はじめに
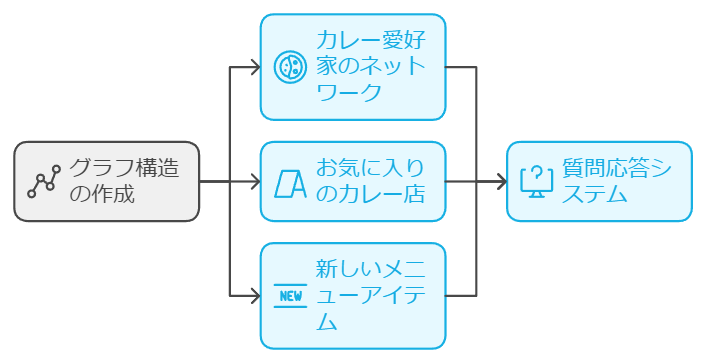
こんにちは、カレー愛好家の皆さん!今回は、Pythonと大規模言語モデル(LLM)を使って、カレーに関する知識を管理し、質問に答えるシステムを作ってみました。このシステムでは、カレー好きの人々のネットワークや、お気に入りのカレー店、新しいメニューなどの情報をグラフ構造で表現し、それをベースに質問応答を行います。
システムのデモ動画:
記事の動画解説:
システムの概要

このシステムは以下の主要な機能を持っています:
- カレー関連の知識をグラフ構造で表現
- ユーザーのコメントを分析し、新しい知識をグラフに追加
- グラフの可視化(日本語対応)
- グラフ情報を基にした質問応答
それでは、知識グラフの魅力について詳しく見ていきましょう!
知識グラフのメリットと有益性
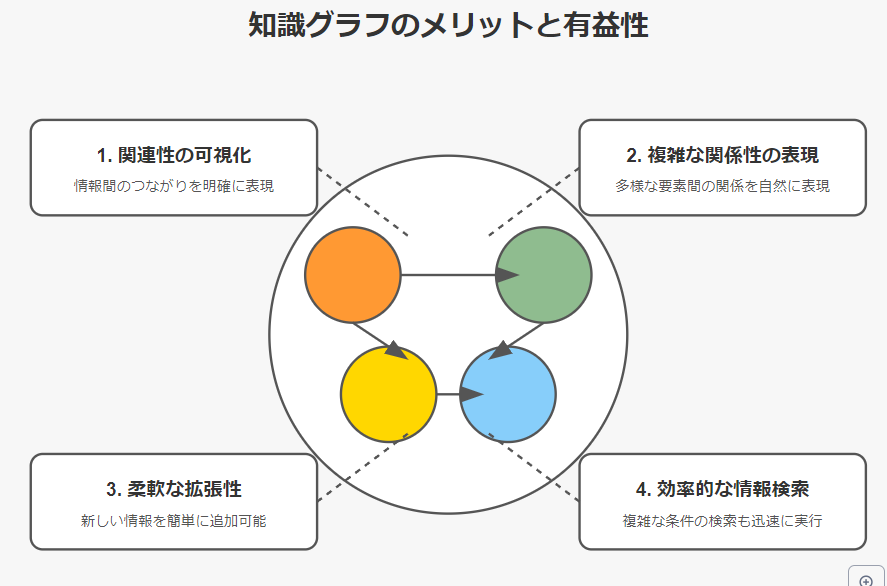
皆さんは「知識グラフ」という言葉を聞いて、どんなイメージを持ちますか?難しそう?複雑そう?確かに最初はそう感じるかもしれません。でも、実はとてもパワフルで、私たちの日常生活にも密接に関わっているんです。ここでは、知識グラフの素晴らしさを、カレーの世界を例に説明していきます。
1. 関連性の可視化
知識グラフの最大の特徴は、情報間の「つながり」を明確に表現できることです。
例えば、「Alice」さんが「Spicy King」というお店の「ゴーストペッパーカレー」を食べて「激辛」だと評価した、という情報があるとします。これを知識グラフで表現すると:
(Alice) -[食べた]-> (ゴーストペッパーカレー) -[提供元]-> (Spicy King)
(ゴーストペッパーカレー) -[特徴]-> (激辛)
このように、誰が何を食べて、それがどんな特徴を持っていて、どこのお店のものか、といった情報が一目で分かります。これは、カレー好きの皆さんにとって、新しい発見や洞察を得るのに役立ちます。
2. 複雑な関係性の表現
カレーの世界は奥が深く、様々な要素が複雑に絡み合っています。知識グラフは、このような複雑な関係性を自然に表現できます。
例えば:
- スパイスの組み合わせとカレーの味の関係
- 地域ごとのカレーの特徴
- シェフの経歴とその店のカレーのスタイルの関連性
これらの情報を知識グラフで表現することで、「なぜこの地域のカレーはこんな味なのか」「このシェフのカレーがユニークな理由は何か」といった深い理解につながります。
