はじめに
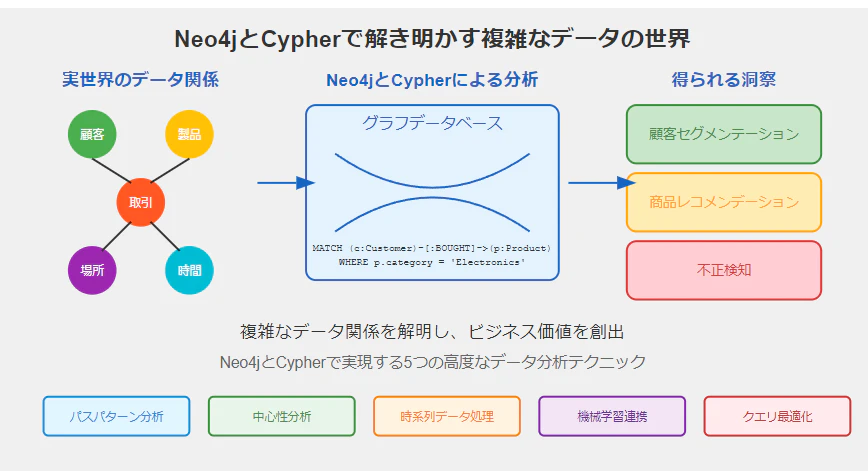
こんにちは、データ分析エンジニアの皆さん!今回は、グラフデータベースの代表格であるNeo4jと、そのクエリ言語Cypherを使って、データ分析の世界をさらに深く掘り下げていきましょう。この記事では、実務で即活用できる5つの高度なテクニックをご紹介します。
目次
- パスパターン分析による複雑な関係性の解明
- グラフアルゴリズムを活用した中心性分析
- 時系列データの効率的な処理と分析
- 機械学習との連携によるグラフベース予測モデルの構築
- 大規模グラフデータの効率的なクエリ最適化テクニック
1. パスパターン分析による複雑な関係性の解明
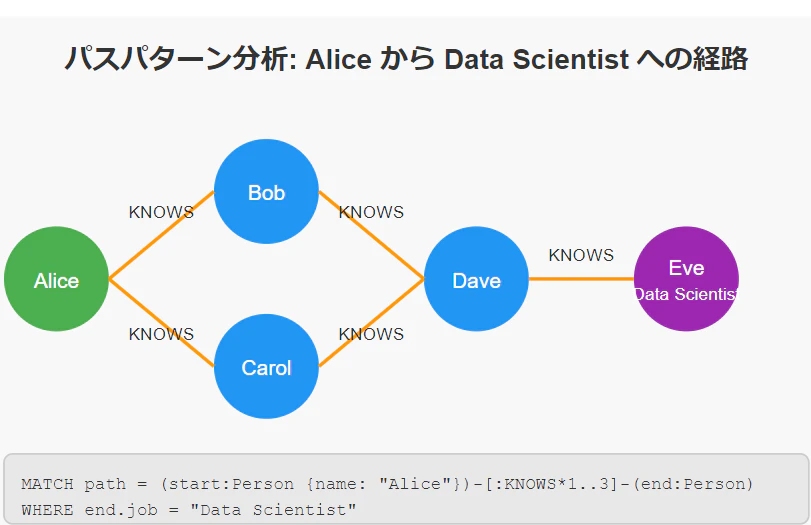
Neo4jの強みは、複雑な関係性を持つデータを直感的に扱える点です。Cypherのパスパターン機能を使うことで、従来のSQLでは困難だった多段階の関係性分析が可能になります。
MATCH path = (start:Person {name: "Alice"})-[:KNOWS*1..3]-(end:Person)
WHERE end.job = "Data Scientist"
RETURN path
このクエリは、"Alice"から1〜3ホップ以内にいるデータサイエンティストを見つけ出し、その関係性のパスを返します。これにより、人脈ネットワーク内の重要な接点を可視化できます。
パスパターン機能とは
パスパターン機能は、Neo4jのCypherクエリ言語において、グラフデータベース内の複雑な関係性を効率的に探索するための強力なツールです。
概要
パスパターンとは、ノード間の関係性(エッジ)の連鎖を指定する方法です。この機能を使用することで、直接的な関係だけでなく、間接的で複雑な関係性を柔軟に検索することができます。パスパターンの特徴として、可変長パス、方向性の指定、関係タイプの指定など、多様な条件を組み合わせることが可能です。
グラフデータベースの強みを最大限に活かすこの機能により、従来のリレーショナルデータベースでは困難だった複雑なデータ間の関係性の探索が可能になります。
基本的な構文
パスパターンの基本的な構文は以下の通りです:
(startNode)-[relationship*minHops..maxHops]->(endNode)
-
startNode: 探索を開始するノード -
relationship: 辿る関係のタイプ -
minHops: 最小のホップ数(省略可能) -
maxHops: 最大のホップ数(省略可能) -
endNode: 探索の終点となるノード
この構文は非常に柔軟で、様々なバリエーションが可能です。例えば、方向を指定しない -[]- や、特定の関係タイプのみを指定する -[:RELATIONSHIP_TYPE]-> なども使用できます。
使用例
-
友人の友人を見つける
MATCH (person:Person {name: "Alice"})-[:FRIEND*2]-(friendOfFriend) RETURN friendOfFriendこの例では、Aliceの友人の友人を2ホップで検索しています。
-
1〜3ホップ以内の関連製品を検索
MATCH (product:Product {id: 123})-[:RELATED*1..3]-(relatedProduct) RETURN relatedProductここでは、ある製品から1〜3ホップ以内にある関連製品を柔軟に検索しています。
-
最短パスの検索
MATCH p = shortestPath((start:Location {name: "A"})-[:ROAD*]-(end:Location {name: "B"})) RETURN pこの例では、2地点間の最短経路を検索しています。
