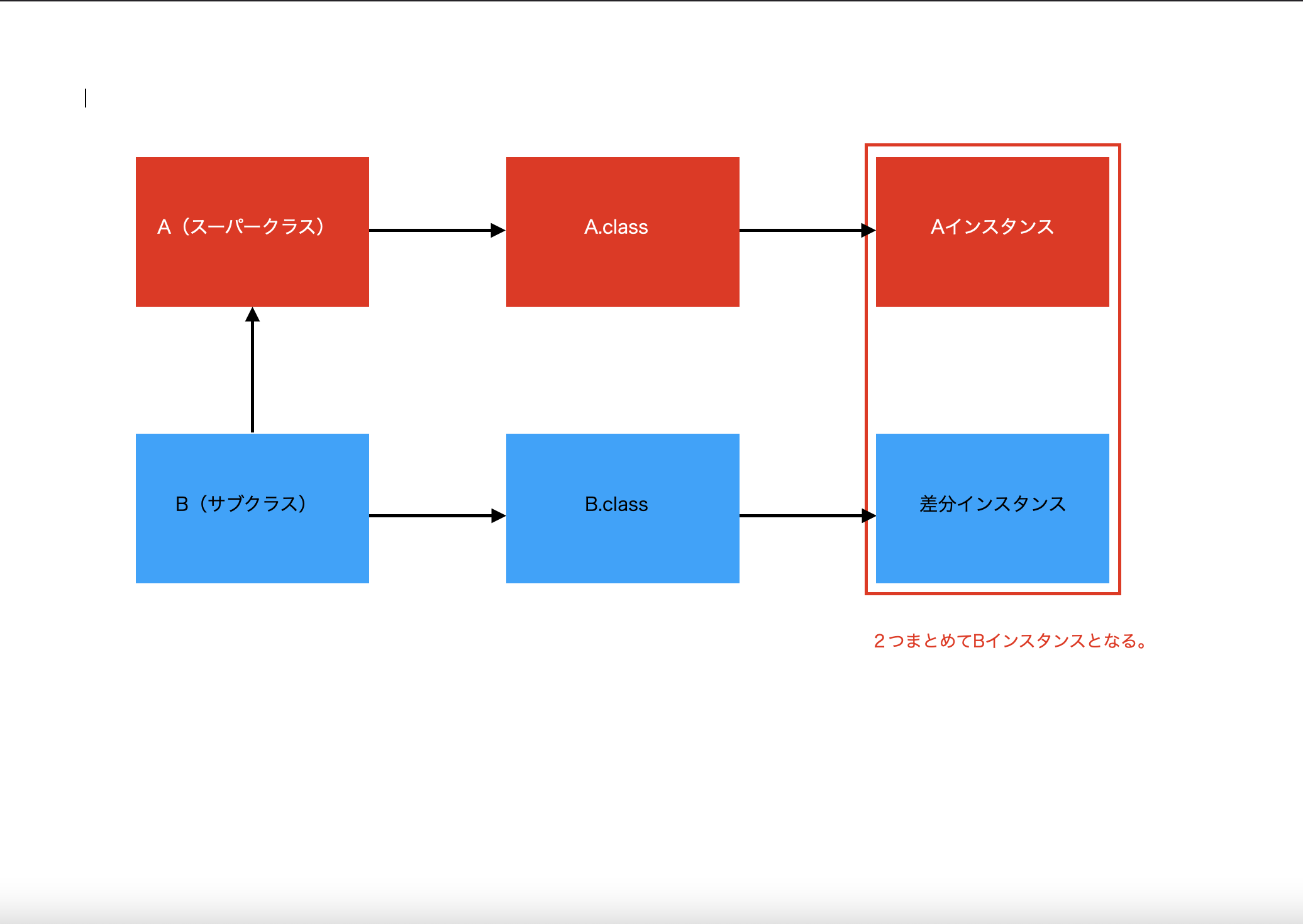
※このイメージがないと、ポリモーフィズムの問題で躓くので注意。
継承を行う上での罠
①継承で引き継げないものがある。
◆private で修飾されたフィールド・メソッド
◆コンストラクタ
...........................................................................................................................................
