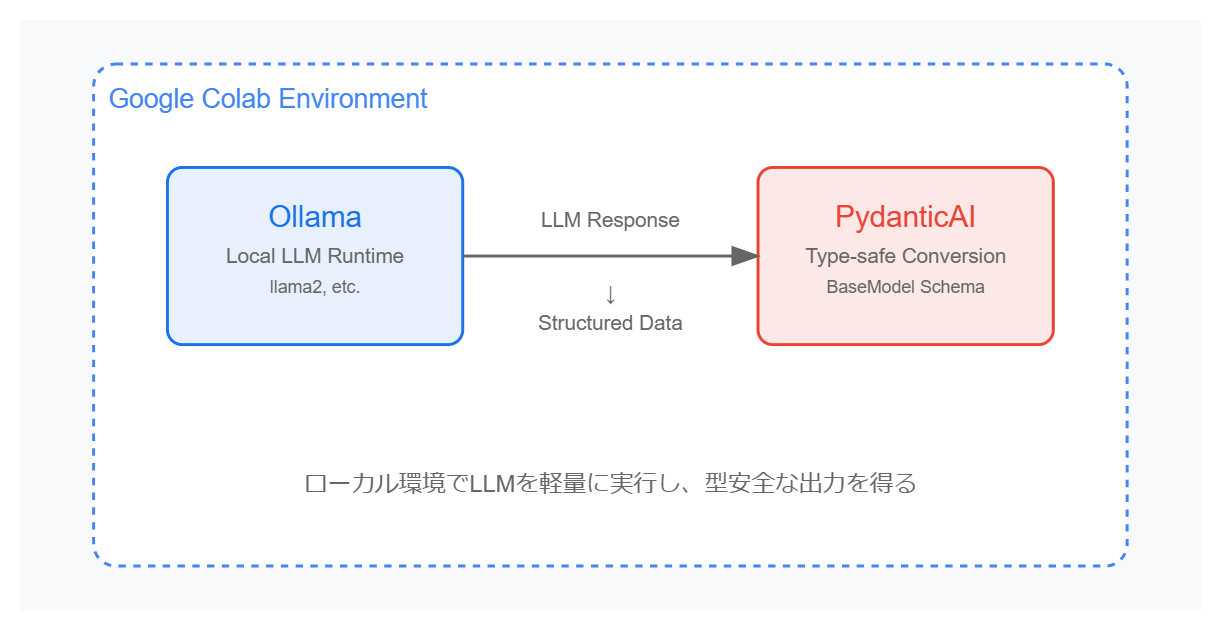
概要
- Ollama: ローカル環境や Colab などで軽量に LLM を動かすためのツール
- PydanticAI: Python の Pydantic を活用して、LLM 出力を型安全に受け取りたい場合に便利なエージェントフレームワーク
今回は、「Google Colab + PydanticAI + Ollama」の組み合わせで、LLM からの回答を構造化してみるハンズオンです。
手順概要
- Ollama のインストール (Colab 上でシェルスクリプト実行)
- モデルの pull (llama3.2 など)
- PydanticAI のインストール と環境設定
- 簡単な Q&A:都市名と国名を構造化して返してもらう
-
カレーの情報を返す実装例:
CurryInfoという型モデルを定義
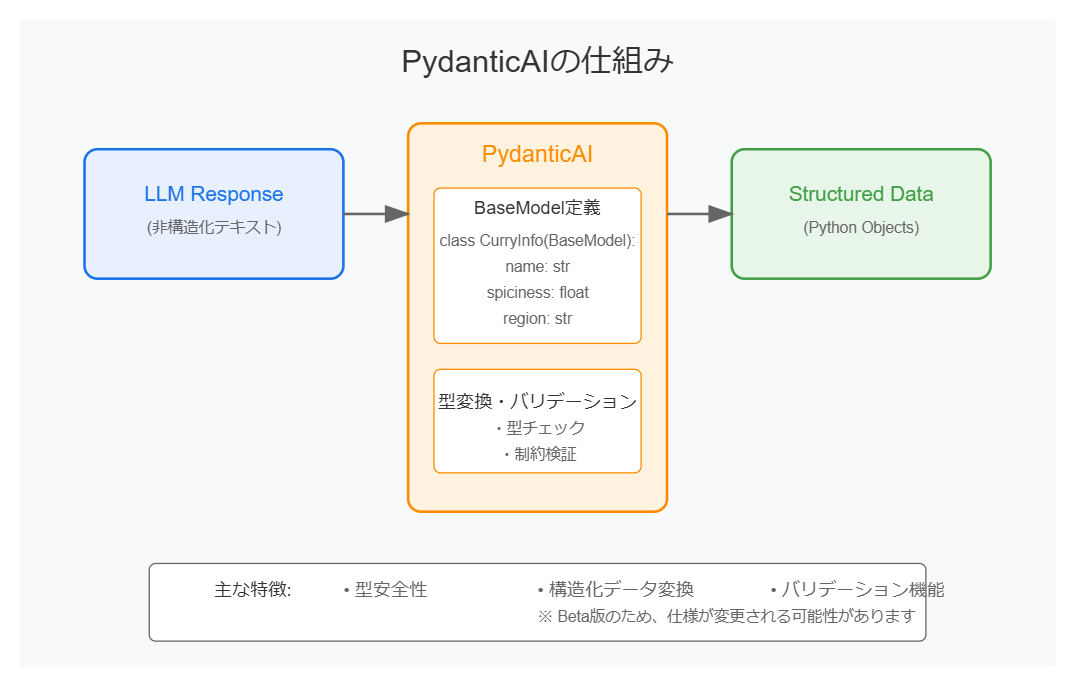
PydanticAIとは
PydanticAIは、PythonでLLM(大規模言語モデル)の出力を型安全に処理するためのツールです。Pydanticで定義されたスキーマ(BaseModel)を活用し、LLMからの出力を構造化データとして取り扱えるようにします。
主な特徴
- 型安全性: LLMの出力をPythonの型に適合させるため、予期しないエラーを防ぐことができます。
- 構造化データ: JSONや辞書型に変換しやすく、データ操作が容易です。
- 柔軟性: フィールド定義にバリデーションや追加情報を含めることで、LLMの回答精度を向上させることができます。
このツールを活用することで、LLMの回答を信頼性の高いデータとして扱い、後続の処理や分析を効率化できます。
注意
この記事で取り上げているPydanticAIは、2025年1月時点でBeta版です。そのため、今後仕様が変更される可能性があります。本記事の内容はあくまでも実験的なものとしてご覧ください。
1. Ollama のインストール
まずは Colab 上で Ollama をインストールします。
下記のコードを Colab のセルに貼り付けて実行してください。
# (Colab向け) Ollama のインストールスクリプトを実行
!curl -fsSL https://ollama.com/install.sh | sh
実行すると、Ollama が
/usr/local/ollamaなどにインストールされ、ollama serveなどのコマンドが使えるようになります。
