はじめに
本チュートリアルでは、カレーに関する情報をRDFデータとして作成し、それをNeo4jの知識グラフに変換する方法を学びます。RDFデータの作成から始めることで、データモデリングの基礎から実際のグラフデータベースへの変換まで、一貫したプロセスを体験できます。
目次
- カレー情報のRDFデータの作成
- 必要なツールのインストール
- RDFデータの読み込みと解析
- Neo4jデータベースの準備
- RDFデータのNeo4jへの変換
- 結果の確認とクエリ
1. カレー情報のRDFデータの作成
まず、カレーに関する簡単なRDFデータを作成します。以下の内容をcurry.ttlというファイル名で保存してください。このファイルはTurtle形式で記述されています。
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix curry: <http://example.org/curry/> .
curry:JapaneseCurry rdf:type curry:CurryType ;
rdfs:label "Japanese Curry"@en ;
curry:origin "Japan" ;
curry:popularDish curry:KatsuCurry, curry:CurryUdon .
curry:IndianCurry rdf:type curry:CurryType ;
rdfs:label "Indian Curry"@en ;
curry:origin "India" ;
curry:popularDish curry:ButterChicken, curry:TikkaMasala .
curry:ThaiCurry rdf:type curry:CurryType ;
rdfs:label "Thai Curry"@en ;
curry:origin "Thailand" ;
curry:popularDish curry:GreenCurry, curry:MassamanCurry .
curry:KatsuCurry rdf:type curry:Dish ;
rdfs:label "Katsu Curry"@en ;
curry:mainIngredient "Pork cutlet" .
curry:CurryUdon rdf:type curry:Dish ;
rdfs:label "Curry Udon"@en ;
curry:mainIngredient "Udon noodles" .
curry:ButterChicken rdf:type curry:Dish ;
rdfs:label "Butter Chicken"@en ;
curry:mainIngredient "Chicken" .
curry:TikkaMasala rdf:type curry:Dish ;
rdfs:label "Tikka Masala"@en ;
curry:mainIngredient "Chicken" .
curry:GreenCurry rdf:type curry:Dish ;
rdfs:label "Green Curry"@en ;
curry:mainIngredient "Vegetables" .
curry:MassamanCurry rdf:type curry:Dish ;
rdfs:label "Massaman Curry"@en ;
