はじめに
こんにちは!この記事では、PythonとSeleniumを使ってWebブラウザを自動操作する方法について、Google検索を例に解説します。

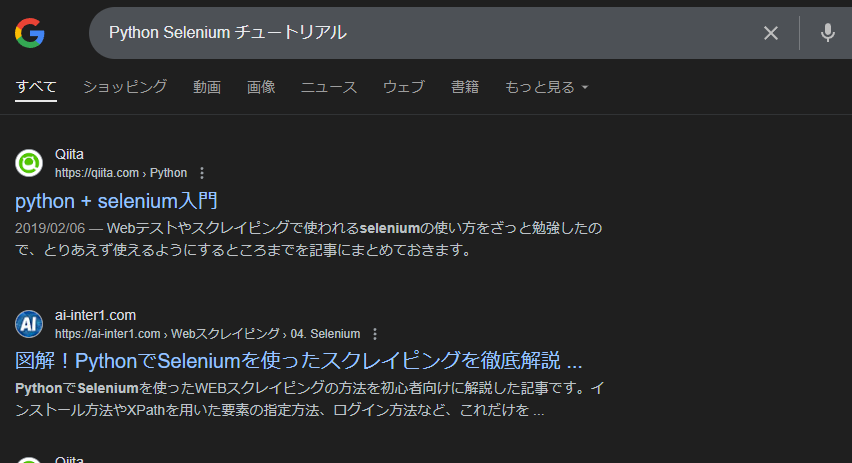
ブラウザが起動されて、検索キーワードを自動で入力して検索する。
Windows 11の環境の実行例:

