セマンティック検索とベクトルデータベースの記事を公開しました。カレーレシピを例に、意図を理解した検索の仕組みを解説しています。「辛くないカレーが食べたい」といった自然な問いかけにも応えられる技術、ぜひご覧ください!
はじめに

「辛くないカレーが食べたい」「野菜たっぷりのカレーのレシピを教えて」といった検索をしたとき、単なるキーワードマッチではなく、意図を理解した検索結果が欲しいと思ったことはありませんか?
近年、自然言語処理の発展に伴い、テキストデータの意味的な類似性を考慮した「セマンティック検索」が注目されています。従来のキーワードマッチングによる検索と異なり、セマンティック検索は文脈や意味を理解し、より関連性の高い結果を返すことができます。
本記事では、カレーレシピのデータベースを例に、セマンティック検索の核となる「ベクトルデータベース」について、特にFaissを用いた実装方法を解説します。Google Colaboratoryで実際に動かしながら学べる内容となっていますので、ぜひ手を動かしながら理解を深めてください。
1. ベクトルデータベースとは
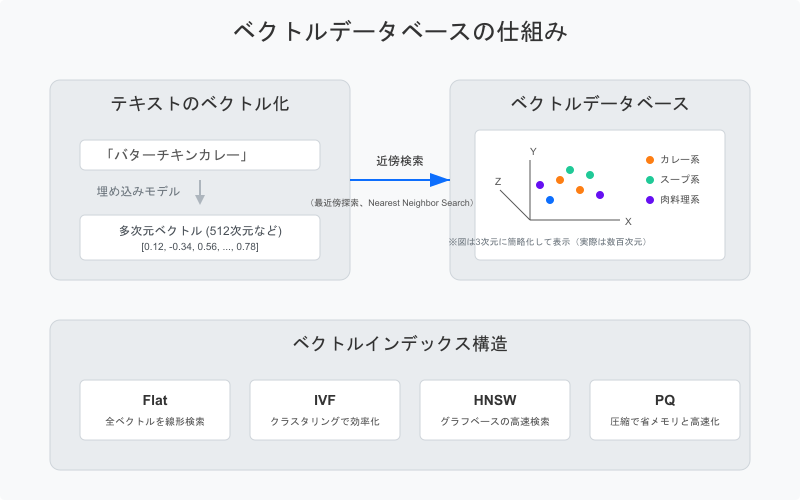
ベクトルデータベースは、データを多次元ベクトル(埋め込み)として格納し、類似度に基づいて検索を行うデータベースです。テキスト、画像、音声など様々なデータ形式に対応し、「意味的に近い」データを効率的に検索できるのが特徴です。
主なベクトルデータベース
- Faiss: Meta AI Research が開発した高性能なベクトル検索ライブラリ
- Annoy: Spotify が開発した近似最近傍検索ライブラリ
- HNSW: Hierarchical Navigable Small World グラフによる検索アルゴリズム
- Pinecone: クラウドベースのベクトルデータベースサービス
- Weaviate: オープンソースのベクトル検索エンジン
本記事では、特にFaissに焦点を当てて解説します。
2. Faissの基本的な使い方

環境準備
Google Colaboratoryで以下のコードを実行し、必要なライブラリをインストールします。
!pip install faiss-cpu numpy scikit-learn sentence-transformers
基本的な使用方法
Faissの基本的な使用フローは以下の通りです:
- データを準備し、ベクトル化する
- インデックスを作成する
- ベクトルをインデックスに追加する
- クエリを実行する
以下に簡単な例を示します:
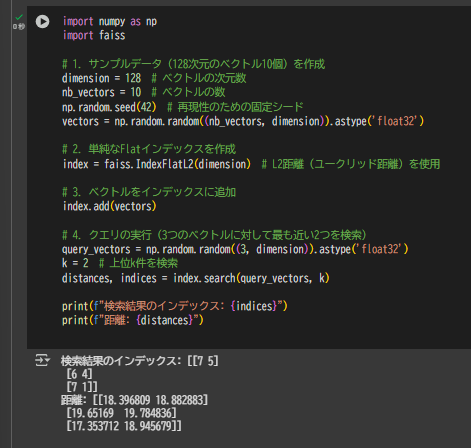
import numpy as np
import faiss
# 1. サンプルデータ(128次元のベクトル10個)を作成
dimension = 128 # ベクトルの次元数
nb_vectors = 10 # ベクトルの数
np.random.seed(42) # 再現性のための固定シード
vectors = np.random.random((nb_vectors, dimension)).astype('float32')
# 2. 単純なFlatインデックスを作成
index = faiss.IndexFlatL2(dimension) # L2距離(ユークリッド距離)を使用
# 3. ベクトルをインデックスに追加
index.add(vectors)
# 4. クエリの実行(3つのベクトルに対して最も近い2つを検索)
query_vectors = np.random.random((3, dimension)).astype('float32')
k = 2 # 上位k件を検索
distances, indices = index.search(query_vectors, k)
print(f"検索結果のインデックス: {indices}")
print(f"距離: {distances}")
カレーレシピデータを用いた実践的な例
カレーレシピのテキストデータを使った実際の例を見てみましょう:
from sentence_transformers import SentenceTransformer
import pandas as pd
# カレーレシピのデータ準備
curry_recipes = [
"バターチキンカレー:鶏肉、トマト、バター、生クリームを使った濃厚な北インドカレー",
"ほうれん草と豆腐のグリーンカレー:ココナッツミルクとタイのスパイスを使ったベジタリアンカレー",
"ビーフカレー:牛肉と玉ねぎをじっくり炒めた日本の定番カレー",
"スープカレー:野菜たっぷりのあっさりスープ仕立ての札幌風カレー",
"ドライカレー:ひき肉と彩り野菜を使った炒め物風カレー",
"キーマカレー:ひき肉とスパイスをたっぷり使った本格インドカレー",
"ポークカレー:豚肉の旨味が溶け出した濃厚なカレー",
"チキンカレー:鶏肉と玉ねぎがベースの食べやすいカレー",
"シーフードカレー:エビやイカなど魚介の旨味が詰まったカレー",
"野菜カレー:季節の野菜をたっぷり使ったヘルシーなカレー"
]