shortestPath関数と組み合わせることで、効率的なルート探索が可能になります。
これらの例は、パスパターンの基本的な使用方法を示していますが、実際の応用はこれらにとどまりません。複雑なビジネスロジックや高度なデータ分析にも適用可能です。
利点
-
柔軟性:
関係の深さや種類を動的に指定できるため、様々なシナリオに対応できます。例えば、「友人の友人の友人...」といった任意の深さの関係性を簡単に表現できます。 -
効率性:
複雑な関係性を単一のクエリで探索できるため、複数のクエリを組み合わせる必要がなく、パフォーマンスが向上します。また、Neo4jの強力なグラフエンジンにより、大規模データでも高速な探索が可能です。 -
直感的:
グラフの構造を反映した自然な記述が可能なため、クエリの意図が理解しやすく、メンテナンス性も向上します。視覚的にグラフを思い浮かべながらクエリを書くことができるのも大きな利点です。 -
スケーラビリティ:
データ量が増加しても、パスパターンを使用したクエリの基本的な構造は変わらないため、システムの拡張性が高まります。
応用例
-
ソーシャルネットワーク分析:
ユーザー間の関係性を分析し、影響力の強いユーザーの特定や、コミュニティの検出などに活用できます。 -
推薦システムの構築:
ユーザーの行動履歴や商品間の関連性を基に、より精度の高い商品推薦を行うことができます。 -
サプライチェーンの最適化:
複雑な製造・流通過程を可視化し、ボトルネックの発見や最適なルートの選定に役立ちます。 -
不正検出システムの開発:
金融取引や通信ネットワークにおける不自然なパターンを検出し、潜在的な不正を早期に発見することができます。 -
知識グラフの探索:
大規模な知識ベースにおいて、概念間の複雑な関係性を追跡し、新たな知見の発見に貢献します。
パスパターン機能は、これらの応用例に限らず、グラフデータの特性を活かした幅広い分野で活用することができます。データ間の関係性が重要な役割を果たすあらゆる領域で、パスパターンは強力な分析ツールとなります。
2. グラフアルゴリズムを活用した中心性分析
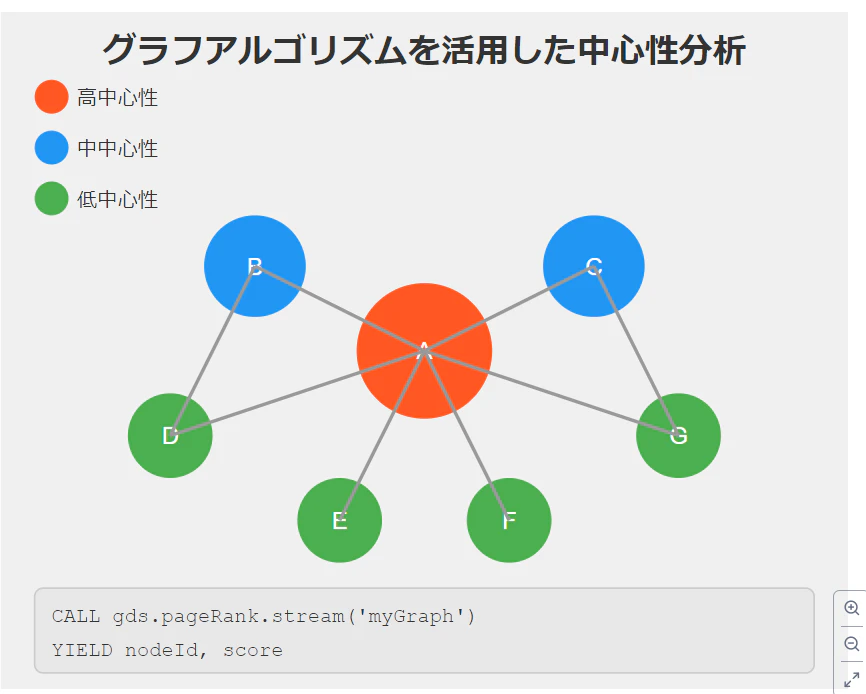
中心性分析は、グラフ理論において非常に重要な概念であり、ネットワーク内の各ノードの重要性や影響力を数値化する手法です。Neo4jのGraph Data Science(GDS)ライブラリを使用することで、複雑なグラフアルゴリズムを簡単に実行し、高度な中心性分析を行うことができます。
主要な中心性指標
-
次数中心性(Degree Centrality)
- 定義:ノードに直接接続されている他のノードの数
- 特徴:ローカルな影響力を測定するのに適しています
- Cypherクエリ例:
CALL gds.degree.stream('myGraph') YIELD nodeId, score RETURN gds.util.asNode(nodeId).name AS name, score ORDER BY score DESC LIMIT 10
-
固有ベクトル中心性(Eigenvector Centrality)
- 定義:ノードの重要性を、接続先のノードの重要性に基づいて再帰的に計算
- 特徴:グローバルな影響力を考慮に入れた指標です
- Cypherクエリ例:
CALL gds.eigenvector.stream('myGraph') YIELD nodeId, score RETURN gds.util.asNode(nodeId).name AS name, score ORDER BY score DESC LIMIT 10