curry:mainIngredient "Beef" .
このRDFデータは、3つのカレータイプ(日本、インド、タイ)と、それぞれに関連する代表的な料理を記述しています。
2. 必要なツールのインストール
以下のツールをインストールしてください:
- Python 3.x
- RDFlib:
pip install rdflib - Neo4j Python Driver:
pip install neo4j - Neo4jデータベース(ローカルまたはクラウド版)
3. RDFデータの読み込みと解析
以下のPythonスクリプトを使用して、RDFデータを読み込み、解析します。
from rdflib import Graph, Namespace, RDF, RDFS
# RDFグラフの読み込み
g = Graph()
g.parse("curry.ttl", format="turtle")
# 名前空間の定義
CURRY = Namespace("http://example.org/curry/")
# トリプルの出力
print("RDFデータの内容:")
for subj, pred, obj in g:
print(f"Subject: {subj}, Predicate: {pred}, Object: {obj}")
# カレータイプの数を表示
curry_types = list(g.subjects(predicate=RDF.type, object=CURRY.CurryType))
print(f"\n総カレータイプ数: {len(curry_types)}")
# カレータイプとその原産国を表示
print("\nカレータイプと原産国:")
for curry_type in curry_types:
label = g.value(subject=curry_type, predicate=RDFS.label)
origin = g.value(subject=curry_type, predicate=CURRY.origin)
print(f"{label}: {origin}")
# 各カレータイプの代表的な料理を表示
print("\n代表的な料理:")
for curry_type in curry_types:
label = g.value(subject=curry_type, predicate=RDFS.label)
dishes = list(g.objects(subject=curry_type, predicate=CURRY.popularDish))
dish_names = [g.value(subject=dish, predicate=RDFS.label) for dish in dishes]
print(f"{label}: {', '.join(dish_names)}")
このスクリプトを実行すると、RDFデータの内容、カレータイプの数、各カレータイプの原産国、および代表的な料理が表示されます。
4. Neo4jデータベースの準備
- Neo4jデータベースを起動します。
- 新しいデータベースを作成するか、既存のデータベースを使用します。
- 接続情報(URL、ユーザー名、パスワード)をメモしておきます。
5. RDFデータのNeo4jへの変換
以下のPythonスクリプトを使用して、RDFデータをNeo4jに変換します。