# レシピをベクトル化するモデルを読み込み
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# レシピをベクトル化
vectors = model.encode(curry_recipes)
vectors = vectors.astype('float32') # Faissは32ビット浮動小数点数を使用
# インデックスの作成と追加
dimension = vectors.shape[1] # ベクトルの次元数
index = faiss.IndexFlatL2(dimension)
index.add(vectors)
# クエリの実行
query = "辛くないベジタリアン向けのカレーが食べたい"
query_vector = model.encode([query])[0].reshape(1, -1).astype('float32')
k = 3 # 上位3件を検索
distances, indices = index.search(query_vector, k)
print("クエリ:", query)
print("検索結果:")
for i, idx in enumerate(indices[0]):
print(f"{i+1}. {curry_recipes[idx]} (距離: {distances[0][i]:.4f})")

3. インデックス構築とANN (近似最近傍探索)
Faissの強みは、大規模なデータセットに対しても高速に検索できる様々なインデックス構造を提供していることです。
主要なインデックスタイプ
- IndexFlatL2: すべてのベクトルと正確な距離を計算(正確だが遅い)
- IndexIVFFlat: データをクラスタリングし、近いクラスタのみを検索
- IndexHNSW: グラフベースのアルゴリズムで高速に近似最近傍探索
- IndexPQ: Product Quantization で圧縮した状態で検索
- IndexIVFPQ: IVF + PQ の組み合わせ
それぞれのインデックス特性を比較してみましょう:
import time
import matplotlib.pyplot as plt
# より大きなデータセットを作成(10,000ベクトル)
nb_vectors = 10000
vectors_large = np.random.random((nb_vectors, dimension)).astype('float32')
# クエリベクトル
queries = np.random.random((5, dimension)).astype('float32')
# 異なるインデックスタイプの比較
index_types = {
"Flat": faiss.IndexFlatL2(dimension),
"IVF100,Flat": faiss.IndexIVFFlat(faiss.IndexFlatL2(dimension), dimension, 100),
"HNSW": faiss.IndexHNSWFlat(dimension, 32)
}
# IVFPQ用のクラスタリング数とPQ部分のトレーニングが必要
index_types["IVF100,Flat"].train(vectors_large)
# インデックスへのデータ追加
for name, index in index_types.items():
index.add(vectors_large)
# 検索精度と速度の評価
results = {}
for name, index in index_types.items():
start_time = time.time()
D, I = index.search(queries, k=10)
end_time = time.time()
results[name] = {
"time": end_time - start_time,
"results": I
}
print(f"{name}: 検索時間 {results[name]['time']:.5f} 秒")

最適なインデックスの選択
インデックスの選択は以下の要素のバランスを考慮して行います:
- 検索速度: 大規模データでは近似手法が必要
- 検索精度: 正確な結果が必要な場合はFlatインデックス
- メモリ使用量: 圧縮手法(PQなど)でメモリ削減
- データサイズ: 小規模ならFlatやHNSW、大規模ならIVFPQ
- 更新頻度: 頻繁な更新があるならFlatやIVF系
- クエリ数: バッチ処理ならGPU対応インデックス
以下は一般的な選択基準です:
- 少量のデータ(~10万件): IndexFlatL2 または IndexHNSWFlat
- 中規模データ(~100万件): IndexIVFFlat または IndexHNSW
- 大規模データ(100万件以上): IndexIVFPQ または IndexHNSWPQ
4. スケーラビリティの確保
実用的なシステムでは、データ量の増加に対応できるスケーラビリティが重要です。
分散インデックス
Faissは分散処理をサポートしており、大規模データを複数のノードに分散させることができます:
# クラスタリングと分割の例
# この例ではシミュレーションのみ行います
# 2つのサブインデックスを作成
sub_indices = [