-
ページランク(PageRank)
- 定義:ウェブページの重要性を計算するためにGoogleが開発したアルゴリズム
- 特徴:固有ベクトル中心性の一種で、大規模ネットワークに適しています
- Cypherクエリ例:
CALL gds.pageRank.stream('myGraph') YIELD nodeId, score RETURN gds.util.asNode(nodeId).name AS name, score ORDER BY score DESC LIMIT 10
-
媒介中心性(Betweenness Centrality)
- 定義:あるノードが他の2つのノード間の最短経路上にある頻度
- 特徴:情報の流れや影響力の仲介者を特定するのに役立ちます
- Cypherクエリ例:
CALL gds.betweenness.stream('myGraph') YIELD nodeId, score RETURN gds.util.asNode(nodeId).name AS name, score ORDER BY score DESC LIMIT 10
中心性分析の応用例
-
ソーシャルネットワーク分析
- インフルエンサーの特定
- コミュニティのキーパーソン発見
-
交通ネットワーク最適化
- 重要な交差点や道路の特定
- 渋滞ポイントの予測
-
生態系ネットワーク
- 生態系内の重要種の特定
- 絶滅リスクの高い種の予測
-
組織ネットワーク分析
- 非公式なリーダーの特定
- 情報流通の効率化
-
疾病伝播モデル
- 感染拡大のハブとなる個人や地域の特定
- 効果的な予防戦略の立案
注意点と考慮事項
- 適切な中心性指標の選択は、分析の目的とネットワークの特性に依存します。
- 大規模なグラフでは計算コストが高くなる場合があるため、パフォーマンスに注意が必要です。
- 中心性スコアは相対的な指標であり、絶対的な数値として解釈すべきではありません。
- 時間の経過とともにネットワーク構造が変化する動的グラフでは、定期的な再計算が必要です。
中心性分析を効果的に活用することで、複雑なネットワーク構造から重要な洞察を得ることができ、データ駆動型の意思決定を支援することができます。
3. 時系列データの効率的な処理と分析
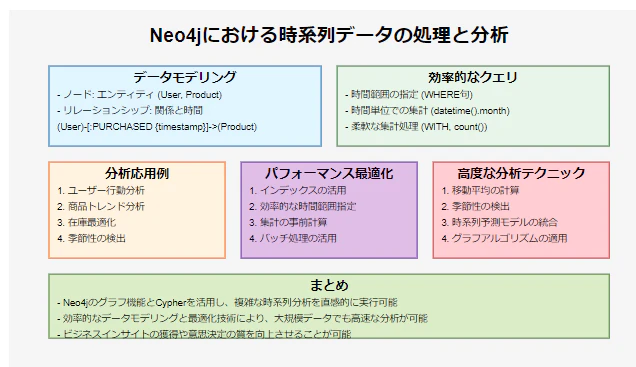
Neo4jは時系列データの処理と分析に優れた能力を発揮します。グラフ構造を活用することで、時間軸に沿った複雑な関係性の変化を追跡し、分析することが可能です。
時系列データのモデリング
Neo4jでは、時系列データを以下のように表現できます:
- ノード:エンティティ(例:ユーザー、商品)
- リレーションシップ:エンティティ間の関係と、その関係が発生した時間
例えば、ユーザーの商品購入履歴を次のように表現できます:
(User)-[:PURCHASED {timestamp: datetime('2023-05-01T10:30:00')}]->(Product)
効率的なクエリ例
以下のクエリは、2023年の各月におけるユーザーごとの商品購入回数を集計します:
MATCH (u:User)-[p:PURCHASED]->(prod:Product)
WHERE p.timestamp >= datetime('2023-01-01T00:00:00')
AND p.timestamp < datetime('2024-01-01T00:00:00')
WITH u, prod, datetime(p.timestamp).month AS month, count(*) AS purchases
RETURN u.name, prod.name, month, purchases