②クラスの多重継承は禁止されている。
複数のスーパークラスから継承をすることはできない。(extends 〜 は1つだけ)
...........................................................................................................................................
③コンストラクタの呼び出し(super)
サブクラスのコンストラクタを処理する際、まずスーパークラスのコンストラクタから処理される。
public class A {
public A () {
System.out.println("A");
}
}
public class B {
public B () {
System.out.println("B");
}
}
public class Main {
public static void main (String[] args) {
B b = new B(); // A・Bの順番で出力される。
}
}
この時、サブクラスでスーパークラスのコンストラクタを明示的に呼ぶには、以下のように記述する。
public class A {
public A () {
System.out.println("A");
public A (String a) {
System.out.println("AA");
}
}
}
public class B {
public B () {
super(); // Aクラスのコンストラクタを呼び出す。
super("引数あり"); // 引数ありのスーパークラスのコンストラクタの呼び出し
System.out.println("B");
}
}
superの注意点
・super()で呼び出せるのは直前に継承したスーパークラス(1つ上の)のコンストラクタのみ。
・super()は2つ書けない。
public class A {
public A(String str, int num){
System.out.println(str + num);
}
}
public class B extends A {
public B(String str, int num, int num2){
System.out.println(Str + num + num2);
}
}
public class C extends B {
public C(){
super("A",10); // Aクラスのコンストラクタを呼び出そうとしてコンパイルエラー。
super.super("A",10); // Aクラスのコンストラクタを呼び出そうとしてコンパイルエラー。
System.out.println("C");
}
}
・super()は一番上に記入しなければいけない。※super()の上にコードは書けない。
public class A {
public A(){
System.out.println("A");
}
}
public class B extends A {
public B(){
System.out.println("B");
super(); // コンパイルエラー。
}
}
public class Main {
public static void main(String[] args) {
B b = new B();
}
}
・引数なしのsuper()は、明示的に記入しなければ自動で生成される。
public class A {
public A(){
System.out.println("A");
}
}
public class B extends A {
public B(){
// super(); が自動で生成され、Aのコンストラクタを呼び出す。
System.out.println("B");
}
}
public class C extends B {
public C(){
// super(); が自動で生成され、Bのコンストラクタを呼び出す。
System.out.println("C");
}
}
public class Main {
public static void main(String[] args) {
C c = new C(); // A,B,Cの順で出力される。
}
}
ここでの問題は、3個目の注意点。
スーパークラスで 引数有りのコンストラクタだけ を明示的に記入し、super()を自動生成に任せた場合、以下の処理はコンパイルエラーになる。
public class A {
public A (String a) {
System.out.println("AA");
}
}
public class B extends A {
public B () {
System.out.println("B");
}
}
public class Main {
public static void main(String[] args) {
B b = new B();
}
}
自動生成で追加されるのは 引数なしのsuper() であり、スーパークラスのAクラスには引数なしのコンストラクタはない。
また、Aクラスでは引数有りのコンストラクタを明示的に定義したので、 デフォルトコンストラクタ も自動生成されない。
コンパイルエラーを解決するには、Aクラスに 引数なしのコンストラクタ を明示的に定義する必要がある。
...........................................................................................................................................
ポリモーフィズム
インスタンス宣言時、型宣言をスーパークラスでインスタンスをサブクラスで宣言するやり方をポリモーフィズムという。
public class A {}
public class B extends A {}
public class Main {
public static void main(String[] args) {
A a = new B();
}
}
ポリモーフィズムの注意点
フィールドはスーパークラスを参照する。
public class A { public String name = "A"; }
public class B extends A { public String name = "B"; }
public class Main {
public static void main(String[] args) {
A a = new B();
System.out.println(a.name); // Aが出力。
}
}
メソッドはオーバーライドされているかで決まる。
◆オーバーライドされているパターン
public class A {
private String name = "A";
public String getName(){
System.out.println("A");
return this.name;
}
}
public class B extends A {
private String name = "B";
public String getName(){
System.out.println("B");
return this.name;
}
}
public class Main {
public static void main(String[] args) {
A a = new B();
System.out.println(a.getName()); // B B と出力。
}
}
◆オーバーライドされていないパターン
public class A {
private String name = "A";
public String getName(){
System.out.println("A");
return this.name;
}
}
public class B extends A {
private String name = "B";
}
public class Main {
public static void main(String[] args) {
A a = new B();
System.out.println(a.getName()); // A A と出力。
}
}
..........................................................................................................................................
