House Prices - Advanced Regression Techniquesとは
House Prices - Advanced Regression Techniquesは、Kaggleが提供する人気のコンペティションの一つです。このコンペは、家の面積や状態など79個の特徴量を使って家の価格(SalePrice)を予測する回帰問題で、回帰分析の練習や特徴量エンジニアリングのスキル向上に役立ちます。私もこのコンペに取り組み、上位9%に入るために様々なアプローチを試行錯誤しました。
本記事の概要
本記事では以下の項目の解説を行います。最後に学びと注意点もまとめているので、Kaggleコンペに挑戦する方や回帰問題に興味がある方の参考になれば幸いです。
- 上位9%に入るために行ったアプローチ
- 簡単なデータ観察
- オブジェクト型特徴量のラベルエンコーディング
- 特徴量エンジニアリング
- ハイパーパラメータのチューニング
- 注意点
- 他に検討したアプローチ
- 重要度の高い特徴量の外れ値処理
- ターゲットエンコーディング
- 欠損値の補完
- 別のモデルの使用
- 学んだこと
- ハイパーパラメータチューニングの重要性
- データ分析におけるChatGPTの有効性
- まとめ
上位9%に入るために行ったアプローチ
簡単なデータ観察
まずは含まれているデータの型の種類を確認します。
# データの読み込み
raw_train_df = pd.read_csv('train.csv')
raw_test_df = pd.read_csv('test.csv')
# 分割するときのためにデータ元が分かるようにしておく
raw_train_df['DataSet'] = 'train'
raw_test_df['DataSet'] = 'test'
# データ結合
df = pd.concat([raw_train_df, raw_test_df], ignore_index=True)
df = df.drop('Id', axis=1)
# データ型の確認
df.dtypes.unique()

出力結果から、今回のデータにはint,object,floatの3種類の型が含まれていることが分かりました。ここからは、データ型に分けて処理を行います。
df_int = df.select_dtypes(include=['int'])
df_obj = df.select_dtypes(include=['object']).drop('DataSet', axis=1)
df_float = df.select_dtypes(include=['float'])
以下が.isnull().sum()で取得したdf_int,df_obj,df_floatの欠損値の数の一覧です。