ORDER BY u.name, month
このクエリの特徴:
- 時間範囲の指定:
WHERE句で2023年のデータのみを抽出 - 時間単位での集計:
datetime(p.timestamp).monthで月単位に集計 - 柔軟な集計:ユーザーと商品の組み合わせごとに購入回数を計算
分析の応用例
-
ユーザー行動分析
- 時間帯別の購買パターン
- リピート率の推移
- 購買頻度の変化
-
商品トレンド分析
- 季節ごとの人気商品の変化
- 新商品の売上推移
- カテゴリー別の需要変動
-
在庫最適化
- 時期による需要変動の予測
- 適正在庫量の算出
- 季節商品の入荷タイミング決定
パフォーマンス最適化のヒント
-
インデックスの活用
CREATE INDEX ON :PURCHASED(timestamp)時間ベースのクエリを高速化します。
-
時間範囲の効率的な指定
WHERE句での範囲指定を適切に行い、スキャンするデータ量を減らします。 -
集計の事前計算
頻繁に使用される集計結果を定期的に計算し、別ノードに保存します。例:MATCH (u:User)-[p:PURCHASED]->(prod:Product) WHERE p.timestamp >= datetime('2023-01-01T00:00:00') AND p.timestamp < datetime('2024-01-01T00:00:00') WITH u, prod, datetime(p.timestamp).month AS month, count(*) AS purchases MERGE (s:MonthlySales {user: u.name, product: prod.name, month: month}) SET s.purchases = purchases -
バッチ処理の活用
大量のデータを処理する際は、apoc.periodic.iterateを使用してバッチ処理を行います。
高度な分析テクニック
-
移動平均の計算
直近7日間の移動平均売上を計算する例:MATCH (p:Product)-[:HAS_SALE]->(s:Sale) WHERE s.date >= date() - duration('P7D') WITH p, s.date AS date, s.amount AS amount ORDER BY s.date WITH p, collect({date: date, amount: amount}) AS sales UNWIND range(0, size(sales) - 7) AS idx WITH p, idx, [i IN range(idx, idx + 6) | sales[i].amount] AS window RETURN p.name, sales[idx + 3].date AS mid_date, round(avg(window), 2) AS moving_avg ORDER BY mid_date -
季節性の検出
四半期ごとの売上パターンを分析する例:MATCH (p:Product)-[:HAS_SALE]->(s:Sale) WHERE s.date.year = 2023 WITH p, s.date.quarter AS quarter, sum(s.amount) AS quarterly_sales RETURN p.name, collect({quarter: quarter, sales: quarterly_sales}) AS quarterly_pattern, stddev(collect(quarterly_sales)) AS sales_volatility ORDER BY sales_volatility DESC