インターフェース
インターフェースとは
クラスから型だけを取り出したもの。
インターフェースの暗黙的ルールと注意点
①アクセス修飾子はpublicのみ
インターフェースは実装されることを前提とされるものなので、インターフェース自身の定義・メソッド・フィールドはすべてpublicのみ修飾が可能。
また、アクセス修飾子の記述を省略した場合、自動的にpublicとして見なされる。
⇨interfaceのメソッドを実装(オーバーライド)するには、必ずアクセス修飾子はpublicである必要がある。
...........................................................................................................................................
②メソッドは実装を記述できない。
インターフェースで定義できるメソッドは、基本的に実装を記述できない。また、
インターフェースで定義する実装なしのメソッドは、public+abstractと見なされる。
interface A { // アクセス修飾子が省略されているが、publicである。
void methodA(); // アクセス修飾子が省略されているが、public+abstractである。
// また、{} を用いた実装は記述できない。
}
しかし実装に関しては例外があり、default修飾子で定義するデフォルトメソッド、もしくは、
static修飾子で定義するstaticメソッドであれば、実装メソッドを定義できる。
interface A {
void methodA();
default void methodB(){}; // defaultメソッドもpublicである。
static void methodC(){}; // staticはインスタンス化せずに利用できるからOK。
}
...........................................................................................................................................
③defaultメソッドで、継承したメソッドを実装することができる。
defaultメソッドで継承・実装したメソッドを実装することはできる。
interface A {
void methodA();
}
interface B implements A {
default void methodA () {};
void methodB();
}
またdefaultメソッドを継承したメソッドから、元のデフォルトメソッドを呼び出すには、以下のように記述する。
インターフェース名.super.メソッド名();
interface A {
default void methodA(){};
}
class B extends A {
@Override
public void methodA () {
A.super.methodA(); // ←
};
void methodB();
}
...........................................................................................................................................
④フィールドはpublic + static + finalになる。
インターフェースでフィールドを定義すると、自動的に public + static + finalになる。
interface A {
int NUMBER = 100; // publicであり、static(インスタンス化不要)な定数(final)である。
}
...........................................................................................................................................
⑤インターフェースは多重継承可能。
インターフェースはクラスと違い、多重継承が可能である。
public class C extends A, B {};
また、実装も複数行うことが可能。
public class C implements A, B {};
...........................................................................................................................................
⑥菱形継承問題
継承・実装どちらも複数対応ができるIFが故に起こる問題。
◆パターン1
interface A {
public void A();
}
interface B extends A {
@overide
default public void A(){
System.out.println("B");
}
}
interface C extends A {
@overide
default public void A(){
System.out.println("C");
}
}
public class D implements B, C {
@overide
public void A(){
super.sample(); // コンパイルエラー。
B.super.sample(); // B と出力。
}
}
この場合、継承している2つのインターフェースどちらも同じメソッドを実装しているため、どちらのメソッドを呼び出せば良いのか判断できずコンパイルエラーとなる。
上記の場合、解決する方法は、superの前にインターフェース名をつけ、どちらのスーパークラス(インターフェース)を呼び出すのか明示的に記述する必要がある。
◆パターン2
public interface A{
public Iterable A();
}
public interface B extends A{
public Collection B();
}
public interface C extends A{
public Path C();
}
public class D extends B, C{
}
上記の場合は、共変戻り値を利用した菱形継承問題。
上記の場合問題なのは、BインターフェースとCインターフェースとで、オーバーライドした際に戻り値が異なっていること。
この場合Dクラスでは、戻り値の都合により、どちらの戻り値を戻すメソッドを引き継げば良いのかがわからず、コンパイルエラーになる。
...........................................................................................................................................
