こんにちは!最近、Preferred Networks社からリリースされた日本語テキスト埋め込みモデル「PLaMo-Embedding-1B」を使って、カレーのレシピを意味的に検索できるシステムを構築してみました。本記事では、Google Colabで誰でも簡単に試せる形で実装方法を解説します。
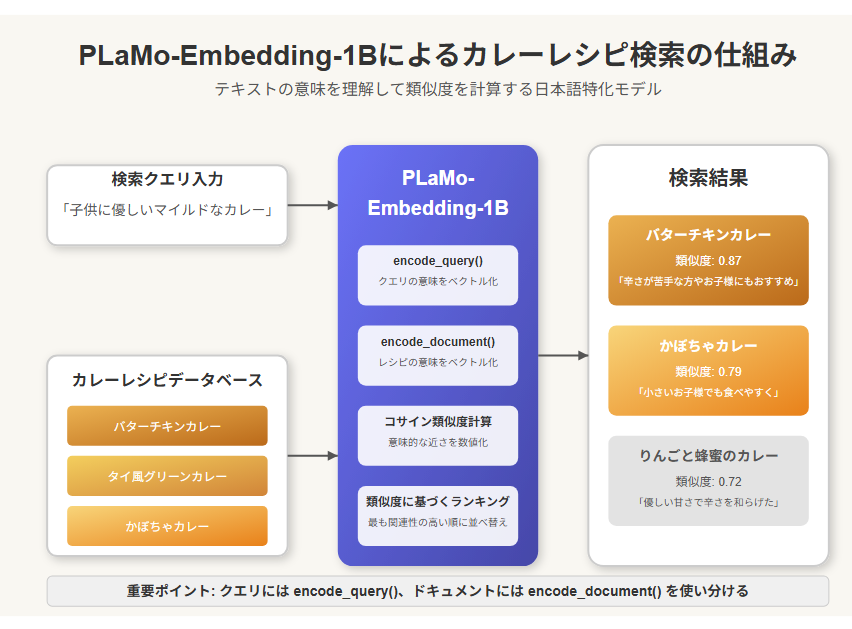
1. PLaMo-Embedding-1Bとは?
PLaMo-Embedding-1Bは、Preferred Networks社が開発した日本語に特化したテキスト埋め込みモデルです。日本語テキスト埋め込みのためのベンチマークであるJMTEBにおいて、以下のような優れた性能を示しています:
- 総合スコア: 76.10(トップクラス)
- 特に検索タスクで:79.94(最高クラス)
主な特徴:
- 日本語特化: 日本語テキストの意味的な類似性を捉える能力が高い
- 比較的軽量: 1Bパラメータで実用的な処理速度を実現
- 商用利用可能: Apache v2.0ライセンスで公開
2. 環境セットアップ
Google Colabで必要なライブラリをインストールします:
# 必要なライブラリのインストール
!pip install sentencepiece
!pip install transformers
!pip install pandas matplotlib ipywidgets
3. サンプルデータの準備
今回はカレーレシピのサンプルデータを用意します:
import pandas as pd
import json
# サンプルデータの作成
curry_recipes = [
{
"id": 1,
"title": "基本のビーフカレー",
"description": "玉ねぎとトマトの旨味がたっぷり染み込んだ定番の家庭的なビーフカレーです。カレールウと市販のスパイスだけで誰でも簡単に作れます。",
"ingredients": ["牛肉", "玉ねぎ", "にんじん", "じゃがいも", "カレールウ", "トマト"]
},
{
"id": 2,
"title": "バターチキンカレー",
"description": "トマトとバターの組み合わせで酸味を抑えたマイルドな味わいが特徴です。クリーミーな口当たりで、辛さが苦手な方やお子様にもおすすめの一品です。",
"ingredients": ["鶏もも肉", "トマト", "バター", "生クリーム", "ガラムマサラ", "ターメリック"]
},
{
"id": 3,
"title": "タイ風グリーンカレー",
"description": "ココナッツミルクを使ったタイ風グリーンカレーは、辛さと香りが特徴的です。本格的なタイ料理の味わいをご家庭で楽しめます。",
"ingredients": ["鶏肉", "ナス", "ピーマン", "グリーンカレーペースト", "ココナッツミルク", "ナンプラー"]
},
{
"id": 4,
"title": "野菜たっぷりキーマカレー",
"description": "挽き肉と細かく刻んだ野菜がたっぷり入ったヘルシーなカレーです。スパイシーな味わいですが、トマトの酸味で食べやすくなっています。",
"ingredients": ["合挽き肉", "玉ねぎ", "人参", "ズッキーニ", "トマト", "スパイスミックス"]
},
{
"id": 5,
"title": "りんごと蜂蜜のカレー",
"description": "りんごの甘さと蜂蜜の優しい甘さで辛さを和らげた、子供から大人まで楽しめるカレーです。フルーティーな風味が特徴です。",
"ingredients": ["豚肉", "りんご", "はちみつ", "玉ねぎ", "人参", "カレールウ"]
},
{
"id": 6,
"title": "スパイシーラムカレー",
"description": "本場インド風の香り高いスパイスを使った本格的なラム肉のカレーです。深みのある辛さと羊肉の旨味が楽しめる大人向けの一品です。",
"ingredients": ["ラム肉", "玉ねぎ", "ガラムマサラ", "クミン", "コリアンダー", "チリパウダー"]
},
{
"id": 7,
"title": "かぼちゃカレー",
"description": "かぼちゃの自然の甘みで小さいお子様でも食べやすく仕上げたカレーです。栄養価も高く、野菜嫌いのお子様にもおすすめです。",
"ingredients": ["かぼちゃ", "玉ねぎ", "人参", "鶏肉", "カレールウ", "牛乳"]
},
{
"id": 8,
"title": "シーフードココナッツカレー",
"description": "エビやイカなどの魚介の旨味とココナッツミルクのまろやかさが絶妙に調和した贅沢なカレーです。南国の風味が楽しめます。",
"ingredients": ["エビ", "イカ", "ムール貝", "ココナッツミルク", "レモングラス", "レッドカレーペースト"]
},
{
"id": 9,
"title": "チキンマサラ",
"description": "北インド地方の伝統的なカレーで、ヨーグルトでマリネした鶏肉とスパイスの風味が絶妙です。本場インドの味わいが楽しめます。",
"ingredients": ["鶏もも肉", "ヨーグルト", "トマト", "玉ねぎ", "ガラムマサラ", "ターメリック"]
},
{
"id": 10,
"title": "ゴアフィッシュカレー",
"description": "インド西部の魚介を使った伝統的なカレーで、ココナッツとタマリンドの酸味が特徴です。スパイシーながらも複雑な味わいが楽しめます。",
"ingredients": ["白身魚", "ココナッツ", "タマリンド", "赤唐辛子", "ターメリック", "マスタードシード"]
}
]
# DataFrameに変換
df_recipes = pd.DataFrame(curry_recipes)
# 検索用テキストの作成(タイトルと説明文を連結)
df_recipes['search_text'] = df_recipes['title'] + " " + df_recipes['description']