環境準備
まず必要なものをインストールしましょう。
- Python (3.7以上)
- Selenium
- WebDriver Manager
pip install selenium
pip install webdriver-manager
基本的なコード実装
以下に、Google検索を自動化する基本的な実装を示します:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
import time
def google_search(search_query):
# ブラウザのオプション設定
options = webdriver.ChromeOptions()
# options.add_argument('--headless') # ヘッドレスモードを使う場合はコメントを外す
# ChromeDriverの設定
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
try:
# Googleにアクセス
driver.get('https://www.google.com')
# 検索ボックスを見つけて検索語を入力
search_box = driver.find_element(By.NAME, 'q')
search_box.send_keys(search_query)
search_box.send_keys(Keys.RETURN)
# 検索結果が表示されるまで待機
wait = WebDriverWait(driver, 10)
results = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'div.g'))
)
# 検索結果を出力
for i, result in enumerate(results[:5], 1):
try:
title = result.find_element(By.CSS_SELECTOR, 'h3').text
link = result.find_element(By.CSS_SELECTOR, 'a').get_attribute('href')
print(f"\n結果 {i}:")
print(f"タイトル: {title}")
print(f"URL: {link}")
except:
continue
time.sleep(2) # 結果を確認するための待機時間
finally:
driver.quit() # ブラウザを終了
if __name__ == "__main__":
google_search("Python Selenium チュートリアル")
コードの解説
1. 必要なライブラリのインポート
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
SeleniumのWebDriverと関連するモジュールをインポートします。
2. WebDriverの設定
options = webdriver.ChromeOptions()
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
ChromeDriverを自動でダウンロード・設定します。webdriver_managerを使うことで、ChromeDriverの手動インストールが不要になります。
3. 要素の待機
wait = WebDriverWait(driver, 10)
results = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'div.g'))
)
明示的な待機を実装することで、ページの読み込みや要素の表示を適切に待つことができます。
応用:より実践的な機能追加
以下は、検索結果をファイルに保存し、スクリーンショットも取得できる完全な実装例です。
このスクリプトは単独で実行可能で、より実践的な機能を備えています:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from datetime import datetime
import time
import json
import os
class GoogleSearchAutomation:
def __init__(self, output_dir="search_results"):
"""
検索結果保存用のディレクトリを初期化
"""
self.output_dir = output_dir
if not os.path.exists(output_dir):
os.makedirs(output_dir)
os.makedirs(os.path.join(output_dir, "screenshots"))
def setup_driver(self):
"""
ChromeDriverのセットアップ
"""
options = webdriver.ChromeOptions()
# options.add_argument('--headless') # ヘッドレスモードを使う場合はコメントを外す
options.add_argument('--window-size=1920,1080')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
service = Service(ChromeDriverManager().install())
return webdriver.Chrome(service=service, options=options)
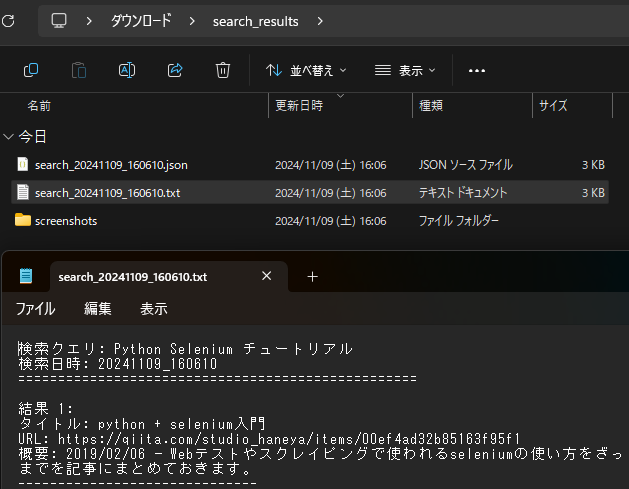
def save_results(self, search_query, results):
"""
検索結果をJSONとテキストファイルの両方に保存
"""
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# JSONファイルに保存
json_file = os.path.join(self.output_dir, f"search_{timestamp}.json")
with open(json_file, "w", encoding="utf-8") as f:
json.dump({
"query": search_query,
"timestamp": timestamp,
"results": results
}, f, ensure_ascii=False, indent=2)
# テキストファイルに保存
txt_file = os.path.join(self.output_dir, f"search_{timestamp}.txt")
with open(txt_file, "w", encoding="utf-8") as f:
f.write(f"検索クエリ: {search_query}\n")
f.write(f"検索日時: {timestamp}\n")
f.write("=" * 50 + "\n\n")
for i, result in enumerate(results, 1):
f.write(f"結果 {i}:\n")
f.write(f"タイトル: {result['title']}\n")
f.write(f"URL: {result['url']}\n")
if result.get('description'):
f.write(f"概要: {result['description']}\n")
f.write("-" * 30 + "\n\n")
return json_file, txt_file
def take_screenshot(self, driver, search_query):
"""
検索結果のスクリーンショットを保存
"""
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
screenshot_path = os.path.join(
self.output_dir,
"screenshots",
f"search_{timestamp}.png"
)
driver.save_screenshot(screenshot_path)
return screenshot_path
def search(self, query, max_results=5):
"""
Google検索を実行し、結果を取得・保存
"""
driver = self.setup_driver()
try:
# Googleにアクセス
driver.get('https://www.google.com')
# 検索ボックスを見つけて検索実行
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.NAME, 'q'))
)
search_box.send_keys(query)
search_box.send_keys(Keys.RETURN)
# 検索結果の待機
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.g'))
)
# スクリーンショット取得
screenshot_path = self.take_screenshot(driver, query)
# 検索結果の取得
search_results = []
results = driver.find_elements(By.CSS_SELECTOR, 'div.g')
for result in results[:max_results]:
try:
title_elem = result.find_element(By.CSS_SELECTOR, 'h3')
link_elem = result.find_element(By.CSS_SELECTOR, 'a')
# 概要文を取得(存在する場合)
try:
description = result.find_element(
By.CSS_SELECTOR,
'div.VwiC3b'
).text
except NoSuchElementException:
description = None
search_results.append({
'title': title_elem.text,
'url': link_elem.get_attribute('href'),
'description': description
})
except (NoSuchElementException, TimeoutException) as e:
print(f"結果の取得中にエラー: {str(e)}")
continue
# 結果の保存
json_file, txt_file = self.save_results(query, search_results)
return {
'results': search_results,
'files': {
'json': json_file,
'text': txt_file,
'screenshot': screenshot_path
}
}
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
return None
finally:
driver.quit()
def main():
"""
使用例
"""
# 検索オートメーションの初期化
automation = GoogleSearchAutomation()
# 検索実行
search_query = "Python Selenium チュートリアル"
results = automation.search(search_query)
if results:
print("\n検索結果の概要:")
print("-" * 30)
for i, result in enumerate(results['results'], 1):
print(f"\n結果 {i}:")
print(f"タイトル: {result['title']}")
print(f"URL: {result['url']}")
if result.get('description'):
print(f"概要: {result['description']}")
print("\n保存されたファイル:")
print(f"JSON: {results['files']['json']}")
print(f"テキスト: {results['files']['text']}")
print(f"スクリーンショット: {results['files']['screenshot']}")
if __name__ == "__main__":
main()
使用方法:
# 基本的な使用法
automation = GoogleSearchAutomation()
results = automation.search("Python Selenium チュートリアル")
# カスタマイズした使用法
automation = GoogleSearchAutomation(output_dir="custom_results")
results = automation.search("Python Selenium チュートリアル", max_results=10)
実行後の出力例:
エラーハンドリング
実践的なWeb自動化では、適切なエラーハンドリングが重要です:
from selenium.common.exceptions import (
TimeoutException,
NoSuchElementException,
WebDriverException
)
def robust_google_search(search_query):
try:
driver = setup_driver()
try:
driver.get('https://www.google.com')
except WebDriverException as e:
print(f"ページアクセスエラー: {e}")
return
try:
search_box = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.NAME, 'q'))
)
except TimeoutException:
print("検索ボックスが見つかりませんでした")
return
search_box.send_keys(search_query)
search_box.send_keys(Keys.RETURN)
try:
results = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'div.g'))
)
except TimeoutException:
print("検索結果の取得に失敗しました")
return
process_results(results)
except Exception as e:
print(f"予期せぬエラーが発生しました: {e}")
finally:
if 'driver' in locals():
driver.quit()
注意点とベストプラクティス
-
待機時間の設定
-
time.sleep()の代わりにWebDriverWaitを使用 - 明示的な待機で安定性を向上
-
-
リソース管理
-
try-finallyでドライバーを確実に終了 - コンテキストマネージャの活用
-
-
要素の特定
- できるだけIDやname属性を使用
- XPathは最終手段として使用
-
ヘッドレスモード
- バックグラウンド実行時は
--headlessオプションを使用 - デバッグ時は通常モードを使用
- バックグラウンド実行時は
まとめ

公式のSelenium、Python、WebDriver Managerのドキュメントから学びましょう。
WebDriverWait、CSSセレクタ、XPath、ページオブジェクトモデル(POM)などの発展的なトピックを探求しましょう。
この記事では、PythonとSeleniumを使ってGoogle検索を自動化する方法を紹介しました。
基本的な実装から、ファイル出力やエラーハンドリングまで、実践的なコード例を示しました。
これらの基礎を応用することで、より複雑なWeb自動化タスクも実装できるようになります。
発展的な学習のために
- Seleniumの公式ドキュメント
- WebDriverWaitの詳細な使い方
- CSSセレクタとXPathの使い分け
- ページオブジェクトモデル(POM)の実装