はじめに
こんにちは!今回は、Pythonでファイルを一行ずつ効率的に読み込む方法について解説します。大きなファイルを扱う際に特に役立つテクニックをご紹介します。
まず、テスト用のファイルを作成しましょう。以下のコードを使用して、サンプルファイルを生成します。
def create_sample_file(filename, lines):
with open(filename, 'w') as file:
for i in range(lines):
file.write(f"This is line {i+1} of the sample file.\n")
# サンプルファイルの作成
create_sample_file('sample.txt', 10000)
print("サンプルファイルが作成されました。")
このコードを実行すると、10,000行のテキストを含む sample.txt ファイルが作成されます。
それでは、各方法でこのファイルを読み込んでみましょう。
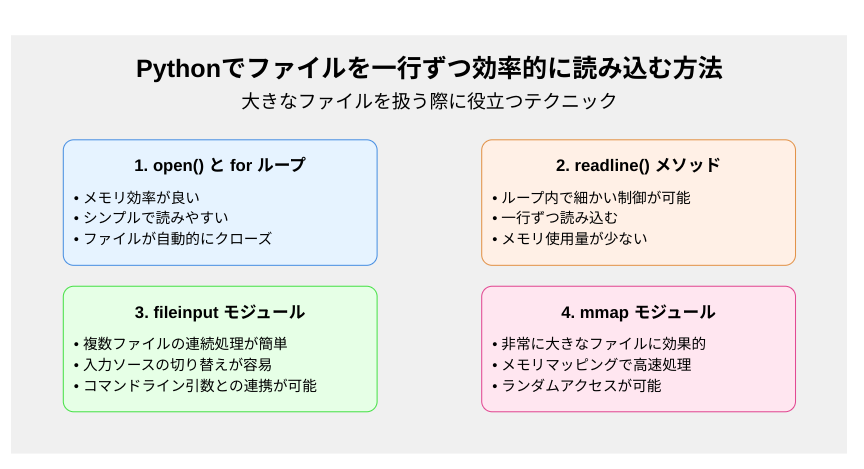
1. open() と for ループを使用する方法
def read_file_with_for_loop(filename):
with open(filename, 'r') as file:
for i, line in enumerate(file, 1):
if i <= 5 or i > 9995:
print(f"Line {i}: {line.strip()}")
elif i == 6:
print("...")
read_file_with_for_loop('sample.txt')
実行結果:
Line 1: This is line 1 of the sample file.
Line 2: This is line 2 of the sample file.
Line 3: This is line 3 of the sample file.
Line 4: This is line 4 of the sample file.
Line 5: This is line 5 of the sample file.
...
Line 9996: This is line 9996 of the sample file.
Line 9997: This is line 9997 of the sample file.
Line 9998: This is line 9998 of the sample file.
Line 9999: This is line 9999 of the sample file.
Line 10000: This is line 10000 of the sample file.
2. readline() メソッドを使用する方法
def read_file_with_readline(filename):
with open(filename, 'r') as file:
for i in range(1, 10001):
line = file.readline()
if i <= 5 or i > 9995:
print(f"Line {i}: {line.strip()}")
elif i == 6:
print("...")
read_file_with_readline('sample.txt')
実行結果:
Line 1: This is line 1 of the sample file.
Line 2: This is line 2 of the sample file.
Line 3: This is line 3 of the sample file.
Line 4: This is line 4 of the sample file.
Line 5: This is line 5 of the sample file.
...
Line 9996: This is line 9996 of the sample file.
Line 9997: This is line 9997 of the sample file.
Line 9998: This is line 9998 of the sample file.
Line 9999: This is line 9999 of the sample file.
Line 10000: This is line 10000 of the sample file.
3. fileinput モジュールを使用する方法
まず、2つのサンプルファイルを作成します。
create_sample_file('sample1.txt', 5)
create_sample_file('sample2.txt', 5)
次に、fileinput を使用して両方のファイルを読み込みます。
import fileinput
def read_files_with_fileinput(filenames):
for line in fileinput.input(filenames):
print(f"{fileinput.filename()}, Line {fileinput.lineno()}: {line.strip()}")
read_files_with_fileinput(['sample1.txt', 'sample2.txt'])
実行結果:
sample1.txt, Line 1: This is line 1 of the sample file.
sample1.txt, Line 2: This is line 2 of the sample file.
sample1.txt, Line 3: This is line 3 of the sample file.
sample1.txt, Line 4: This is line 4 of the sample file.
sample1.txt, Line 5: This is line 5 of the sample file.
sample2.txt, Line 6: This is line 1 of the sample file.
sample2.txt, Line 7: This is line 2 of the sample file.
sample2.txt, Line 8: This is line 3 of the sample file.
sample2.txt, Line 9: This is line 4 of the sample file.
sample2.txt, Line 10: This is line 5 of the sample file.
4. 大容量ファイルの効率的な読み込み(mmap)
import mmap
def read_file_with_mmap(filename):
with open(filename, 'r') as file:
with mmap.mmap(file.fileno(), 0, access=mmap.ACCESS_READ) as mmap_obj:
for i, line in enumerate(iter(mmap_obj.readline, b''), 1):
if i <= 5 or i > 9995:
print(f"Line {i}: {line.decode().strip()}")
elif i == 6:
print("...")
read_file_with_mmap('sample.txt')
実行結果:
Line 1: This is line 1 of the sample file.
Line 2: This is line 2 of the sample file.
Line 3: This is line 3 of the sample file.
Line 4: This is line 4 of the sample file.
Line 5: This is line 5 of the sample file.
...
Line 9996: This is line 9996 of the sample file.
Line 9997: This is line 9997 of the sample file.
Line 9998: This is line 9998 of the sample file.
Line 9999: This is line 9999 of the sample file.
Line 10000: This is line 10000 of the sample file.
まとめ
これらの例を通じて、Pythonでファイルを一行ずつ効率的に読み込む様々な方法を見てきました。各方法には長所があり、状況に応じて最適な方法を選択することが重要です。
-
open()とforループの組み合わせは、最も一般的で使いやすい方法です。 -
readline()メソッドは、より細かい制御が必要な場合に適しています。 -
fileinputモジュールは、複数のファイルを連続して処理する際に便利です。 -
mmapモジュールは、非常に大きなファイルを効率的に処理する場合に有用です。
実際のプロジェクトでは、ファイルサイズ、処理の複雑さ、パフォーマンス要件などを考慮して、最適な方法を選択してください。

公式ドキュメント参照
より詳細な情報については、以下の公式ドキュメントを参照してください:
- open() 関数 - Python 公式ドキュメント
- file オブジェクト - Python 公式ドキュメント
- fileinput モジュール - Python 公式ドキュメント
- mmap モジュール - Python 公式ドキュメント
これらの公式ドキュメントには、各メソッドやモジュールの詳細な使用方法や注意点が記載されています。実際の開発で活用する際は、これらのドキュメントも併せて確認することをおすすめします。