2. モデルを pull する
次に Ollama サーバーをバックグラウンドで起動し、サンプル用に llama3.2 というモデルを pull します。
# Ollama サーバーを起動 & LLMモデルをpull
!nohup ollama serve &
!ollama pull llama3.2
ここで時間がかかる場合があります(モデルサイズやネットワーク速度に依存)。
3. PydanticAI のインストールと nest_asyncio 設定
PydanticAI は pip でインストールできます。Colab のノートブックでは以下のように:
!pip -q install pydantic-ai
!pip -q install nest_asyncio
import nest_asyncio
nest_asyncio.apply()
print("Setup complete!")
このとき、
google-authのバージョン衝突による警告が出るかもしれませんが、今回のサンプルでは無視してOKです。
4. シンプルな Q&A(都市&国名の例)
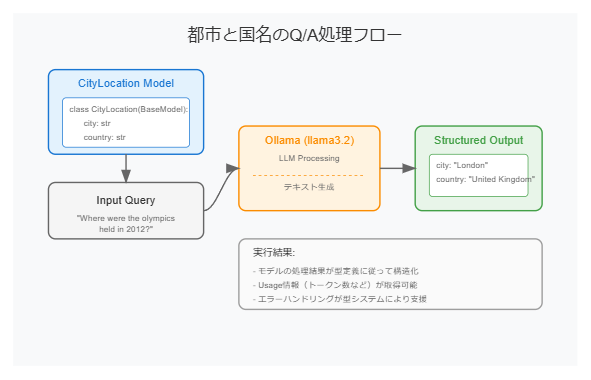
ここから Python で実際に PydanticAI を使って回答を構造化します。たとえば、以下のようなクラス CityLocation を定義して「都市名」と「国名」を受け取る例です。
from pydantic import BaseModel
from pydantic_ai import Agent
class CityLocation(BaseModel):
city: str
country: str
# Ollama の 'llama3.2' モデルで回答を取得し、
# CityLocation で構造化
agent = Agent(
'ollama:llama3.2',
result_type=CityLocation
)
# Q1: 2012年のオリンピック開催都市はどこ?
question1 = "Where were the olympics held in 2012?"
result1 = agent.run_sync(question1)
print("[Q1]", question1)
print("[A1]", result1.data) # -> CityLocation型
print("Usage1:", result1.usage())
実行結果の例
[Q1] Where were the olympics held in 2012?
