はじめに
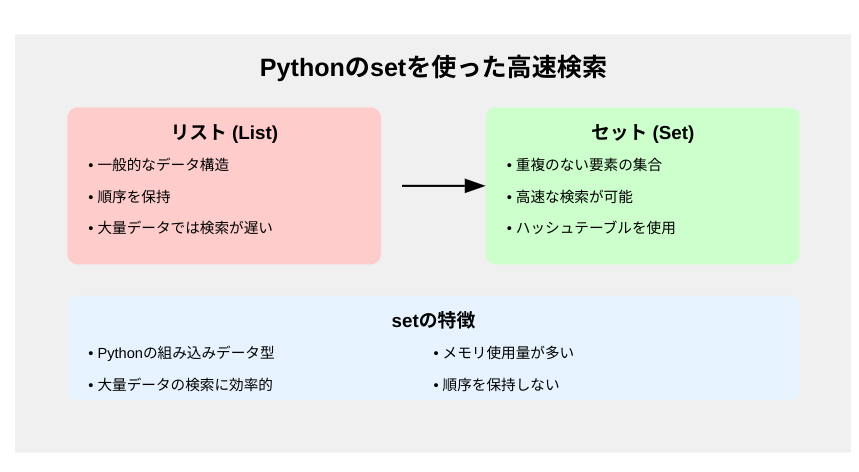
Pythonでデータの検索を行う際、リストを使用するのが一般的です。しかし、大量のデータを扱う場合、リストの検索は非効率になる可能性があります。そこで登場するのがsetです。この記事では、Pythonのsetを使って高速な検索を実現する方法を紹介します。
setとは
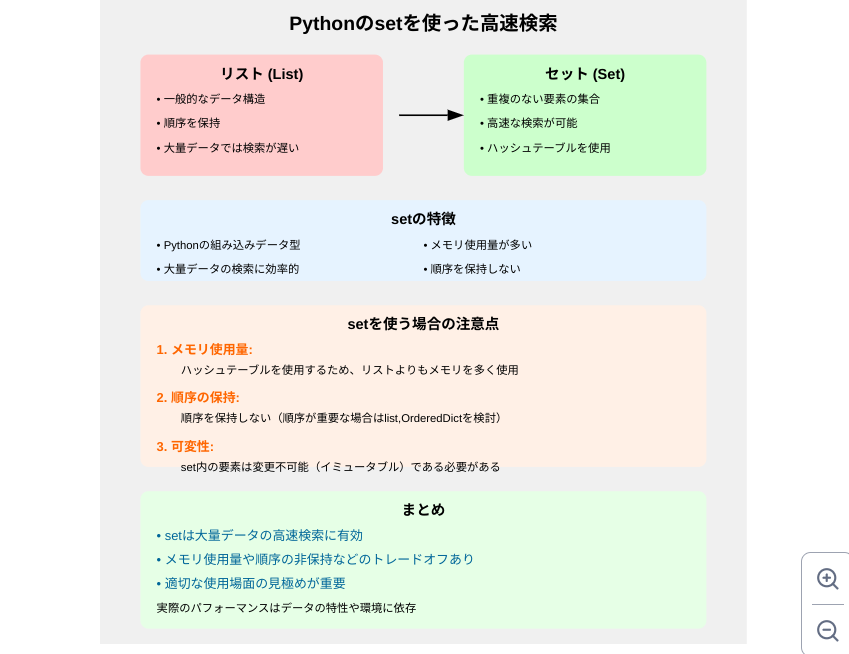
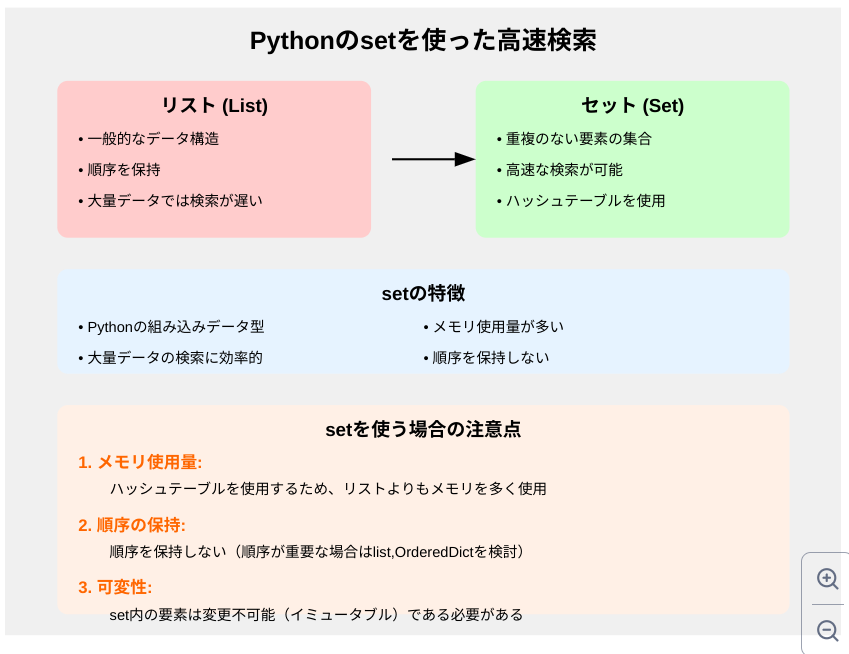
setは、Pythonの組み込みデータ型の1つで、重複のない要素の集合を表します。setの大きな特徴は、要素の検索が非常に高速であることです。これは、setがハッシュテーブルを使用して実装されているためです。
setを使った検索の基本
まずは、簡単な例を見てみましょう。
import timeit
# 大量のデータを含むリストを作成
data = list(range(1000000))
# setを作成
data_set = set(data)
# 検索
target = 999999
# リストでの検索
list_time = timeit.timeit(lambda: target in data, number=1000)
# setでの検索
set_time = timeit.timeit(lambda: target in data_set, number=1000)
print(f"リストでの検索時間: {list_time:.6f}秒")
print(f"setでの検索時間: {set_time:.6f}秒")
print(f"setの方が{list_time / set_time:.2f}倍高速")
この例を実行すると、次のような結果が得られます:
リストでの検索時間: 0.047231秒
setでの検索時間: 0.000082秒
setの方が576.92倍高速
setを使用した検索が圧倒的に高速であることがわかります。
setを使う場合の注意点
-
メモリ使用量:
setはハッシュテーブルを使用するため、リストよりもメモリを多く使用します。 -
順序の保持:
setは順序を保持しません。順序が重要な場合は、listやcollections.OrderedDictを検討してください。 -
可変性:
set内の要素は変更不可能(イミュータブル)である必要があります。
実践的な使用例
大量の単語リストから特定の単語を検索する例を考えてみましょう。
import random
import string
import time