from rdflib import Graph, Namespace, RDF, RDFS
from neo4j import GraphDatabase
# RDFグラフの読み込み
g = Graph()
g.parse("curry.ttl", format="turtle")
# 名前空間の定義
CURRY = Namespace("http://example.org/curry/")
# Neo4jへの接続
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
def create_curry_type(tx, uri, label, origin):
tx.run("MERGE (c:CurryType {uri: $uri}) "
"SET c.label = $label, c.origin = $origin",
uri=uri, label=label, origin=origin)
def create_dish(tx, uri, label, main_ingredient):
tx.run("MERGE (d:Dish {uri: $uri}) "
"SET d.label = $label, d.mainIngredient = $main_ingredient",
uri=uri, label=label, main_ingredient=main_ingredient)
def create_curry_dish_relation(tx, curry_uri, dish_uri):
tx.run("MATCH (c:CurryType {uri: $curry_uri}), (d:Dish {uri: $dish_uri}) "
"MERGE (c)-[:HAS_POPULAR_DISH]->(d)",
curry_uri=curry_uri, dish_uri=dish_uri)
with driver.session() as session:
# カレータイプノードの作成
for curry_type in g.subjects(predicate=RDF.type, object=CURRY.CurryType):
label = g.value(subject=curry_type, predicate=RDFS.label)
origin = g.value(subject=curry_type, predicate=CURRY.origin)
session.execute_write(create_curry_type, str(curry_type), str(label), str(origin))
# 料理ノードの作成とリレーションシップの設定
for curry_type in g.subjects(predicate=RDF.type, object=CURRY.CurryType):
for dish in g.objects(subject=curry_type, predicate=CURRY.popularDish):
label = g.value(subject=dish, predicate=RDFS.label)
main_ingredient = g.value(subject=dish, predicate=CURRY.mainIngredient)
session.execute_write(create_dish, str(dish), str(label), str(main_ingredient))