[A1] city='London' country='United Kingdom'
Usage1: Usage(requests=1, request_tokens=..., response_tokens=..., total_tokens=..., details=None)
5. カレーの特徴を返す例:CurryInfo
もう少し複雑なフィールドを持った例として、カレーの情報を受け取る CurryInfo というモデルを定義してみます。
from pydantic import BaseModel, Field
from pydantic_ai import Agent
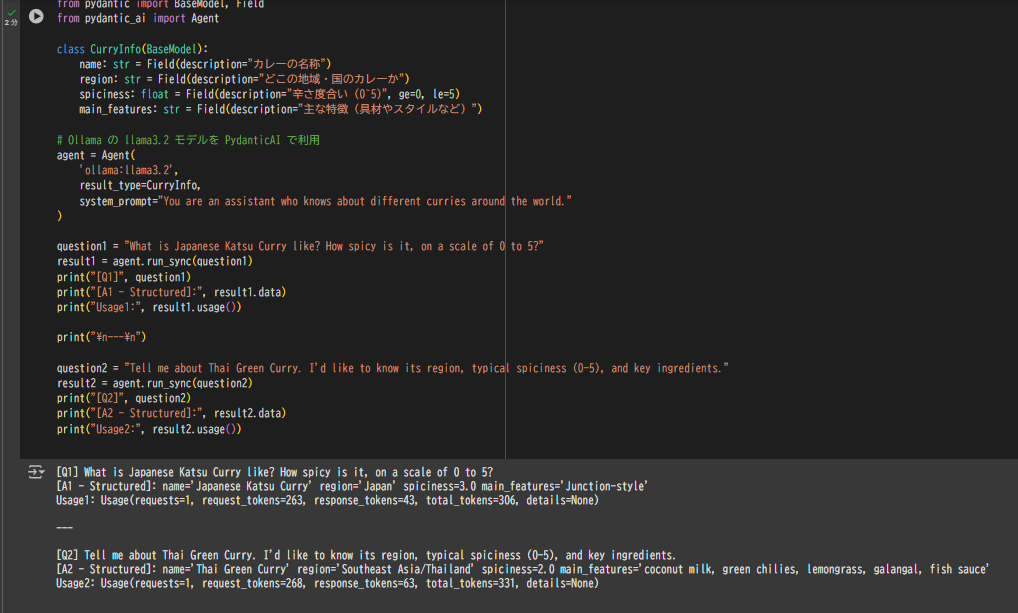
class CurryInfo(BaseModel):
name: str = Field(description="カレーの名称")
region: str = Field(description="どこの地域・国のカレーか")
spiciness: float = Field(description="辛さ度合い (0~5)", ge=0, le=5)
main_features: str = Field(description="主な特徴(具材やスタイルなど)")
# Ollama の llama3.2 モデルを PydanticAI で利用
agent = Agent(
'ollama:llama3.2',
result_type=CurryInfo,
system_prompt="You are an assistant who knows about different curries around the world."
)
question1 = "What is Japanese Katsu Curry like? How spicy is it, on a scale of 0 to 5?"
result1 = agent.run_sync(question1)
print("[Q1]", question1)
print("[A1 - Structured]:", result1.data)
print("Usage1:", result1.usage())
print("
---
")
question2 = "Tell me about Thai Green Curry. I'd like to know its region, typical spiciness (0-5), and key ingredients."
result2 = agent.run_sync(question2)
print("[Q2]", question2)
print("[A2 - Structured]:", result2.data)
print("Usage2:", result2.usage())
実行結果例
[Q1] What is Japanese Katsu Curry like? How spicy is it, on a scale of 0 to 5?
[A1 - Structured]: name='Japanese Katsu Curry' region='Japan' spiciness=3.0 main_features='Crispy fried cutlet served over rice with a mildly sweet curry sauce'
Usage1: Usage(requests=1, request_tokens=..., response_tokens=..., ...)
---
[Q2] Tell me about Thai Green Curry. I'd like to know its region, typical spiciness (0-5), and key ingredients.
[A2 - Structured]: name='Thai Green Curry' region='Thailand' spiciness=4.0 main_features='Made with coconut milk, fresh green chilies, lemongrass, galangal, and fish sauce'
Usage2: Usage(requests=1, request_tokens=..., response_tokens=..., ...)