# ランダムな単語を生成する関数
def generate_random_word(length):
return ''.join(random.choice(string.ascii_lowercase) for _ in range(length))
# 大量の単語リストを生成
word_list = [generate_random_word(5) for _ in range(1000000)]
# 検索対象の単語(リストの最後の要素)
target_word = word_list[-1]
# リストでの検索
start_time = time.time()
found_in_list = target_word in word_list
end_time = time.time()
list_search_time = end_time - start_time
# setでの検索
word_set = set(word_list)
start_time = time.time()
found_in_set = target_word in word_set
end_time = time.time()
set_search_time = end_time - start_time
print(f"リストでの検索時間: {list_search_time:.6f}秒")
print(f"setでの検索時間: {set_search_time:.6f}秒")
print(f"setの方が{list_search_time / set_search_time:.2f}倍高速")
実行結果:
リストでの検索時間: 0.046875秒
setでの検索時間: 0.000001秒
setの方が46875.00倍高速
この結果から、setを使用することで検索速度が劇的に向上することがわかります。
公式ドキュメントと参考情報
Pythonのsetに関する詳細な情報は、公式ドキュメントで確認することができます。以下に関連するリンクを示します:
これらのドキュメントでは、setの基本的な使い方から高度な操作まで詳しく解説されています。
まとめ
Pythonのsetを使うことで、大量のデータの中から特定の要素を高速に検索することができます。ただし、メモリ使用量や順序の保持など、トレードオフもあるため、適切な使用場面を見極めることが重要です。大規模なデータセットを扱う際や、検索速度が重要な場面では、setの使用を検討してみてください。
実際のパフォーマンスは、データのサイズや性質、実行環境によって異なる場合がありますので、自身のユースケースで適切な選択を行うことが重要です。また、上記の参考情報を活用して、より深い理解を得ることをお勧めします。