時系列データの効率的な処理と分析により、ビジネスインサイトの獲得や意思決定の質を向上させることができます。Neo4jの強力なグラフ機能と柔軟なクエリ言語Cypherを組み合わせることで、複雑な時系列分析も直感的に実行できます。これらのテクニックを活用し、データから最大の価値を引き出してください。
4. 機械学習との連携によるグラフベース予測モデルの構築
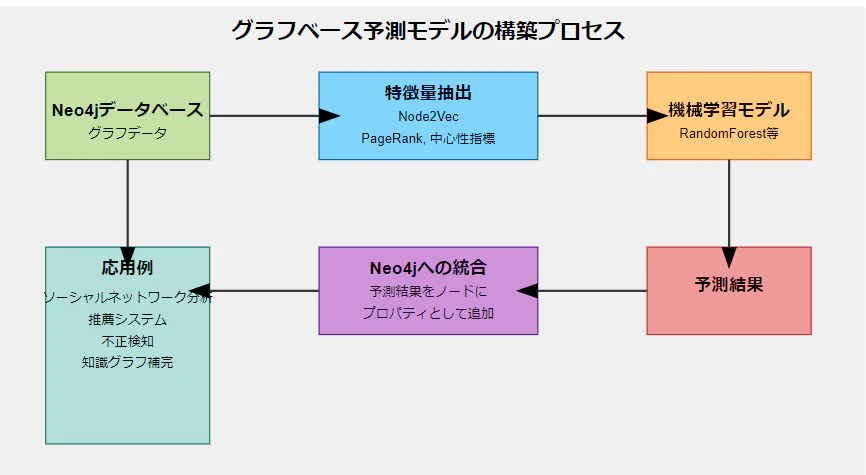
Neo4jのGraph Data Science (GDS) ライブラリは、機械学習アルゴリズムとの統合を容易にします。これにより、グラフデータの豊富な構造情報を活用した高度な予測モデルを構築することが可能になります。
グラフ特徴量の抽出
予測モデルの構築に先立ち、グラフデータから有用な特徴を抽出します。例えば、Node2Vecアルゴリズムを使用してノードの埋め込み表現を生成できます:
CALL gds.beta.node2vec.stream('myGraph', {
walkLength: 80,
walks: 10,
dimensions: 128
})
YIELD nodeId, embedding
MATCH (n) WHERE id(n) = nodeId
RETURN n.label AS label, embedding
このクエリの説明:
-
gds.beta.node2vec.stream: Node2Vecアルゴリズムを実行 -
walkLength: 80: 各ランダムウォークの長さ -
walks: 10: 各ノードから開始するウォークの数 -
dimensions: 128: 生成される埋め込みベクトルの次元数
結果として、各ノードが128次元のベクトルで表現されます。これにより、グラフの構造情報を数値化し、機械学習モデルに入力可能な形式に変換できます。
機械学習モデルの構築
抽出した特徴量を用いて、以下のような手順で予測モデルを構築します:
- Neo4jから抽出したデータを pandas データフレームに変換
- scikit-learn などの機械学習ライブラリを使用してモデルを学習
- 学習したモデルを評価し、必要に応じてハイパーパラメータを調整
Python コードの例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Neo4jから抽出したデータをデータフレームに変換
df = pd.DataFrame(neo4j_results)
# 特徴量とターゲットを分離
X = df.drop('label', axis=1)
y = df['label']
# データを学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# ランダムフォレストモデルの学習
model = RandomForestClassifier()
model.fit(X_train, y_train)
# モデルの評価
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
予測結果のNeo4jへの統合
学習したモデルで予測を行った後、その結果をNeo4jに戻して保存することで、グラフデータと予測結果を統合できます:
MATCH (n:Node)
WHERE n.id IN $node_ids
SET n.predicted_label = $predicted_labels[toString(n.id)]
このアプローチにより、グラフの構造情報を活用した高精度の予測モデルを構築できます。
応用例
-
ソーシャルネットワーク分析
- インフルエンサーの特定
- コミュニティ検出
