はじめに
Amazon Athena を利用する前に理解すべき基礎について、【AWS Black Belt Online Seminar】Amazon Athena - YouTube を参考にまとめました。
Amazon Athena とは
S3 上のデータに対して、標準SQL によるインタラクティブなクエリを投げてデータ分析をできるサービス。特徴については下記参照。
- サーバレスでインフラ管理必要無し
- 大規模データに対しても高速なクエリ
- 事前のデータロードなしに S3 に直接クエリ
- スキャンしたデータに対しての従量課金
- JDBC / ODBC / API 経由で BIツールやシステムと連携
- ODBC : RDBMS にアクセスするための共通インタフェース
- JDBC : Java と関係データベースの接続のためのAPI
ユースケース
- 新しく取得したデータに対して、データウェアハウスに入れる価値があるか探索的に検証
- データウェアハウス(ex. Redshift)は管理コストがかかる
- 利用頻度の低い過去のデータに対する BI ツール経由のアドホックな分析
- データウェアハウスだとストレージコストがかかるため
- Webサーバのログを S3 に保存しておくことで、障害発生時に SQL で原因追求できる
- UNIX コマンドで調査が不要になる
- 程頻度実施のETLツール
Amazon Athena のアーキテクチャ
クエリエンジン
- Presto を利用
- データをディスクに書き出さず、全てメモリ上で処理
- ノード故障やメモリ溢れが起きたらクエリ自体が失敗する
- バッチ処理ではなく、インタラクティブクエリ向け
メタデータの管理
- AWS Glue
- Data Catalog でメタデータを管理する
- メタデータとは、DB / Table / View / Partition
Amazon Athena 基本
テーブル定義
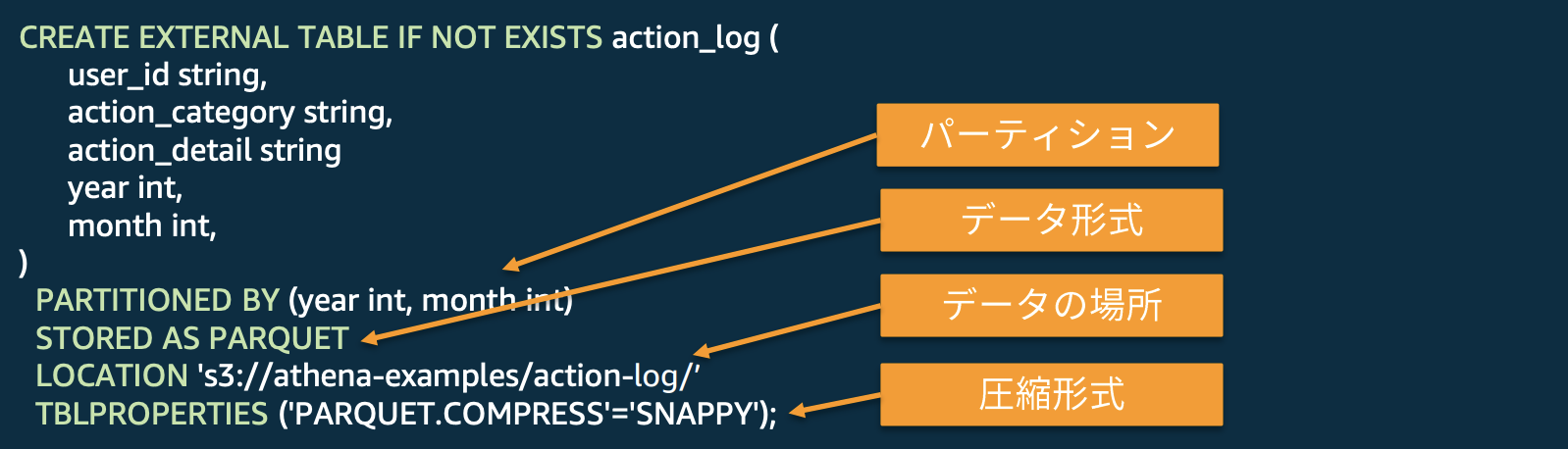
- 標準のテーブル定義の後に、データ形式、圧縮形式、データの場所などを指定
- Glue で S3 データに対して Crawler を投げてテーブル登録することも可能
- スキーマオンリードなので、同一のデータに複数のスキーマを定義可能
- スキーマとはデータベースの設計図のようなもの
利用できるデータ型