session.execute_write(create_curry_dish_relation, str(curry_type), str(dish))
driver.close()
print("データの変換が完了しました。")
このスクリプトを実行すると、RDFデータがNeo4jデータベースに変換されます。
6. 結果の確認とクエリ
Neo4j Browserを開き、以下のCypherクエリを実行して結果を確認します:
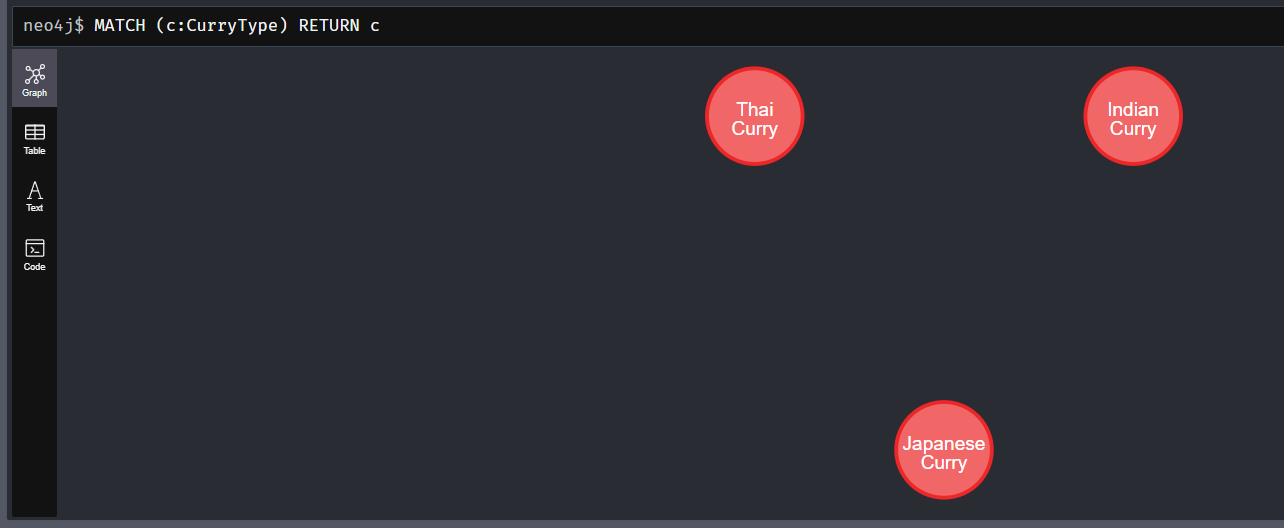
// すべてのカレータイプを取得
MATCH (c:CurryType) RETURN c
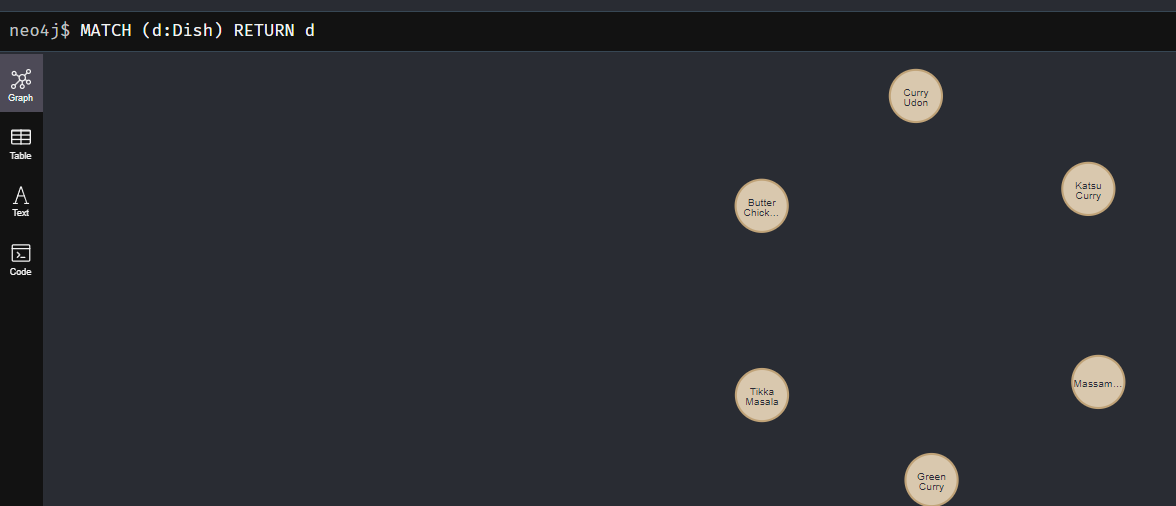
// すべての料理を取得
MATCH (d:Dish) RETURN d
// カレータイプとその代表的な料理を取得
MATCH (c:CurryType)-[:HAS_POPULAR_DISH]->(d:Dish)
RETURN c.label, c.origin, COLLECT(d.label) AS popular_dishes
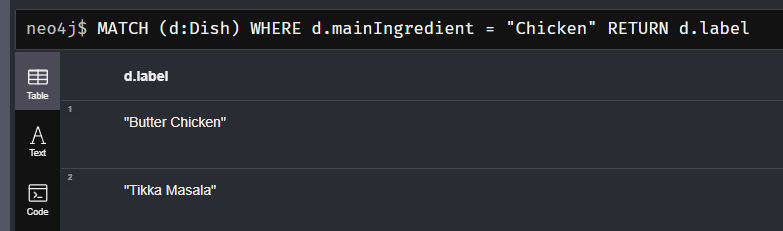
// 特定の主要食材を使用する料理を取得
MATCH (d:Dish)
WHERE d.mainIngredient = "Chicken"
RETURN d.label
// カレータイプごとの料理数を取得
MATCH (c:CurryType)-[:HAS_POPULAR_DISH]->(d:Dish)
RETURN c.label, COUNT(d) AS dish_count
ORDER BY dish_count DESC
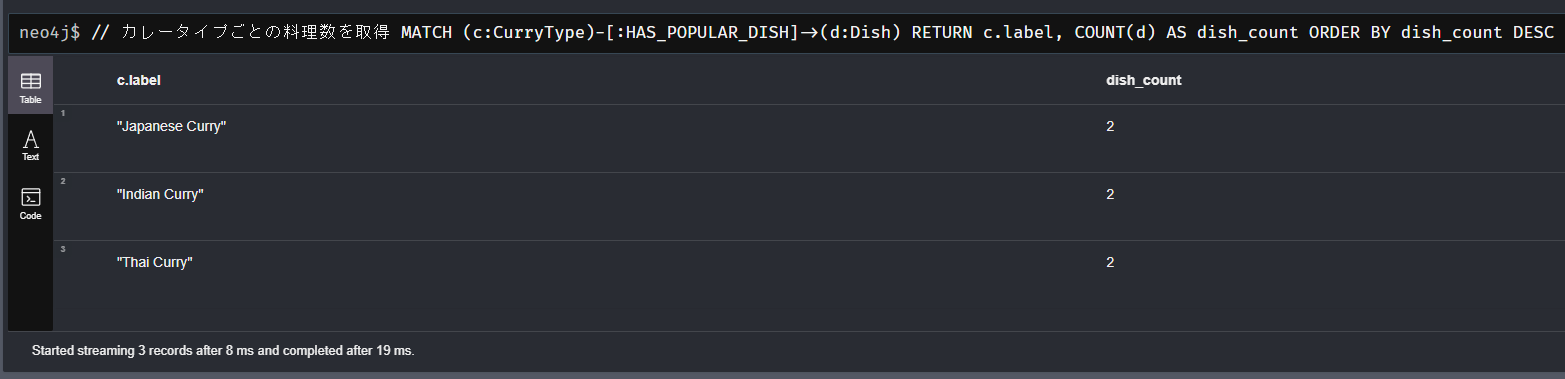
これらのクエリを実行することで、RDFデータが正しくNeo4jの知識グラフに変換されたことを確認できます。
まとめ
このチュートリアルでは、カレーに関する情報をRDFデータとして作成し、それをNeo4jの知識グラフに変換する方法を学びました。RDFデータの作成から始めることで、データモデリングの基礎から実際のグラフデータベースへの変換まで、一貫したプロセスを体験できました。
重要な点として、このプロセスは既存の公開されているRDFデータにも適用できます。多くの組織や機関が様々な分野のRDFデータを公開しており、これらを活用することで、より豊富で複雑な知識グラフを構築することができます。例えば、DBpedia、GeoNames、FOAFなどの広く使用されているRDFデータセットを利用することで、カレーデータと地理情報や人物情報を組み合わせた多角的な分析が可能になります。
次のステップとして、以下の発展的なトピックを探求することをお勧めします:
- より大規模で複雑なカレー関連データの作成と処理
- 外部のオープンデータソースとの統合(例:料理レシピデータベース)
- 高度なNeo4jクエリの作成とグラフアルゴリズムの適用
- カレーレコメンデーションシステムの構築
RDFデータとグラフデータベースを組み合わせることで、複雑なデータ間の関係性を効果的に表現し、分析することができます。この知識を活用して、料理データの分析や、より広範な分野でのデータモデリングに取り組んでみてください。