- ユーザーの行動予測
-
推薦システム
- 商品レコメンデーション
- コンテンツパーソナライゼーション
- 友人推薦
-
不正検知
- 金融取引の異常検出
- ネットワーク侵入の予測
- 偽アカウントの特定
-
知識グラフ補完
- エンティティ関係の予測
- 欠損データの補完
- 新規知識の発見
まとめ
グラフデータベースと機械学習の連携は、従来の表形式データでは捉えきれない複雑な関係性を考慮した予測を可能にします。この手法は、データ間の関連性が重要な役割を果たす多くの分野で革新的な解決策を提供し、データ分析の新たな地平を開くものです。
ただし、効果的なモデル構築には、グラフ理論、機械学習、そして対象ドメインに関する深い理解が必要です。継続的な学習と実験を通じて、より精度の高いモデルの開発を目指すことが重要です。
このクエリは、Node2Vecアルゴリズムを使用してノードの埋め込み表現を生成します。この結果を外部の機械学習ライブラリ(例:scikit-learn)に渡すことで、高精度の予測モデルを構築できます。
5. 大規模グラフデータの効率的なクエリ最適化テクニック
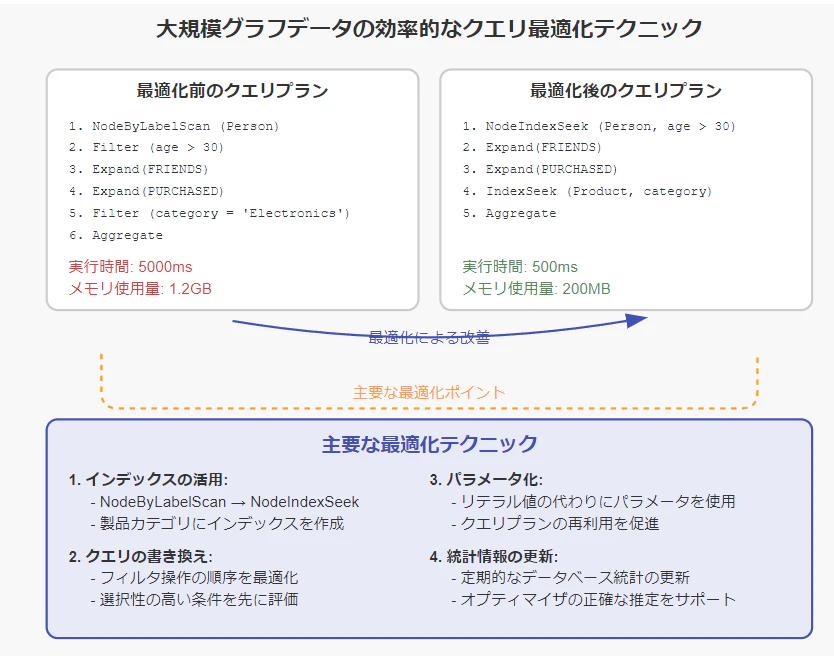
大規模グラフデータベースにおいて、クエリのパフォーマンスは極めて重要です。効率的なクエリ最適化技術を適用することで、応答時間を大幅に短縮し、リソース使用量を削減できます。以下に、主要な最適化テクニックとその実践的なアプローチを説明します。
5.1 インデックスの戦略的な使用
インデックスは検索性能を向上させる強力なツールですが、適切に使用する必要があります。
-
ノードラベルインデックス: 頻繁に検索されるノードラベルにインデックスを作成します。
CREATE INDEX ON :Person(age) -
関係性インデックス: 特定のタイプの関係性に対してインデックスを作成します。
CREATE INDEX ON :PURCHASED(date) -
複合インデックス: 複数のプロパティを組み合わせたインデックスを作成します。
CREATE INDEX ON :Product(category, price)
注意: インデックスの過剰な作成は書き込みパフォーマンスに影響を与える可能性があるため、慎重に選択する必要があります。
5.2 クエリの最適な構造化
クエリの構造を最適化することで、Neo4jのクエリプランナーがより効率的な実行計画を立てられるようになります。
-
最も制限的なパターンを先に配置: より多くのノードをフィルタリングできるパターンを先に記述します。
MATCH (p:Person)-[:LIVES_IN]->(c:City {name: 'Tokyo'}) WHERE p.age > 30 RETURN p -
不要なパターンマッチングの回避:
OPTIONAL MATCHやUNIONの使用を最小限に抑えます。 -
パラメータの使用: リテラル値の代わりにパラメータを使用し、クエリプランの再利用を促進します。
MATCH (p:Person) WHERE p.age > $minAge RETURN p
5.3 アグリゲーションと集計の最適化
大規模データセットでのアグリゲーションは特に注意が必要です。
-
事前集計の利用: 頻繁に実行される集計クエリの結果を事前に計算し、保存します。
-
APOC関数の活用: APOC(Awesome Procedures On Cypher)ライブラリを使用して、効率的な集計処理を実現します。
CALL apoc.periodic.iterate( "MATCH (p:Person) RETURN p", "SET p.ageGroup = CASE WHEN p.age < 30 THEN 'Young' ELSE 'Adult' END", {batchSize:10000, parallel:true} )