# データの確認
print(f"レシピ数: {len(df_recipes)}")
df_recipes[['id', 'title']].head()
4. PLaMo-Embedding-1Bのロードと埋め込みベクトル生成
Google Colabの環境でモデルをロードし、各レシピのテキストを埋め込みベクトルに変換します:
import torch
import torch.nn.functional as F
from transformers import AutoModel, AutoTokenizer
import numpy as np
# モデルとトークナイザーのロード
tokenizer = AutoTokenizer.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
model = AutoModel.from_pretrained("pfnet/plamo-embedding-1b", trust_remote_code=True)
# GPUが利用可能であればGPUを使用
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
print(f"Using device: {device}")
# 埋め込みベクトルの生成
recipe_embeddings = []
with torch.inference_mode():
# バッチ処理で効率化
texts = df_recipes['search_text'].tolist()
# ドキュメントとしてエンコード
embeddings = model.encode_document(texts, tokenizer)
recipe_embeddings = embeddings.cpu().numpy()
print(f"埋め込みベクトルの形状: {recipe_embeddings.shape}")
5. 意味検索システムの実装
Google Colab上で検索できるシステムを実装します:
# 検索関数の定義
def search_recipes(query, top_k=3):
# クエリをベクトル化
with torch.inference_mode():
# 重要: クエリは encode_query を使用
query_embedding = model.encode_query(query, tokenizer)
query_embedding = query_embedding.cpu().numpy()
# コサイン類似度の計算
similarities = []
for idx, embedding in enumerate(recipe_embeddings):
# コサイン類似度
similarity = np.dot(query_embedding, embedding) / (
np.linalg.norm(query_embedding) * np.linalg.norm(embedding)
)
similarities.append((idx, float(similarity)))
# 類似度でソート
similarities.sort(key=lambda x: x[1], reverse=True)
# 上位のレシピを返す
results = []
for idx, similarity in similarities[:top_k]:
recipe = df_recipes.iloc[idx].to_dict()
recipe['similarity'] = similarity
results.append(recipe)
return results
# 検索UIの実装
def search_ui(query, top_k=3):
results = search_recipes(query, top_k)
# 結果の表示
print(f"検索クエリ: '{query}'")
print("-" * 50)
for i, result in enumerate(results, 1):
print(f"#{i} {result['title']} (類似度: {result['similarity']:.4f})")
print(f"説明: {result['description']}")
print(f"材料: {', '.join(result['ingredients'])}")
print("-" * 50)
# 類似度のグラフ表示
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
titles = [r['title'] for r in results]
similarities = [r['similarity'] for r in results]
plt.barh(titles, similarities)
plt.xlabel('類似度')
plt.title(f"'{query}' に類似したレシピ")
plt.xlim(0, 1)
plt.tight_layout()
plt.show()
# インタラクティブUI
from IPython.display import display
import ipywidgets as widgets
def interactive_search():
query_input = widgets.Text(
value='子供に優しいマイルドなカレー',
placeholder='検索したいカレーの特徴を入力',
description='検索:',
layout=widgets.Layout(width='70%')
)
top_k_slider = widgets.IntSlider(
value=3,
min=1,
max=10,
step=1,
description='表示件数:',
layout=widgets.Layout(width='50%')
)
search_button = widgets.Button(