まとめ
- Ollama + PydanticAI を Google Colab で組み合わせて使い、LLM 出力を構造化するハンズオンを紹介しました
- LLM の出力を「Python の型」に落とし込むことで、アプリケーション側で型安全に扱えるメリットがあります
- ただし、最終的には LLM のテキスト生成に依存するため、完全に正しい形式で返ってくる保証はありません。適宜バリデーションや再要求を行う必要があります
補足
- Google ColabでランタイムのタイプはCPUで確認しました。処理に多少時間はかかりますが、動作することは確認できました。
- 今回使用した
llama3.2以外にも対応モデルはあります。興味ありましたら公式ページを確認ください。
実装例(ノートブック)
PydanticAI_sample.ipynb
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "intro-markdown"
},
"source": [
"# Ollama × PydanticAI のシンプルサンプル\n",
"\n",
"このノートブックでは、[Ollama](https://ollama.ai/) を使って LLM を起動し、[PydanticAI](https://github.com/pydantic/pydantic-ai) を用いて回答を構造化します。\n",
"\n",
"以下の流れで進めます:\n",
"1. Ollama のインストール & モデルのダウンロード\n",
"2. PydanticAI のインストール\n",
"3. シンプルな Q&A(都市と国名を返す例)\n",
"\n",
"> **備考**: Colab での環境構築には制約がある場合があります。Ollama がサポートしているモデルの詳細は公式ドキュメントを参照してください。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "ollama-install"
},
"outputs": [],
"source": [
"# (Colab向け) Ollama のインストールスクリプトを実行\n",
"!curl -fsSL https://ollama.com/install.sh | sh"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "ollama-serve-pull"
},
"outputs": [],
"source": [
"# Ollama サーバーを起動 & LLMモデルをpull\n",
"!nohup ollama serve &\n",
"!ollama pull llama3.2"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "pydantic-install"
},
"outputs": [],
"source": [
"# PydanticAI のインストールと nest_asyncio 設定\n",
"!pip -q install pydantic-ai\n",
"!pip -q install nest_asyncio\n",
"import nest_asyncio\n",
"nest_asyncio.apply()\n",
"\n",
"print(\"Setup complete!\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "simple-sample-markdown"
},
"source": [
"## シンプルなサンプル\n",
"以下の例では、`BaseModel` で `city` と `country` のフィールドを持つ `CityLocation` クラスを定義し、LLM からの回答を構造化して受け取ります。\n",
"\n",
"### 例1: 「Where were the olympics held in 2012?」"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "city-country-sample"
},
"outputs": [],
"source": [
"from pydantic import BaseModel\n",
"from pydantic_ai import Agent\n",
"\n",
"class CityLocation(BaseModel):\n",
" city: str\n",
" country: str\n",
"\n",
"# Ollama の 'llama3.2' モデルで回答を取得し、CityLocationで構造化\n",
"agent = Agent(\n",
" 'ollama:llama3.2',\n",
" result_type=CityLocation\n",
")\n",
"\n",
"# --- 例1 ---\n",
"question1 = \"Where were the olympics held in 2012?\"\n",
"result1 = agent.run_sync(question1)\n",
"print(\"[Q1]\", question1)\n",
"print(\"[A1]\", result1.data)\n",
"print(\"Usage1:\", result1.usage())\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "explanation-end"
},
"source": [
"上記のように、PydanticAI は LLM の出力を `CityLocation` (city, country) 形式で受け取ろうとします。\n",
"質問1では『2012年のオリンピック開催都市』\n",
"\n",
"これでシンプルな例として、**LLM の回答を Python の型安全なモデルにマッピングする**流れが確認できます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "8GH_GjmGbesV"
},
"outputs": [],
"source": [
"from pydantic import BaseModel, Field\n",
"from pydantic_ai import Agent\n",
"\n",
"class CurryInfo(BaseModel):\n",
" name: str = Field(description=\"カレーの名称\")\n",
" region: str = Field(description=\"どこの地域・国のカレーか\")\n",
" spiciness: float = Field(description=\"辛さ度合い (0~5)\", ge=0, le=5)\n",
" main_features: str = Field(description=\"主な特徴(具材やスタイルなど)\")\n",
"\n",
"# Ollama の llama3.2 モデルを PydanticAI で利用\n",
"agent = Agent(\n",
" 'ollama:llama3.2',\n",
" result_type=CurryInfo,\n",
" system_prompt=\"You are an assistant who knows about different curries around the world.\"\n",
")\n",
"\n",
"question1 = \"What is Japanese Katsu Curry like? How spicy is it, on a scale of 0 to 5?\"\n",
"result1 = agent.run_sync(question1)\n",
"print(\"[Q1]\", question1)\n",
"print(\"[A1 - Structured]:\", result1.data)\n",
"print(\"Usage1:\", result1.usage())\n",
"\n",
"print(\"\\n---\\n\")\n",
"\n",
"question2 = \"Tell me about Thai Green Curry. I'd like to know its region, typical spiciness (0-5), and key ingredients.\"\n",
"result2 = agent.run_sync(question2)\n",
"print(\"[Q2]\", question2)\n",
"print(\"[A2 - Structured]:\", result2.data)\n",
"print(\"Usage2:\", result2.usage())\n"
]
}
],
"metadata": {
"colab": {
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}