faiss.IndexFlatL2(dimension),
faiss.IndexFlatL2(dimension)
]
# データを半分に分割
half = nb_vectors // 2
sub_indices[0].add(vectors_large[:half])
sub_indices[1].add(vectors_large[half:])
# 2つのインデックスを1つにマージするためのIDXマッパー
index = faiss.IndexIDMap(faiss.IndexFlatL2(dimension))
# それぞれのサブインデックスからの結果を統合する例
def search_distributed(query, k=5):
results = []
for i, sub_index in enumerate(sub_indices):
D, I = sub_index.search(query, k)
# 実際のIDにマッピング(この例ではシンプルにオフセットを加算)
if i == 1:
I = I + half
for j in range(len(I[0])):
results.append((I[0][j], D[0][j]))
# 距離でソート
results.sort(key=lambda x: x[1])
return results[:k]
# 分散検索の実行
query = np.random.random((1, dimension)).astype('float32')
results = search_distributed(query)
print("分散検索結果:", results)
分散検索結果: [(np.int64(1103), np.float32(49.777683)), (np.int64(4019), np.float32(49.920807)), (np.int64(5070), np.float32(50.33294)), (np.int64(6701), np.float32(50.665127)), (np.int64(2904), np.float32(50.669502))]
データの管理と更新
ベクトルデータベースを効率的に更新する方法も考慮しましょう:
# インデックスのシリアル化(保存)
faiss.write_index(index_types["Flat"], "flat_index.bin")
# インデックスの読み込み
loaded_index = faiss.read_index("flat_index.bin")
# 新しいデータの追加
new_vectors = np.random.random((100, dimension)).astype('float32')
loaded_index.add(new_vectors)
# ベクトルの削除(IndexIDMapが必要)
ids = np.array([0, 10, 20], dtype=np.int64) # 削除するID
index_with_ids = faiss.IndexIDMap(faiss.IndexFlatL2(dimension))
index_with_ids.add_with_ids(vectors_large, np.arange(len(vectors_large), dtype=np.int64))
index_with_ids.remove_ids(ids)
5. クエリ処理のパイプライン設計
実際のアプリケーションでは、単純な検索だけでなく、前処理や後処理を含むパイプラインを設計することが重要です。
完全なカレー検索パイプラインの実装
以下は、すべての機能を統合した完全なカレー検索パイプラインの実装です:
import numpy as np
import faiss
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
class CurrySearchPipeline:
def __init__(self, model_name='paraphrase-multilingual-MiniLM-L12-v2'):
self.model = SentenceTransformer(model_name)
self.dimension = self.model.get_sentence_embedding_dimension()
self.index = faiss.IndexHNSWFlat(self.dimension, 32) # HNSW インデックス
self.recipes = []
self.metadata = [] # 材料や調理時間などのメタデータ
def add_recipes(self, recipes, metadata=None):
"""レシピをインデックスに追加"""
vectors = self.model.encode(recipes, show_progress_bar=True).astype('float32')
self.index.add(vectors)
# 元のレシピとメタデータも保存
start_idx = len(self.recipes)