⑦型は使えるがインスタンス化はできない
インターフェースを継承した場合、スーパークラスとして型の利用をすることはできるが、インターフェース自身をインスタンス化することはできない。
public interface A{
public void A();
}
抽象クラスと具象クラス・抽象クラスの実装
抽象クラス
抽象メソッドと、具象メソッドを持つことができるクラスのこと。
抽象クラスの定義には、abstractが必須。
abstract class A {
abstract public void methodA();
public void methodB(){
System.out.println("B");
}
}
具象クラス
具象メソッドを持つクラスのこと。抽象メソッドは持てない。
抽象クラスの罠
①フィールドを定義できる。
抽象クラスは同じように抽象メソッドを持つインターフェースと混同してしまうところがある。
抽象クラスではフィールドを定義することはできる。
インターフェースのように、public + finalにもならない。
...........................................................................................................................................
②クラスのアクセス修飾子は暗黙的にpublic
抽象クラスはアクセス修飾子を記載しないが、暗黙的にpublicになる。
abstract class A { // 抽象クラスは暗黙的にpublic
}
...........................................................................................................................................
③抽象クラスの抽象メソッドは、明示的なabstractの記載が必須。
インターフェースのように、暗黙的にabstractとpublicで認識されるわけではなく、明示的にabstractを記入する必要がある。
abstract class A {
public void methodA(); // abstractで宣言していないので、コンパイルエラーになる。
public void methodB(){
System.out.println("B");
}
}
public class B extends A {
@Override
public void methodA(){
System.out.println("A");
}
}
public class Main {
public static void main(String[] args) {
B b = new B();
}
}
...........................................................................................................................................
④抽象メソッドを持っていなくても抽象クラスを定義することができるが、抽象メソッドを持っているクラスは 強制的に 抽象クラスになる。
抽象クラスは必ず抽象メソッドを持っていなければいけないわけではない。
具象メソッドだけを持っていても、abstractで宣言されていれば、それは抽象クラスとなる。
public abstract class B { // 具象メソッドしか持っていないが、抽象クラス
public void methodA(){
System.out.println("A");
}
public void methodB(){
System.out.println("B");
}
}
public class Main {
public static void main(String[] args) {
B b = new B(); // 具象メソッドしかないが抽象クラスなので、インスタンス化はできずコンパイルエラー
}
}
しかし、abstract宣言していないクラスに抽象メソッドを持たせると、abstract宣言を追加し、抽象クラスとして宣言しなければコンパイルエラーになる。
public class A { //
abstract public void methodA();
public void methodB(){
System.out.println("B");
}
}
...........................................................................................................................................
⑤抽象メソッドはprivate以外も修飾できる。
インターフェースと違い、抽象クラス内で宣言した抽象メソッドは、private以外のアクセス修飾子は修飾することができる。
public interface A {
void methodA(); // アクセス修飾子なしは暗黙的にpublic。
// 他のアクセス修飾子をつけたらコンパイルエラー
}
abstract public class B {
abstract protected void methodA(); // 抽象メソッドならアクセス修飾子は
// public ~ protectedまでOK。
public void methodB(){
System.out.println("B");
}
}
public class C extends B {
@Override
public void methodA(){
System.out.println("A");
}
}
⇨ 抽象メソッドも具象クラスで実装(オーバーライド)する必要があり、そのためにはアクセス修飾子を緩くしなければいけない。
...........................................................................................................................................