description='検索',
button_style='primary',
layout=widgets.Layout(width='20%')
)
output = widgets.Output()
def on_search_button_clicked(_):
with output:
output.clear_output()
search_ui(query_input.value, top_k_slider.value)
search_button.on_click(on_search_button_clicked)
# UIの配置
display(widgets.HBox([query_input, search_button]))
display(top_k_slider)
display(output)
# 初期検索結果を表示
with output:
search_ui(query_input.value, top_k_slider.value)
# インタラクティブ検索UIの表示
interactive_search()
6. 使用例と比較検証
検索例1:「子供に優しいマイルドなカレー」
search_ui("子供に優しいマイルドなカレー", top_k=3)

期待される結果
PLaMo-Embedding-1Bは意味的な類似性を捉えるため、以下のようなレシピが上位に表示されます:
- 「バターチキンカレー」- "辛さが苦手な方やお子様にもおすすめ"という記述に対応
- 「りんごと蜂蜜のカレー」- "優しい甘さで辛さを和らげた、子供から大人まで"という記述に対応
- 「かぼちゃカレー」- "自然の甘みで小さいお子様でも食べやすく"という記述に対応
検索例2:「本格的なスパイシーなインド風カレー」
search_ui("本格的なスパイシーなインド風カレー", top_k=3)

期待される結果
- 「スパイシーラムカレー」- "本場インド風の香り高いスパイス"という記述に対応
- 「チキンマサラ」- "北インド地方の伝統的なカレー"という記述に対応
- 「ゴアフィッシュカレー」- "インド西部の伝統的なカレー"という記述に対応
キーワード検索との比較
単純なキーワード検索との違いを確認するために、以下のコードも実行します:
# キーワード検索の実装
def keyword_search(query, top_k=3):
# クエリを分割してキーワードにする
keywords = query.lower().split()
# 各レシピとキーワードの一致度を計算
matches = []
for idx, row in df_recipes.iterrows():
# テキストを小文字に変換
text = row['search_text'].lower()
# 含まれるキーワードの数をカウント
count = sum(1 for keyword in keywords if keyword in text)
# マッチしたキーワードの割合を計算
match_ratio = count / len(keywords) if keywords else 0
matches.append((idx, match_ratio))
# マッチ度でソート
matches.sort(key=lambda x: x[1], reverse=True)
# 上位のレシピを返す
results = []
for idx, match_ratio in matches[:top_k]:
recipe = df_recipes.iloc[idx].to_dict()
recipe['similarity'] = match_ratio
results.append(recipe)
return results
# キーワード検索UIの実装
def keyword_search_ui(query, top_k=3):
results = keyword_search(query, top_k)
print(f"キーワード検索: '{query}'")
print("-" * 50)
for i, result in enumerate(results, 1):
print(f"#{i} {result['title']} (マッチ度: {result['similarity']:.4f})")
print(f"説明: {result['description']}")
print("-" * 50)
# 比較実行
print("=== 意味ベース検索 ===")
search_ui("子供に優しいマイルドなカレー", top_k=3)
print("\n=== キーワード検索 ===")
keyword_search_ui("子供に優しいマイルドなカレー", top_k=3)

実行すると、キーワード検索では「子供」「優しい」「マイルド」という単語を含むレシピだけがヒットするのに対し、PLaMo-Embedding-1Bによる意味検索では、それらの単語を直接含まなくても「辛くない」「お子様向け」「甘み」などの概念的に関連する表現を含むレシピもヒットします。
まとめ

本記事では、PLaMo-Embedding-1Bを使ってカレーレシピの意味検索システムを構築する方法を紹介しました。キーワード検索と異なり、意味的な類似性に基づく検索が可能になるため、ユーザーの意図をより正確に捉えた検索結果を提供できます。
PLaMo-Embedding-1Bは日本語に特化した高性能なテキスト埋め込みモデルであり、特に検索タスクでは優れた性能を発揮します。また、Apache v2.0ライセンスで公開されており、商用利用も可能です。
今回はカレーレシピを例にしましたが、この技術は様々な分野に応用可能です:
- 社内文書検索システム
- ECサイトの商品検索
- Q&Aシステムでの類似質問検索
- 論文や技術資料の意味ベース検索
ぜひ皆さんもPLaMo-Embedding-1Bを使って、テキスト検索の可能性を広げてみてください!
参考リンク
免責事項
本記事の作成にあたり、文章や図解の生成にClaude Sonnetを、ファクトチェックにGenSparkを活用しました。最終的な編集と確認は筆者が行っています。