self.recipes.extend(recipes)
if metadata:
if len(self.metadata) == 0:
self.metadata = [{} for _ in range(start_idx)]
self.metadata.extend(metadata)
else:
self.metadata.extend([{} for _ in range(len(recipes))])
return range(start_idx, len(self.recipes))
def search(self, query, k=5, threshold=None):
"""クエリで検索を実行"""
# クエリのベクトル化
query_vector = self.model.encode([query])[0].reshape(1, -1).astype('float32')
# 検索実行
distances, indices = self.index.search(query_vector, k)
# 結果を整形
results = []
for i, (idx, dist) in enumerate(zip(indices[0], distances[0])):
# しきい値フィルタリング(オプション)
if threshold is not None and dist > threshold:
continue
results.append({
'id': int(idx),
'recipe': self.recipes[idx],
'metadata': self.metadata[idx] if idx < len(self.metadata) else {},
'score': float(1.0 / (1.0 + dist)), # スコアに変換(1に近いほど類似)
'rank': i + 1
})
return results
def hybrid_search(self, query, k=5, keyword_weight=0.3):
"""セマンティック検索と材料キーワード検索を組み合わせる"""
# セマンティック検索の結果
semantic_results = self.search(query, k=k*2) # 少し多めに取得
# キーワード検索(単純なTF-IDFスコアリング)
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(self.recipes)
query_vec = vectorizer.transform([query])
keyword_scores = cosine_similarity(query_vec, tfidf_matrix)[0]
# スコアを組み合わせる
hybrid_results = []
for result in semantic_results:
idx = result['id']
semantic_score = result['score']
keyword_score = keyword_scores[idx]
# スコアの加重平均
combined_score = (1 - keyword_weight) * semantic_score + keyword_weight * keyword_score
# 特定の材料が含まれているかのボーナススコア
ingredients_bonus = 0
if "材料" in query or "具材" in query:
# クエリから材料名を抽出する簡易的な処理
query_words = query.split()
recipe_ingredients = self.metadata[idx].get('ingredients', [])
for word in query_words:
if word in recipe_ingredients:
ingredients_bonus += 0.1 # 材料が一致するごとにボーナス
# 最終スコア計算
final_score = combined_score + ingredients_bonus
hybrid_results.append({
'id': idx,
'recipe': self.recipes[idx],
'metadata': self.metadata[idx] if idx < len(self.metadata) else {},
'score': final_score,
'semantic_score': semantic_score,
'keyword_score': keyword_score
})
# 組み合わせスコアでソート
hybrid_results.sort(key=lambda x: x['score'], reverse=True)
return hybrid_results[:k]
def filtered_curry_search(self, query, filters=None, k=5):
"""カレー特化のフィルタを適用した検索"""
# 通常の検索を実行(多めに取得)
base_results = self.search(query, k=k*5)
if filters is None:
return base_results[:k]
# フィルタリング適用
filtered_results = []
for result in base_results:
# メタデータに基づいたフィルタリング
passes_filter = True
idx = result['id']
metadata = self.metadata[idx] if idx < len(self.metadata) else {}
# 辛さフィルタ
if 'spiciness' in filters:
spiciness_levels = {
"甘口": 1,
"中辛": 2,
"辛口": 3,
"激辛": 4
}
recipe_level = spiciness_levels.get(metadata.get('spiciness', '不明'), 0)
filter_level = spiciness_levels.get(filters['spiciness'], 0)
if filter_level == 0 or recipe_level == 0:
# 不明な場合はパス
pass
elif filters.get('spiciness_operator') == 'less_than':
if recipe_level >= filter_level:
passes_filter = False
elif filters.get('spiciness_operator') == 'greater_than':
if recipe_level <= filter_level:
passes_filter = False
else: # exact match
if recipe_level != filter_level:
passes_filter = False
# ベジタリアンフィルタ
if 'vegetarian' in filters and filters['vegetarian'] is not None:
if metadata.get('vegetarian') != filters['vegetarian']:
passes_filter = False
# 調理時間フィルタ
if 'max_cooking_time' in filters:
cooking_time = metadata.get('cooking_time', 0)
if cooking_time > filters['max_cooking_time']:
passes_filter = False
# 材料フィルタ
if 'required_ingredients' in filters:
recipe_ingredients = set(metadata.get('ingredients', []))
required_ingredients = set(filters['required_ingredients'])
if not required_ingredients.issubset(recipe_ingredients):
passes_filter = False
# 除外材料フィルタ
if 'excluded_ingredients' in filters:
recipe_ingredients = set(metadata.get('ingredients', []))
excluded_ingredients = set(filters['excluded_ingredients'])
if recipe_ingredients.intersection(excluded_ingredients):
passes_filter = False
if passes_filter:
filtered_results.append(result)
if len(filtered_results) >= k:
break
return filtered_results
def save(self, filepath):
"""インデックスと関連データを保存"""
faiss.write_index(self.index, f"{filepath}.index")
np.save(f"{filepath}.recipes", np.array(self.recipes, dtype=object))
np.save(f"{filepath}.metadata", np.array(self.metadata, dtype=object))
@classmethod
def load(cls, filepath, model_name='paraphrase-multilingual-MiniLM-L12-v2'):
"""保存されたインデックスと関連データを読み込み"""
pipeline = cls(model_name)
pipeline.index = faiss.read_index(f"{filepath}.index")
pipeline.recipes = np.load(f"{filepath}.recipes.npy", allow_pickle=True).tolist()
pipeline.metadata = np.load(f"{filepath}.metadata.npy", allow_pickle=True).tolist()