int型には欠損値がなく、object型には多くの欠損値が、float型にはいくつかの欠損値が含まれることが分かります。
次に目的変数(SalePrice)の分布を可視化してみます。
sns.histplot(df_float['SalePrice'], kde=True)
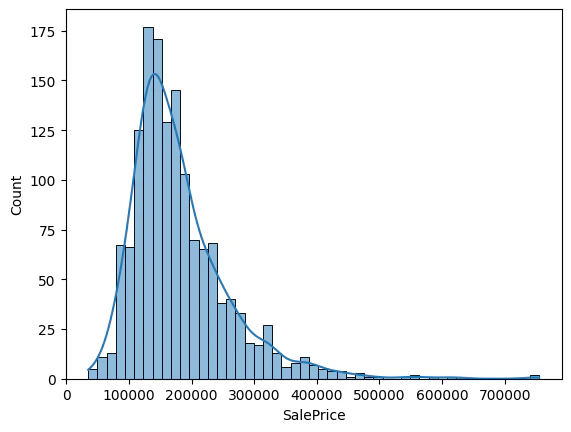
目的変数は右に裾が長いことが分かります。
オブジェクト型特徴量のラベルエンコーディング
'Qual'を含む特徴量の値はEx,Gd,TA,Fa,Poのように明確に順序があるので、それに合わせたマッピングを行います。これは、モデルの特徴量の解釈を容易にするだけではなく、この後の新しい特徴量を作成する際にも役立ちます。
obj_qual_cols = [col for col in df_obj.columns if 'Qual' in col]
qual_mapping = {'Ex':5, 'Gd':4, 'TA':3, 'Fa':2, 'Po':1}
for col in obj_qual_cols:
df_obj[col] =df_obj[col].map(qual_mapping)
その他のobject型のデータに関しては、順序は考慮せずにラベルエンコーディングしていきます。
other_obj_cols = list(filter(lambda x: x not in obj_qual_cols, df_obj.columns))
le = LabelEncoder()
for col in other_obj_cols:
df_obj[col] = le.fit_transform(df_obj[col])
特徴量エンジニアリング
分割していたデータフレームを結合して、特徴量エンジニアリングを行います。新しい特徴量はChatGPTを使用して考えてみました。
# 結合
df_all = pd.concat([df_int, df_obj, df_float, df['DataSet']], axis=1)
# 築年数: YrSold - YearBuilt
df_all['ConstructionAge'] = df_all['YrSold'] - df_all['YearBuilt']
# リフォーム後の経過年数: YrSold - YearRemodAdd
df_all['YrReno'] = df_all['YrSold'] - df_all['YearRemodAdd']
# ガレージ築年数: YrSold - GarageYrBlt
df_all['GarageAge'] = df_all['YrSold'] - df_all['GarageYrBlt']
# 総床面積: 1stFlrSF + 2ndFlrSF + TotalBsmtSF
df_all['TotalFlrArea'] = df_all['1stFlrSF'] + df_all['2ndFlrSF'] + df_all['TotalBsmtSF']
# 地上・地下の居住面積比: GrLivArea / TotalBsmtSF
df_all['GrLivArea_to_TotalBsmtSF'] = df_all['GrLivArea'] / df_all['TotalBsmtSF'].replace(0, 1)
# 敷地あたりの建築面積率: GrLivArea / LotArea
df_all['GrLivArea_to_LotArea'] = df_all['GrLivArea'] / df_all['LotArea']
# ガレージの収容効率: GarageArea / GarageCars
df_all['GarageArea_to_GarageCars'] = df_all['GarageArea'] / df_all['GarageCars']
# 外装品質と面積の総合評価: ExterQual * MasVnrArea
df_all['ExterQual_MasVnrArea'] = df_all['ExterQual'] * df_all['MasVnrArea']
# 全体の品質・状態: OverallQual * OverallCond
df_all['OverallQual_OverallCond'] = df_all['OverallQual'] * df_all['OverallCond']
# バスルーム総数: FullBath + HalfBath + BsmtFullBath + BsmtHalfBath
df_all['TotalBath'] = df_all['FullBath'] + 0.5*df_all['HalfBath'] + df_all['BsmtFullBath'] + 0.5*df_all['BsmtHalfBath']
# ポーチ・デッキ面積の総合: WoodDeckSF + OpenPorchSF + EnclosedPorch + 3SsnPorch + ScreenPorch
df_all['TotalPorchDeckArea'] = df_all['WoodDeckSF'] + df_all['OpenPorchSF'] + df_all['EnclosedPorch'] + df_all['3SsnPorch'] + df_all['ScreenPorch']
# 地上の部屋の総数: TotRmsAbvGrd + BedroomAbvGr
df_all['TotalRoom'] = df_all['TotRmsAbvGrd'] + df_all['BedroomAbvGr']
ハイパーパラメータのチューニング
学習を行う前にデータをトレーニングデータとテストデータに分割し、さらにトレーニングデータをトレーニングデータと検証データに分割します。その際に、不要な列('DataSet'や'SalePrice')は取り除き、目的変数は対数を取って正規分布に近づけておきます。
train_df = df_all[df_all['DataSet']=='train'].drop('DataSet', axis=1)
test_df = df_all[df_all['DataSet']=='test'].drop(['SalePrice', 'DataSet'], axis=1)
train_df['SalePrice'] = np.log(train_df['SalePrice'] + 1)
X_train, X_val, y_train, y_val = train_test_split(train_df.drop('SalePrice', axis=1), train_df['SalePrice'], test_size=0.2, random_state=7)
まずはハイパーパラメータの調整をせずに精度を確認してみます。モデルが返すスコアはRMSEに-1をかけたneg_mean_squared_errorなので、正の値に変換します。(neg_mean_squared_errorを返すのは「値が大きい方が精度が良い」という法則に則っているかららしいです)また、モデルは1番精度の良かったLightGBMを使用します。
from sklearn.model_selection import train_test_split, cross_val_score
from lightgbm import LGBMRegressor, plot_importance
# モデル定義
lgbm = LGBMRegressor(random_state=7, verbose=1)
# クロスバリデーションでRMSEを求める
scores = cross_val_score(lgbm, pd.concat([X_train, X_val]), pd.concat([y_train, y_val]), cv=5, scoring='neg_mean_squared_error')
# RMSEを正の値に変換する
rmse_scores = -scores
# 結果を表示
print(f'Cross-Validated RMSE Scores: {np.round(rmse_scores, 5)}')
print(f'Mean RMSE: {round(np.mean(rmse_scores), 5)}')

ということで、RMSEは0.018ほどになりました。
ここからはグリッドサーチを用いてハイパーパラメータのチューニングをして精度を確認してみます。
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [200, 250, 300],
'max_depth': [5, 10, 15],
'learning_rate': [0.01, 0.05, 0.1],
'feature_fraction': [0.1, 0.15, 0.2],
'num_leaves': [20, 30, 40],
'min_data_in_leaf': [20, 30, 40]
}
gs = GridSearchCV(estimator=lgbm, param_grid=param_grid, scoring='neg_mean_squared_error', cv=5, n_jobs=-1, verbose=3)
gs.fit(pd.concat([X_train, X_val]), pd.concat([y_train, y_val]))
# 最適なパラメータとスコアの表示
print("Best Parameters:", gs.best_params_)
print("Best RMSE:", gs.best_score_)

