はじめに
テキストマイニングは、文章データから有用な情報やパターンを抽出する技術です。この記事では、Google Colabを使って、環境構築から基本的なテキスト分析まで、実践的に学んでいきましょう。
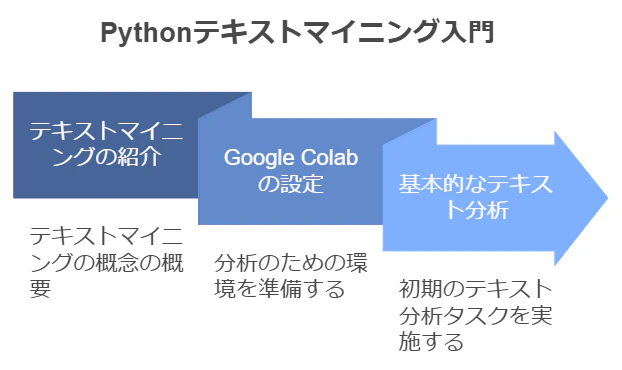
目次
- Google Colab環境のセットアップ
- 必要なライブラリのインストール
- サンプルデータの準備
- 基本的なテキスト分析
- テキストの可視化
- まとめと次回予告
1. Google Colab環境のセットアップ
Google Colabは、ブラウザ上でPythonを実行できる環境です。以下の手順で始めましょう:
- Google Colabにアクセス
- 「新しいノートブック」を作成
- ランタイムタイプをPythonに設定
2. 必要なライブラリのインストール
テキストマイニングに必要な主要ライブラリをインストールします。
# 必要なライブラリのインストール
!apt-get install -y fonts-noto-cjk fonts-noto-cjk-extra
!apt-get install -y mecab mecab-ipadic-utf8 libmecab-dev
!pip install pandas numpy matplotlib seaborn japanize-matplotlib mecab-python3 unidic-lite wordcloud
# MeCabの設定ファイルの存在確認とインストール
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
# ライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from wordcloud import WordCloud
import MeCab
3. サンプルデータの準備
分析用のサンプルテキストを用意します。
# サンプルテキストの準備
sample_texts = [
"私はPythonでプログラミングを勉強しています。",
"テキストマイニングは面白い技術です。",
"データサイエンスの世界は奥が深いです。",
"機械学習とAIの発展は目覚ましいです。",
"プログラミング学習には実践が大切です。",
"データ分析でビジネスの課題を解決します。",
"AIの活用で業務効率が向上しました。",
"Pythonは初心者にも扱いやすい言語です。",
"統計分析の基礎を理解することが重要です。",
"データ可視化で傾向を把握できます。"
]
# DataFrameの作成
df = pd.DataFrame({
'text': sample_texts,
'category': ['学習', '技術', '科学', '技術', '学習',
'ビジネス', 'ビジネス', '技術', '科学', '技術']
})
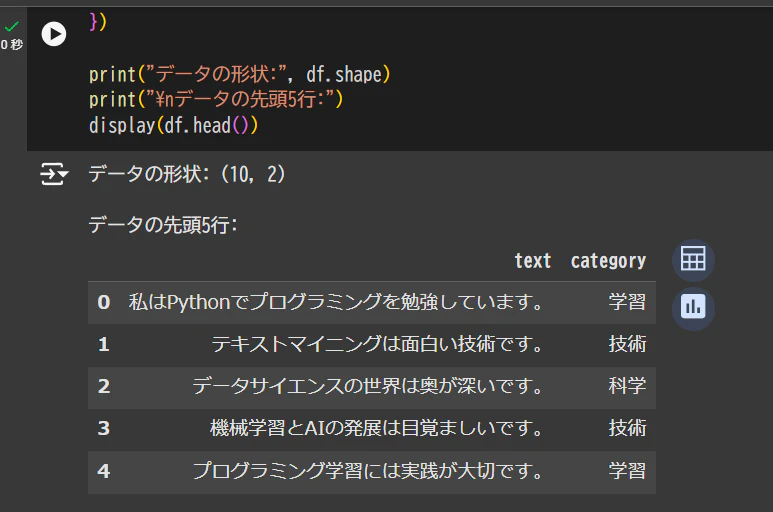
print("データの形状:", df.shape)
print("\nデータの先頭5行:")
display(df.head())
4. 基本的なテキスト分析
テキストの基本的な分析を行います。
def analyze_text(df):
"""
テキストの基本的な分析を行う関数
"""
# 文字数の分析
df['char_count'] = df['text'].str.len()
# 基本統計量の表示
print("文字数の基本統計量:")
print(df['char_count'].describe())
# カテゴリごとの平均文字数
print("\nカテゴリごとの平均文字数:")
print(df.groupby('category')['char_count'].mean())
# 形態素解析
def get_words(text):
try:
mecab = MeCab.Tagger()
node = mecab.parseToNode(text)
words = []
while node:
# node.featureが空でないことを確認
if node.feature:
pos = node.feature.split(',')[0]
# 特定の品詞のみを抽出
if pos in ['名詞', '動詞', '形容詞']:
if node.surface.strip(): # 空白文字をスキップ
words.append(node.surface)
node = node.next
return words
except Exception as e:
print(f"形態素解析エラー: {e}")
return []
# 単語の抽出
df['words'] = df['text'].apply(get_words)
# 頻出単語の分析
from collections import Counter