return pipeline
使用例として、以下のデモ関数を実行できます:
def demo_curry_search():
# カレーレシピのデータ準備
curry_recipes = [
"バターチキンカレー:鶏肉、トマト、バター、生クリームを使った濃厚な北インドカレー",
"ほうれん草と豆腐のグリーンカレー:ココナッツミルクとタイのスパイスを使ったベジタリアンカレー",
"ビーフカレー:牛肉と玉ねぎをじっくり炒めた日本の定番カレー",
"スープカレー:野菜たっぷりのあっさりスープ仕立ての札幌風カレー",
"ドライカレー:ひき肉と彩り野菜を使った炒め物風カレー",
"キーマカレー:ひき肉とスパイスをたっぷり使った本格インドカレー",
"ポークカレー:豚肉の旨味が溶け出した濃厚なカレー",
"チキンカレー:鶏肉と玉ねぎがベースの食べやすいカレー",
"シーフードカレー:エビやイカなど魚介の旨味が詰まったカレー",
"野菜カレー:季節の野菜をたっぷり使ったヘルシーなカレー"
]
metadata = [
{"spiciness": "中辛", "cooking_time": 40, "vegetarian": False, "ingredients": ["鶏肉", "トマト", "バター", "生クリーム"]},
{"spiciness": "中辛", "cooking_time": 30, "vegetarian": True, "ingredients": ["ほうれん草", "豆腐", "ココナッツミルク"]},
{"spiciness": "甘口", "cooking_time": 60, "vegetarian": False, "ingredients": ["牛肉", "玉ねぎ", "にんじん", "じゃがいも"]},
{"spiciness": "中辛", "cooking_time": 45, "vegetarian": False, "ingredients": ["鶏肉", "にんじん", "じゃがいも", "玉ねぎ"]},
{"spiciness": "甘口", "cooking_time": 20, "vegetarian": False, "ingredients": ["ひき肉", "玉ねぎ", "ピーマン", "にんじん"]},
{"spiciness": "辛口", "cooking_time": 50, "vegetarian": False, "ingredients": ["ひき肉", "トマト", "にんにく", "スパイス"]},
{"spiciness": "中辛", "cooking_time": 55, "vegetarian": False, "ingredients": ["豚肉", "玉ねぎ", "にんじん", "じゃがいも"]},
{"spiciness": "甘口", "cooking_time": 40, "vegetarian": False, "ingredients": ["鶏肉", "玉ねぎ", "にんじん", "じゃがいも"]},
{"spiciness": "中辛", "cooking_time": 35, "vegetarian": False, "ingredients": ["エビ", "イカ", "玉ねぎ", "にんじん"]},
{"spiciness": "甘口", "cooking_time": 30, "vegetarian": True, "ingredients": ["かぼちゃ", "なす", "玉ねぎ", "ズッキーニ"]}
]
# パイプラインを作成し、レシピを追加
pipeline = CurrySearchPipeline()
pipeline.add_recipes(curry_recipes, metadata)
print("=== 基本検索 ===")
results = pipeline.search("辛くないベジタリアン向けのカレーが食べたい", k=2)
for result in results:
print(f"rank: {result['rank']}, score: {result['score']:.4f}")
print(f"recipe: {result['recipe']}")
print(f"spiciness: {result['metadata'].get('spiciness', '不明')}")
print()
print("=== ハイブリッド検索 ===")
results = pipeline.hybrid_search("にんじんとじゃがいもを使った子供向けカレー", k=2)
for result in results:
print(f"score: {result['score']:.4f}")
print(f"recipe: {result['recipe']}")
print(f"ingredients: {', '.join(result['metadata'].get('ingredients', []))}")
print()
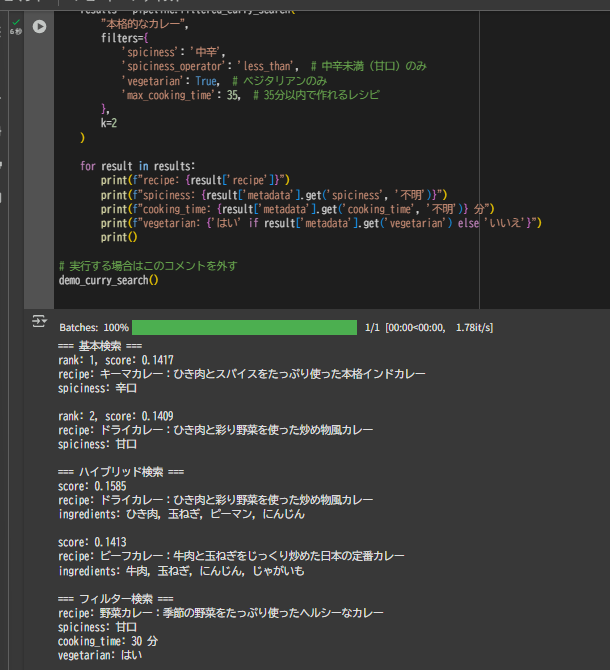
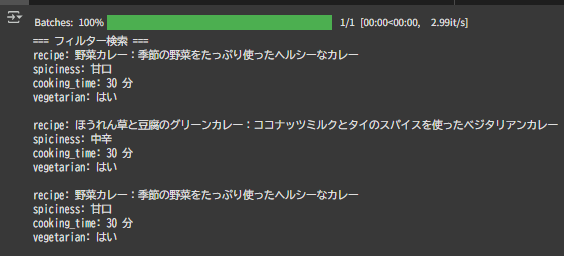