データ形式

データの圧縮形式
GZIP はあまり効率的ではない。

対応クエリ
- Presto と同様、標準 ANSI (米国規格協会) SQL に準拠したクエリ
- WITH, Window関数, JOIN などに対応
SQLの標準規格は、ANSI(米国規格協会)やISO(国際標準化機構)といった標準化団体により、数年に一度改訂されます。
改訂ごとに決められた規格は、制定された年ごとに「SQL:1999」「SQL:2003:「SQL:2003」「SQL:2008」「SQL:2011」「SQL:2016」などと呼ばれます。こうした標準規格に準拠したSQLが標準SQLです
ただし、SQLの標準規格に「すべてのRDBMSは標準SQLを使わなければならない」という強制力はありません。標準SQLをサポートしたRDBMSは増えましたが、それでも標準SQLで書いたSQL文を実行できないことがあります。
DDL / クエリの注意点
- DDL(Data Definition Language) とはデータ定義言語のこと
- SQL でいうと
CREATE、DROP、ALTER、TRUNCATE
- SQL でいうと
- DDLでは、EXTERNAL TABLE のみ利用可能
- データは常に S3 にあり、Athena サービス外のため
- VIEW、CTAS にも対応
- 以下の処理には未対応
- トランザクション処理
- UDF / UDAF
- ストアドプロシージャ
Athena API
- Athena はSQL クライアントからだけでなく、プログラムから API を呼び出すことができる
- API は大きく2種類
- Query Execution API
- クエリを実行することに関する API
- Named Query API
- クエリの保存機能に対する API
- Query Execution API
Amazon Athena の特性
- OLTP(Online Transactional Processiong) ではなく、OLAP(Online Analytical Processing)向け
- そもそもトランザクションは未サポート
- ETL ではなく分析向け
- データをフルスキャン&変換するのは高コストな設計
- リトライ機構がないので、安定的なバッチ処理には向かない
- いかにして読み込むデータ量を減らすかが重要
- パーティション
- 列指向フォーマット
- 圧縮
スキャン量の減らし方
Athena の特性において、コスト削減のためにはいかにしてS3から読み込むデータ量を減らすかが重要。減らし方については下記。
パーティション
-
S3 のオブジェクトキーの構成を CREATE TABLE に反映
- 例:
S3://athena-examples/action-logs/year=2020/month=02/day=21/data_01.gzのように保存されている場合、下記のように DDL を発行し、クエリを実行するとWHERE句で絞ったS3 パスのみ読み込まれるためスキャン量が減る。
- 例:
CREATE EXTERNAL TABLE IF NOT EXISTS action_log (
user_id string,
action_category string,
year int,
month int,
day int
)
PARTITIONED BY (year int, month int, day int)
STORED AS PARQUET
LOCATION 's3://athena-examples/action-log/’
TBLPROPERTIES ('PARQUET.COMPRESS'='SNAPPY');
WHERE句で 2016年の4月~7月のデータを指定
SELECT
month
, action_category
, action_detail
, COUNT(user_id)
FROM
action_log
WHERE
year = 2016
AND month >= 4
AND month < 7
GROUP BY
month
, action_category
, action_detail
以下のS3パスのみ読み込まれるのでスキャン量を削減できる

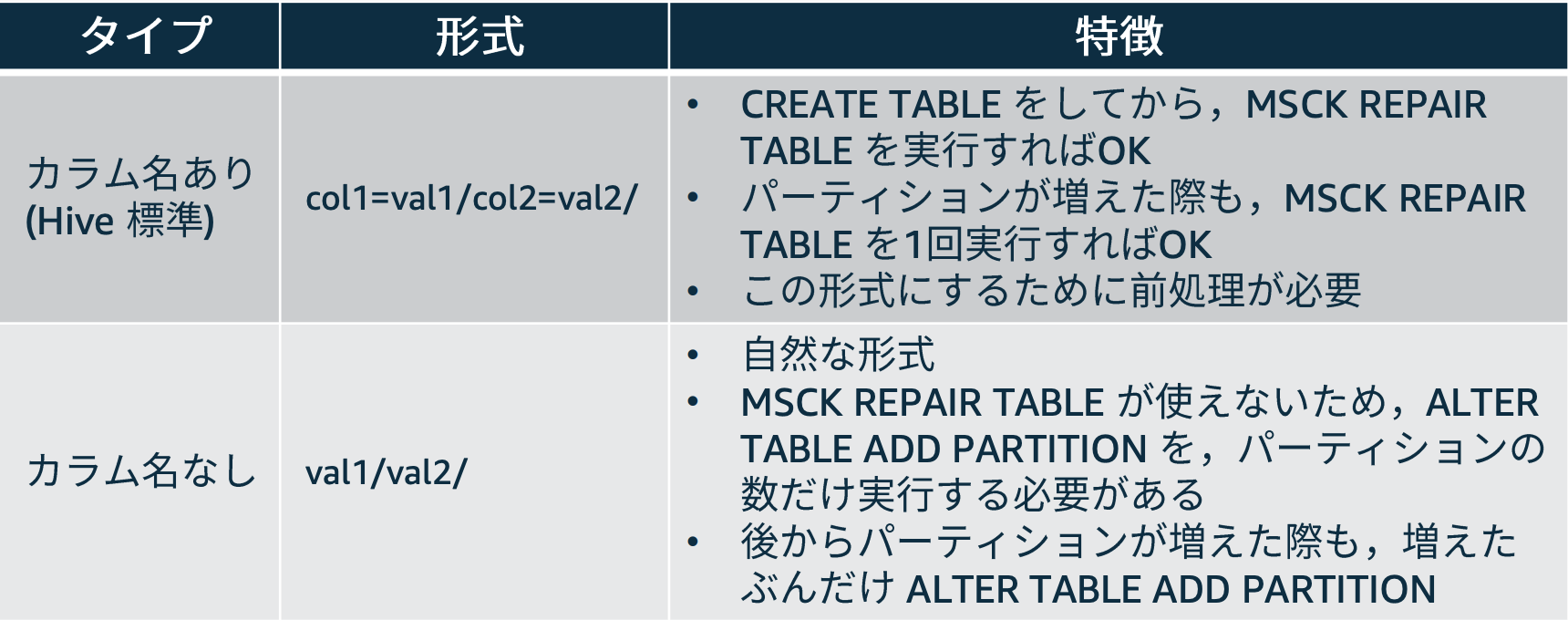
パーティションの分け方
-
s3://athena-examples/action-logs/year=2020/month=02/day=21/data_01.gzのように、col=val1/col2=val2のような Hive 標準の方が推奨- MSCK REPAIR TABLE` は、パーティションを Athena で認識されるためのコマンド
-
s3://athena-examples/action-logs/2020/02/21/data_01.gzのようにval1/val2のような形式もありだが少し面倒