all_words = [word for words in df['words'] for word in words]
word_count = Counter(all_words)
print("\n頻出単語トップ10:")
for word, count in word_count.most_common(10):
print(f"{word}: {count}回")
return df, word_count
# 分析の実行
df_analyzed, word_count = analyze_text(df)
文字数の基本統計量:
count 10.000000
mean 19.700000
std 2.311805
min 17.000000
25% 18.250000
50% 19.000000
75% 20.000000
max 25.000000
Name: char_count, dtype: float64
カテゴリごとの平均文字数:
category
ビジネス 19.0
学習 22.0
技術 19.0
科学 19.5
Name: char_count, dtype: float64
頻出単語トップ10:
し: 3回
データ: 3回
Python: 2回
プログラミング: 2回
学習: 2回
AI: 2回
分析: 2回
勉強: 1回
い: 1回
テキスト: 1回
5. テキストの可視化
5.1 文字数の分布
plt.figure(figsize=(10, 6))
sns.boxplot(x='category', y='char_count', data=df_analyzed)
plt.title('カテゴリごとの文字数分布')
plt.xlabel('カテゴリ')
plt.ylabel('文字数')
plt.xticks(rotation=45)
plt.show()

5.2 ワードクラウド
def create_wordcloud(word_count):
"""
単語の出現頻度からワードクラウドを生成する関数
"""
# ワードクラウド用のテキスト作成
word_freq = {word: count for word, count in word_count.items()}
# ワードクラウドの生成
wordcloud = WordCloud(
font_path='/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc',
width=800,
height=400,
background_color='white',
max_words=100,
collocations=False
).generate_from_frequencies(word_freq)
plt.figure(figsize=(15, 7))
plt.imshow(wordcloud)
plt.axis('off')
plt.title('Word Cloud')
plt.show()
# ワードクラウドの生成
create_wordcloud(word_count)

5.3 カテゴリごとの特徴語分析
def analyze_category_words(df):
"""
カテゴリごとの特徴的な単語を分析する関数
"""
from collections import Counter
# カテゴリごとの単語をまとめる
category_words = {}
for category in df['category'].unique():
# カテゴリごとのテキストを取得
category_texts = df[df['category'] == category]
# そのカテゴリのすべての単語を結合
all_words = []
for word_list in category_texts['words']:
all_words.extend(word_list)
# 単語のカウント
category_words[category] = Counter(all_words)
print("カテゴリごとの特徴語分析:")
print("-" * 50)
# 各カテゴリの特徴語を表示
for category, word_counter in category_words.items():
print(f"\n【{category}】カテゴリの頻出単語Top5:")
# 単語数が0の場合のチェック
if len(word_counter) == 0:
print("※ 単語が見つかりませんでした")
continue
# 頻出単語の表示
total_words = sum(word_counter.values())
for word, count in word_counter.most_common(5):
percentage = (count / total_words) * 100