⑥抽象クラスで必ず継承して利用する。
抽象クラスは基本的に継承して利用する。
抽象クラスは単体でインスタンス化することはできないので、具象クラスが継承して利用する。
また、抽象メソッドを定義した抽象クラスは、継承した具象クラスで必ずオーバーライドし、実装する必要がある。
abstract class A {
public void methodA();
public void methodB(){
System.out.println("B");
}
}
abstract class B extends A {
@Override
public void methodA(){}; // 継承した具象クラスで必ず実装する。
public void methodB(){
System.out.println("B");
}
}
また、抽象メソッドを実装するのは最後に継承した具象クラスで良い。
abstract class A {
abstract protected void methodA();
}
abstract class B extends A {
public void methodB(){
System.out.println("B");
}
}
public class C extends B {
@Override
public void methodA(){
System.out.println("A");
}
}
public class Main {
public static void main(String[] args) {
C c = new C();
c.methodA(); // Aと出力。
}
}
オーバーライド
オーバーライドとは
メソッドの継承のこと。
継承元に定義されているメソッドを、継承先のメソッドで再定義(上書き)することを指す。
...........................................................................................................................................
オーバーライドの条件
・引数の型・順番・数がすべて同じであること。
public class A {
public String methodA(String a, int b){
return a;
};
}
public class B extends A {
@Override
public String methodA(String a, int b){
System.out.println(b);
return a;
};
}
・戻り値が同じか、サブクラス型であること。
public class A {
public Collection methodA(){};
}
public class B extends A {
@Override
public Collection methodA(){};
}
public class C extends A {
@Override
public List methodA(){};
}
・アクセス修飾子が同じか、より緩いものであること。
public class A {
void methodA(){ return ""; };
}
public class B extends A {
@Override
public void methodA() { // protectedでも可。
System.out.println("B");
};
}
・throwsで宣言する例外は、スローする例外と同じ型かサブクラス型であること。
public class A {
public void methodA()throws Exception{};
}
public class B extends A{
@Override
public void methodA()throws ClassCastException{};
}
関数型インターフェース・ラムダ式
java.util.functionパッケージに属する標準関数型インターフェース
①Predicate<T>
何らかの処理の結果として、boolean型の値を返すための関数。
testメソッドを利用する。
import java.util.function.Predicate
public class Sample {
public static void main(String[] args){
Predicate<String> p = str -> {
return "".equals(str);
};
System.out.println(p.test(args[0]));
}
}
②Supplier<T>
何も受け取らず、結果だけを返す関数。
getメソッドを利用する。
import java.util.function.Supplier
public class Sample {
public static void main(String[] args){
Supplier<String> func = () -> {
return "Hello.";
};
System.out.println(p.get());
}
}
③Consumer<T>
引数を受け取り、処理は戻さない。
acceptメソッドを利用する。
import java.util.function.Consumer
public class Sample {
public static void main(String[] args){
Consumer<String> func = str -> {
System.out.println("Hello" + str);
};
System.out.println(func.accept("java"));
}
}
④Function<T,R>
引数を受け取り、指定された型(R)の結果を返す。
applyメソッドを利用する。
第一引数を受け取り、第二引数を返す。
import java.util.function.Function
public class Sample {
public static void main(String[] args){
Function<String,Integer> func = (str) -> {
return Integer.parseInt(str);
};
System.out.println(func.apply("100") * 2);
}
}
関数型インターフェースとラムダ式
関数型インターフェース
定義されている抽象メソッドが1つだけあるインターフェース。
※複数存在するインターフェースをラムダ式で実装しようとすると、コンパイルエラーとなるので注意。
ラムダ式
関数型インターフェイスを実装したクラスのインスタンスを、ごく短いコーディング量でとても簡単に作れてしまう文法のこと。
interface Function {
void test(String val); // 抽象メソッド1つ
}
public class Main {
public static void main(String[] args){
Function func = (var) -> { System.out.println(val); };
func.test("A");
}
}
関数型インターフェース・ラムダ式の罠
①ラムダ式のスコープは、それを囲むブロックと同じスコープを持つ
ラムダ式と、ラムダ式を囲むブロックは同じスコープになる。
=ラムダ式で宣言する変数(ローカル変数)が、ラムダ式の前のブロックで既に宣言されていたら、コンパイルエラーになる。
public class Main {
public static void main(String[] args){
String var = "Hello";
Function func = (var) -> { System.out.println(val); }; // コンパイルエラー
}
}
/**
* 上記の式では、ラムダ式funcの前にmainメソッドブロックで既に変数varを宣言している。
* funcの引数でvarを宣言しているが、同名のローカル変数は2つ宣言はできないので、コンパイルエラー。
*/
...........................................................................................................................................