ということで、RMSEを0.0155まで下げることが出来ました。あとはテストデータを予測して提出用のファイルを作成して終了です。

提出したものの結果は0.12322でした!
注意点
回帰モデルの多くは目的変数が正規分布に従っていることを前提としているため、目的変数は対数を取るなどして正規分布に近づけなけらばならない点に注意が必要です。
他に検討したアプローチ
重要度の高い特徴量の外れ値処理
異常値をモデルの学習データから除外することで、モデルの精度を向上させることが期待できます。まずはトレーニングデータに対する特徴量の重要度をプロットしてみます。
# モデルのトレーニング
model = LGBMRegressor(random_state=7, verbose=-1)
model.fit(X_train, y_train)
show_num = 35
# 'gain'重要度を取得
feature_importances = model.booster_.feature_importance(importance_type='gain')
features = X_train.columns
# データフレームとして整理
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# プロット
plt.figure(figsize=(12, 8))
sns.barplot(x='Importance', y='Feature', data=importance_df[:show_num]);
plt.title('Feature Importances (Gain)')
plt.show()
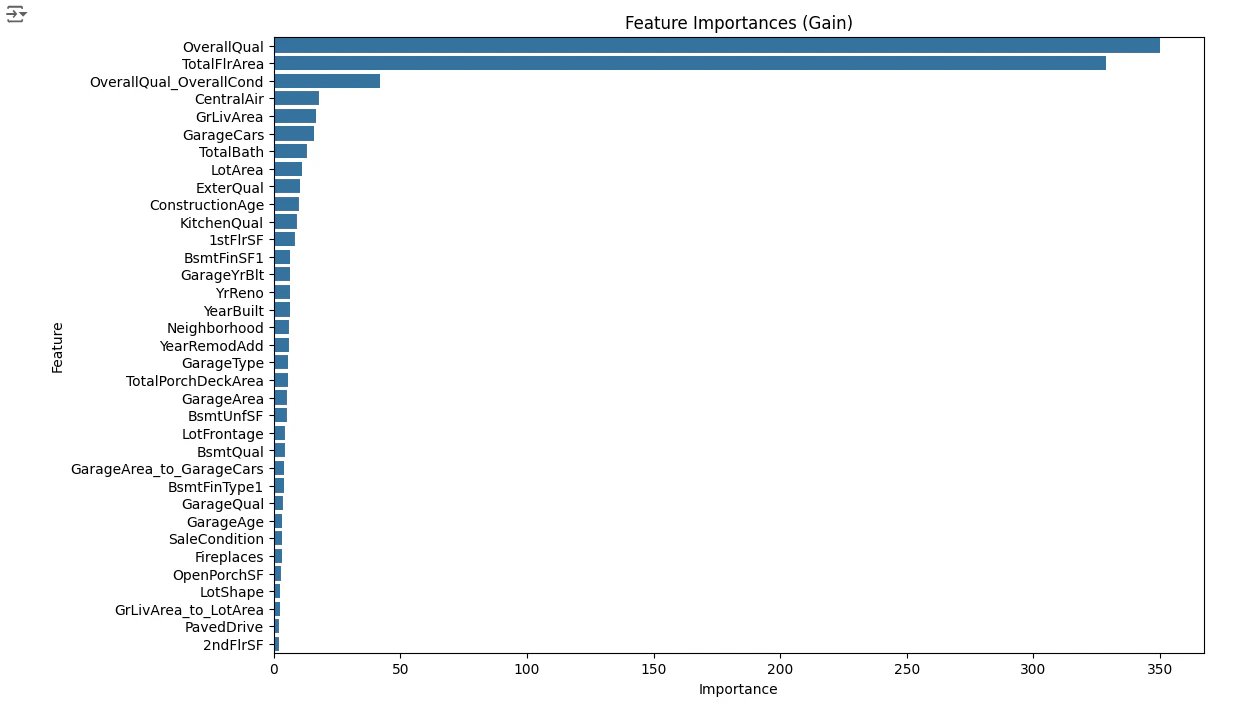
この上位の特徴量のうち、'TotalFlrArea'や'GrLivArea'について外れ値を削除してみたところ、逆に精度は下がってしまいました。今回の外れ値は単なる異常値ではなく重要なパターンだった可能性があります。
ターゲットエンコーディング
十分なデータ数をもつ特徴量についてターゲットエンコーディングを行ったのですが、精度は落ちてしまいました。恐らく過学習によるものだと思います。
欠損値の補完
欠損値の補完を考えましたが、欠損値が多すぎる特徴量があったり、そもそもこのデータにおける欠損値はその設備がないことを意味していたりするらしいので、欠損値のまま扱うことにしました。
別のモデルの使用
RandomForestやXGBoostなどの他の決定木系のモデルも使用してみましたが、最も精度が良かったLightGBMを採用しました。また、決定木系のモデルは欠損値をそのまま扱えるのでコーディングが容易にできるメリットがあります。
学んだこと
ハイパーパラメータチューニングの重要性
今回のコンペでは、ハイパーパラメータの調整によって大きく精度を上げられることを実感しました。そのため、特徴量を変えたり前処理方法を変えたりした場合は、ハイパーパラメータの調整をしてから比較することが重要だと思いました。
データ分析におけるchatGPTの有効性
今回のコンペでは説明変数が79個と多く、新たな特徴量を考えるのが難しかったです。しかし、ChatGPTを使うことで簡単に新たな特徴量を作成することが出来ました。しかし、ChatGPTの出力した新しい特徴量にはいくつかおかしなものが含まれていたので自分でも吟味することが重要です。
まとめ
これらのアプローチにより、回帰問題のイメージを掴みつつ上位9%に入ることが出来ました!Kaggleのコンペに挑戦される方の参考になれば嬉しいです。