print(f"・{word}: {count}回 ({percentage:.1f}%)")
print("\n単語の共起関係:")
print("-" * 50)
# カテゴリ間での共通単語を分析
categories = list(category_words.keys())
for i in range(len(categories)):
for j in range(i + 1, len(categories)):
cat1, cat2 = categories[i], categories[j]
common_words = set(category_words[cat1].keys()) & set(category_words[cat2].keys())
if common_words:
print(f"\n{cat1}と{cat2}の共通単語:")
for word in list(common_words)[:3]: # 上位3つの共通単語を表示
print(f"・{word}: {cat1}({category_words[cat1][word]}回), {cat2}({category_words[cat2][word]}回)")
# カテゴリ分析の実行
analyze_category_words(df_analyzed)
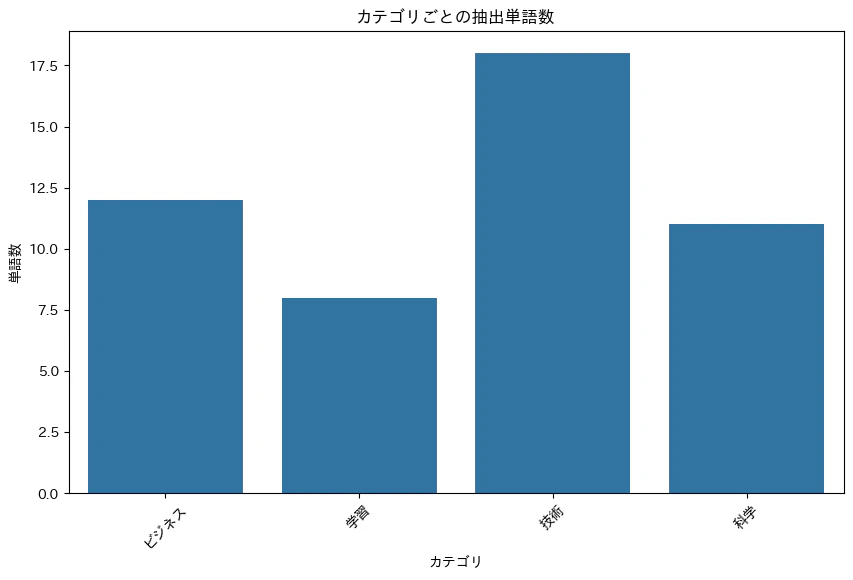
# 可視化: カテゴリごとの単語数の分布
plt.figure(figsize=(10, 6))
category_word_counts = df_analyzed.groupby('category')['words'].apply(lambda x: sum(len(words) for words in x))
sns.barplot(x=category_word_counts.index, y=category_word_counts.values)
plt.title('カテゴリごとの抽出単語数')
plt.xlabel('カテゴリ')
plt.ylabel('単語数')
plt.xticks(rotation=45)
plt.show()
カテゴリごとの特徴語分析:
--------------------------------------------------
【学習】カテゴリの頻出単語Top5:
・プログラミング: 2回 (25.0%)
・Python: 1回 (12.5%)
・勉強: 1回 (12.5%)
・し: 1回 (12.5%)
・い: 1回 (12.5%)
【技術】カテゴリの頻出単語Top5:
・テキスト: 1回 (5.6%)
・マイニング: 1回 (5.6%)
・面白い: 1回 (5.6%)
・技術: 1回 (5.6%)
・機械: 1回 (5.6%)
【科学】カテゴリの頻出単語Top5:
・データ: 1回 (9.1%)
・サイエンス: 1回 (9.1%)
・世界: 1回 (9.1%)
・奥: 1回 (9.1%)
・深い: 1回 (9.1%)
【ビジネス】カテゴリの頻出単語Top5:
・し: 2回 (16.7%)
・データ: 1回 (8.3%)
・分析: 1回 (8.3%)
・ビジネス: 1回 (8.3%)
・課題: 1回 (8.3%)
単語の共起関係:
--------------------------------------------------
学習と技術の共通単語:
・学習: 学習(1回), 技術(1回)
・Python: 学習(1回), 技術(1回)
学習とビジネスの共通単語:
・し: 学習(1回), ビジネス(2回)
技術と科学の共通単語:
・データ: 技術(1回), 科学(1回)
技術とビジネスの共通単語:
・データ: 技術(1回), ビジネス(1回)
・AI: 技術(1回), ビジネス(1回)
科学とビジネスの共通単語:
・データ: 科学(1回), ビジネス(1回)
・分析: 科学(1回), ビジネス(1回)
まとめ
この記事では、以下の内容を学びました:
- Google Colabの環境セットアップ
- 必要なライブラリのインストールと基本的な使い方
- テキストデータの基本的な分析方法
- 形態素解析による単語の抽出
- データの可視化テクニック(ワードクラウド、箱ひげ図)
- カテゴリごとの特徴語分析
参考資料
付録:トラブルシューティング
よくあるエラーと解決方法:
- MeCabのインストールエラー
# 以下のコマンドで再インストール
!apt-get -q -y install mecab swig mecab-ipadic-utf8
!pip install mecab-python3
- WordCloudの日本語フォントエラー
# Noto fontsのインストール
!apt-get install -y fonts-noto-cjk fonts-noto-cjk-extra