はじめに
正規表現(Regular Expression)は、文字列から特定のパターンを検索したり、情報を抽出したりするための強力なツールです。Pythonでは、reモジュールを使用して正規表現を扱うことができます。
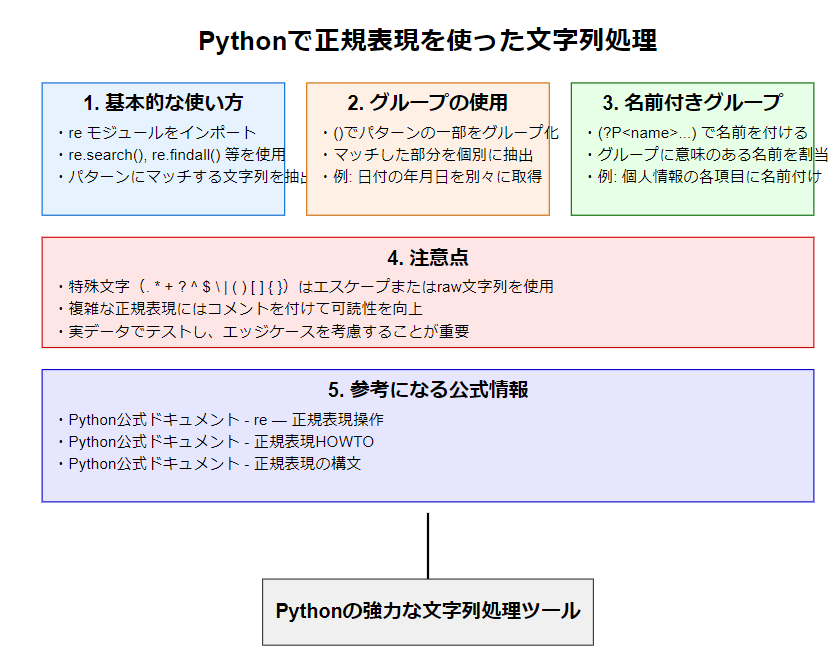
1. 基本的な使い方
まず、reモジュールをインポートします:
import re
次に、re.search()やre.findall()などの関数を使用して、文字列からパターンを検索します。
例1:メールアドレスの抽出
text = "連絡先は、example@email.com と another.example@email.co.jp です。"
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
emails = re.findall(pattern, text)
print(emails)
出力:
['example@email.com', 'another.example@email.co.jp']
2. グループの使用
正規表現内でかっこ()を使用すると、マッチした部分を個別に抽出できます。
例2:日付の抽出
text = "イベントは2023年5月15日から2023年5月17日まで開催されます。"
pattern = r'(\d{4})年(\d{1,2})月(\d{1,2})日'
dates = re.findall(pattern, text)
print(dates)
# 日付を整形して表示
for year, month, day in dates:
print(f"{year}年{month.zfill(2)}月{day.zfill(2)}日")
出力:
[('2023', '5', '15'), ('2023', '5', '17')]
2023年05月15日
2023年05月17日
3. 名前付きグループ
(?P<name>...)構文を使用して、グループに名前を付けることができます。
例3:個人情報の抽出
text = "名前:山田太郎、年齢:30歳、職業:エンジニア"
pattern = r'名前:(?P<name>.*?)、年齢:(?P<age>\d+)歳、職業:(?P<job>.*)'
match = re.search(pattern, text)
if match:
print(f"名前: {match.group('name')}")
print(f"年齢: {match.group('age')}")
print(f"職業: {match.group('job')}")
出力:
名前: 山田太郎
年齢: 30
職業: エンジニア
4. 注意点
- 特殊文字(
.,*,+,?,^,$,\,|,(,),[,],{,})を文字列として扱う場合は、バックスラッシュ\でエスケープするか、raw文字列(r'...')を使用します。 - 複雑な正規表現は可読性が低下する可能性があるため、コメントを付けるなどして説明を加えることをお勧めします。
正規表現は非常に強力ですが、適切に使用しないと予期しない結果を招く可能性があります。実際のデータで十分にテストし、エッジケースも考慮することが重要です。
5. 参考になる公式情報
Pythonの正規表現について詳しく学びたい場合は、以下の公式ドキュメントが参考になります:
-
Python公式ドキュメント - re — 正規表現操作:
https://docs.python.org/ja/3/library/re.htmlこのページでは、
reモジュールの全ての関数と機能について詳細な説明があります。 -
Python公式ドキュメント - 正規表現HOWTO:
https://docs.python.org/ja/3/howto/regex.html正規表現の基本から応用まで、実例を交えて解説しています。
-
Python公式ドキュメント - 正規表現の構文:
https://docs.python.org/ja/3/library/re.html#regular-expression-syntaxPythonで使用できる正規表現の構文について詳しく説明しています。
これらの公式ドキュメントを参照することで、正規表現の理解を深め、より効果的に活用することができます。