print("=== フィルター検索 ===")
results = pipeline.filtered_curry_search(
"本格的なカレー",
filters={
'spiciness': '中辛',
'spiciness_operator': 'less_than', # 中辛未満(甘口)のみ
'vegetarian': True, # ベジタリアンのみ
'max_cooking_time': 35, # 35分以内で作れるレシピ
},
k=2
)
for result in results:
print(f"recipe: {result['recipe']}")
print(f"spiciness: {result['metadata'].get('spiciness', '不明')}")
print(f"cooking_time: {result['metadata'].get('cooking_time', '不明')} 分")
print(f"vegetarian: {'はい' if result['metadata'].get('vegetarian') else 'いいえ'}")
print()
# 実行する場合はこのコメントを外す
demo_curry_search()
filtered_curry_search が実行できない場合のトラブルシューティング
filtered_curry_search メソッドが実行できない場合は、以下の点を確認してください:
-
完全なコードが正しくコピーされているか:記事の最初の部分では
CurrySearchPipと途中で切れていますが、正しくはCurrySearchPipelineです。 -
デモ関数のコメントアウトを外す:最後の行
# demo_curry_search()のコメントを外して実行してください。 -
簡易的なテスト関数を作成:問題が解決しない場合は、以下のような簡易テスト関数を試してみてください。
def test_filtered_curry_search():
# カレーレシピのデータ準備(省略)
# パイプラインを作成し、レシピを追加
pipeline = CurrySearchPipeline()
pipeline.add_recipes(curry_recipes, metadata)
print("=== フィルター検索 ===")
# より簡単なフィルター条件から始める
results = pipeline.filtered_curry_search(
"カレー",
filters={
'vegetarian': True, # ベジタリアンのみ
},
k=3
)
for result in results:
print(f"recipe: {result['recipe']}")
print(f"spiciness: {result['metadata'].get('spiciness', '不明')}")
print(f"cooking_time: {result['metadata'].get('cooking_time', '不明')} 分")
print(f"vegetarian: {'はい' if result['metadata'].get('vegetarian') else 'いいえ'}")
print()
# 実行する場合はこのコメントを外す
test_filtered_curry_search()
まとめ - カレーとベクトルデータベースの意外な共通点
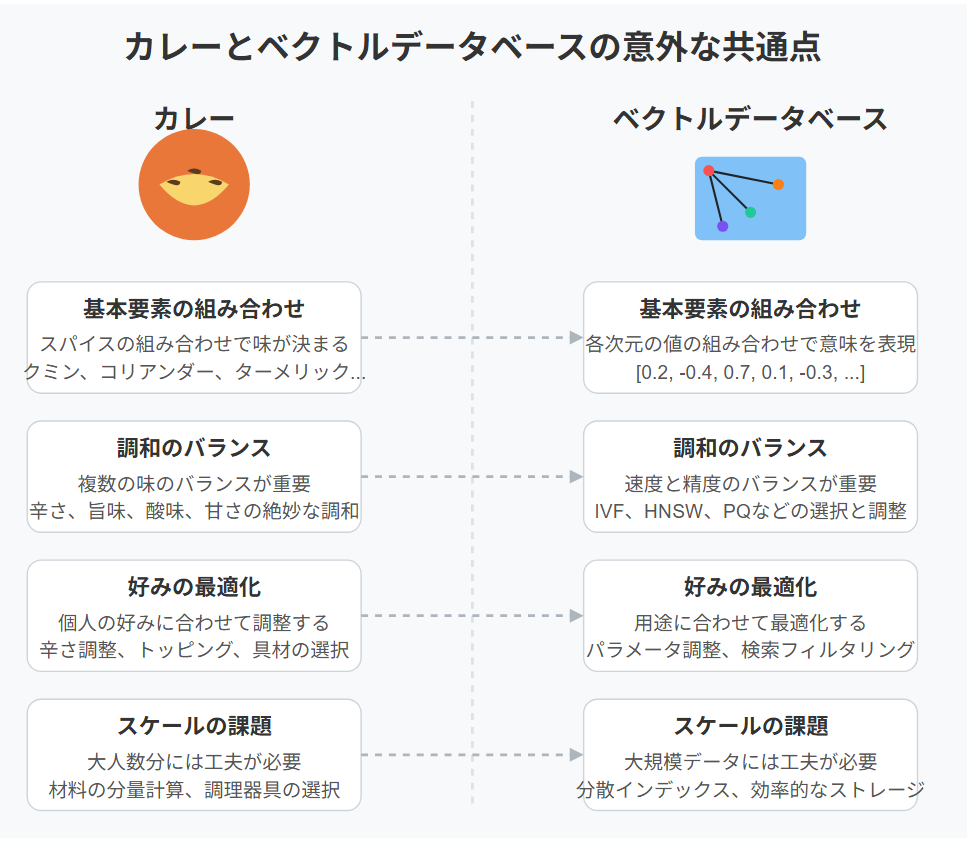
本記事では、カレーレシピを題材に、セマンティック検索の基盤となるベクトルデータベース、特にFaissの基本的な使い方から実用的なパイプライン設計までを解説しました。
実は、カレーとベクトルデータベースには意外な共通点があります:
- 基本要素の組み合わせ: カレーはスパイスの組み合わせで味が決まるように、ベクトルデータベースはベクトルの各次元の値の組み合わせで意味を表現します。
- 調和のバランス: 良いカレーは複数の味のバランスが重要なように、良いベクトル検索は速度と精度のバランスが重要です。
- 好みの最適化: カレーは個人の好みに合わせて調整するように、ベクトル検索も用途に合わせて最適化します。
- スケールの課題: 大人数分のカレー作りには工夫が必要なように、大規模データのベクトル検索にもスケーラビリティの工夫が必要です。
セマンティック検索のポイントをまとめると:
- ベクトルデータベースはセマンティック検索の核となる技術で、「辛くないカレーが食べたい」といった意図を理解した検索ができる
- Faissは高性能なベクトル検索ライブラリで、様々なインデックスタイプを提供
- インデックス選択はデータ量や要求精度、速度のバランスに応じて適切に行う
- スケーラビリティは分散インデックスやデータ管理戦略で確保
- 検索パイプラインは前処理、検索、後処理を含め、材料や辛さなどの条件を加味したフィルタリングで拡張可能
これらの知識を活用して、自分のプロジェクトに最適なセマンティック検索システムを構築してみてください。料理レシピのような構造化テキストデータは、セマンティック検索の効果が特に発揮される分野の一つです。