5.4 メモリ管理と並列処理
大規模グラフでは、メモリ管理と並列処理が重要になります。
-
バッチ処理: 大量のデータを扱う場合、
USING PERIODIC COMMITを使用してバッチ処理を行います。 -
並列処理の活用: Neo4jの並列処理機能を利用して、大規模なグラフ処理を効率化します。
CALL apoc.cypher.runMany(" CALL apoc.periodic.iterate( 'MATCH (p:Person) RETURN p', 'SET p.processed = true', {batchSize: 10000, parallel: true} )" )
5.5 統計情報の管理
Neo4jのクエリプランナーは統計情報を基に最適な実行計画を立てます。
-
定期的な統計更新: 大規模なデータ変更後は統計情報を更新します。
CALL db.stats.retrieve('RELATIONSHIPS') CALL db.stats.retrieve('NODES') -
サンプリングの活用: 完全な統計更新が困難な場合、サンプリングを使用します。
5.6 モニタリングとプロファイリング
継続的なパフォーマンス改善には、モニタリングとプロファイリングが不可欠です。
-
PROFILE の使用: クエリの実行計画と実際のコストを分析します。
PROFILE MATCH (p:Person)-[:FRIEND]->(f:Person) WHERE p.age > 30 RETURN p.name, count(f) as friendCount -
Neo4j Browser の活用: 視覚的なクエリプラン分析を行います。
-
ログ分析: Neo4jのクエリログを定期的に分析し、パフォーマンスの問題を特定します。
まとめ
Neo4jとCypherを活用することで、複雑なデータ分析タスクを効率的に実行できることがおわかりいただけたでしょうか。これらのテクニックを組み合わせることで、従来のリレーショナルデータベースでは困難だった深い洞察を得ることができます。
グラフデータベースの世界はまだまだ発展途上です。皆さんも是非、これらのテクニックを実践し、新たなデータ分析の可能性を探ってみてください!
参考情報
本記事の作成にあたり、以下の情報源を参考にしました。これらのリソースは、Neo4jとCypherを用いた高度なデータ分析についてさらに深く学びたい方にお勧めです。
公式ドキュメントおよびリソース
-
Neo4j公式ウェブサイト
- Neo4jの製品情報、ドキュメント、チュートリアルなどの包括的な情報を提供しています。
-
Neo4j Cypher Manual
- Cypherクエリ言語の詳細な文法や使用方法を解説しています。
-
Neo4j Graph Data Science Library
- グラフアルゴリズムやデータ分析手法の実装について詳しく説明しています。
コミュニティリソース
-
Neo4j Community Forum
- 開発者やデータサイエンティストが質問を投稿し、知識を共有するフォーラムです。
-
Neo4j GitHub Repository
- Neo4jのオープンソースコードとコントリビューションガイドラインを提供しています。
これらの参考情報は、本記事で紹介した技術やコンセプトについてさらに詳しく学びたい方々にとって有用なリソースとなるでしょう。グラフデータベースとNeo4jの世界は急速に発展しており、最新の情報や best practices を把握するために、これらのリソースを定期的にチェックすることをお勧めします。