②ラムダ式がアクセスする変数は実質的なfinal(定数)でなければならない。
ラムダ式でアクセスできる変数は、実質的にfinal(変更できない・しない)な変数でなければならず、変更するとコンパイルエラーになる。
実質的というのは、finalで宣言されていなくても、変更されない・されていなければアクセスできる。
interface Function {
void test();
}
// 成功例
public class Sample {
public static void main(String[] args){
String str = "Hello";
Function func = () -> { System.out.println(str); }; //アクセス可能。正常終了。
}
func.test();
}
// コンパイルエラー①
public class Sample {
public static void main(String[] args){
String str = "Hello";
Function func = () -> {
str = "See you";
System.out.println(str); // ラムダ式内で変更されているのでコンパイルエラー。
};
func.test();
}
}
// コンパイルエラー②
public class Sample {
public static void main(String[] args){
String str = "Hello";
Function func = () -> {
System.out.println(str); // ラムダ式の後の外で変更されていてもコンパイルエラー。
};
str = "See you";
func.test();
}
}
...........................................................................................................................................
ラムダ式の省略
①()の省略
ラムダ式では引数が1つだけの場合、()を省略できる。
public class Main {
public static void main(String[] args) {
// 通常
Function f = (name) -> { return "hello" + name; };
// 省略
Function f = name -> {return "hello" + name; };
System.out.println(f.test("Java"));
}
private static interface Function {
String test(String name);
}
}
②{}の省略
実行したい処理が一つだけの場合、{}が省略できる。
また、この時{}を省略したら、必然的にreturnも省略しなければいけない。
public class Main {
public static void main(String[] args) {
// コンパイルエラー
Function f = name -> return "hello" + name;
// 正常
Function f = name -> "hello" + name;
System.out.println(f.test("Java"));
}
private static interface Function {
String test(String name);
}
}
モジュールシステム
■モジュール化を行うには、必ずmodule-info.javaが必要である。
■モジュールの設定はmodule-info.javaの中に記述する。
■モジュールの設定では、どのパッケージを公開するかを記述する。(exportsで宣言)
■モジュールの設定では、どのモジュールを利用するかを記述する。(requiresで宣言)
■モジュールでは、標準でjava.baseモジュールが標準で組み込まれている。
■利用するモジュールを伝搬するには、requiresの後に、transitiveを追記する。
■相互間で利用し合う関係だと、コンパイルエラーを起こす。
■モジュールを実行するときには、モジュールに対してクラスパスが通るので、モジュールに含まれるプログラムはモジュール内のディレクトリにアクセス可能である。
// ※module-info.java内
module モジュール名 { // {}内に設定を記述
exports パッケージ名;
requires モジュール名;
requires transitive モジュール名;
}
module A { requires B; } // コンパイルエラー
module B { requires A; } // コンパイルエラー
コマンド一覧
■モジュールを作成する
→ jmod
■モジュールの設定情報を調べる
→ java --describe-module
→ jmod describe
■module-info.javaでexportされていないパッケージを一時的に利用する。
→ javac --add-export
■クラス・メソッド・jarファイル・モジュールの依存関係を調べる
→ jdeps --list-deps
→ java --show-module-resolution
■モジュールファイルのコンパイル(-dオプション)
→ javac -d クラスファイルの出力先ディレクトリ コンパイルするファイルのパス
※モジュールのコンパイルは、module-info.java+その他のソースファイルを一緒にコンパイルする事が基本。
■モジュールの実行(--module-path -mオプション)
→ java --module-path モジュールのルートディレクトリ -m 実行したいモジュールのクラス