3. 柔軟な拡張性
知識グラフの素晴らしい点は、新しい情報を簡単に追加できることです。
例えば、最初は単純なカレー店の情報だけだったとしても:
- ユーザーの口コミ
- 新メニューの情報
- 食材の原産地データ
- カロリーや栄養成分
などを、既存の構造を壊すことなく追加できます。これにより、システムが成長するにつれて、より豊かで有用な情報ベースになっていきます。
4. 効率的な情報検索
知識グラフを使うと、複雑な検索クエリにも効率的に対応できます。
例えば:
- 「辛さ好きのAliceさんが高評価をつけた、予算3000円以下のカレー店」
- 「ココナッツミルクを使っていて、ベジタリアン対応もしている南インド風カレー」
このような複数の条件を組み合わせた検索も、知識グラフなら簡単に実現できます。
5. パターンの発見とレコメンデーション
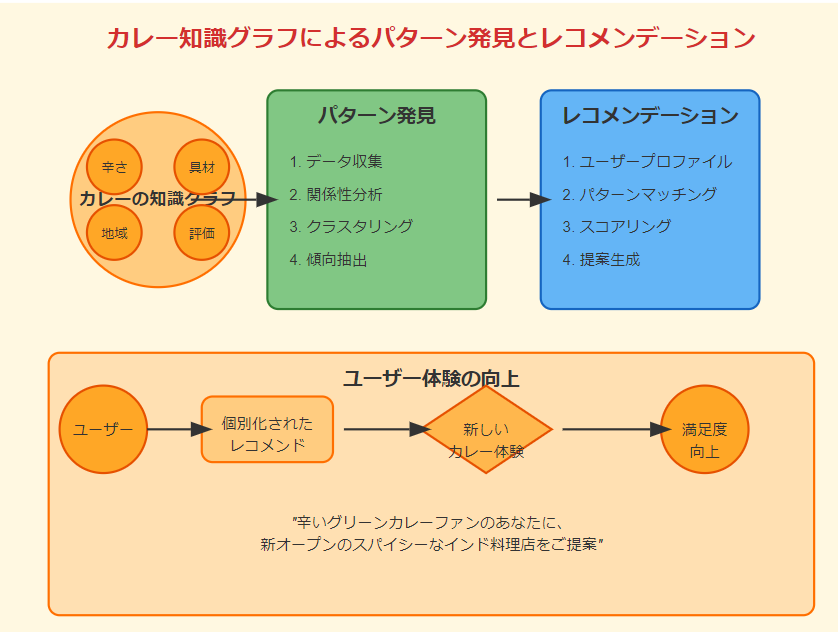
知識グラフの構造を分析することで、人間では気づきにくいパターンや関連性を発見できます。
例えば:
- 「このスパイスの組み合わせを好む人は、このタイプのカレーも好む傾向がある」
- 「この地域出身のシェフは、こんな特徴のあるカレーを作ることが多い」
こういった発見は、より精度の高いレコメンデーションシステムの構築につながります。
作成した知識グラフ
ノード情報
人物ノード
| 名前 | タイプ | 好み |
|---|---|---|
| Alice | Person | Spicy |
| Bob | Person | Mild |
| Charlie | Person | Veggie |
| David | Person | Meaty |
レストランノード
| 名前 | タイプ | 専門料理 | 価格帯 |
|---|---|---|---|
| Spicy King | Restaurant | Vindaloo | Medium |
| Green Curry House | Restaurant | Thai Green Curry | Low |
| Meat Paradise | Restaurant | Rogan Josh | High |
| Veggie Delight | Restaurant | Vegetable Korma | Medium |
エッジ情報(関係性)
| 人物 | 関係 | レストラン | 評価 | 訪問回数 |
|---|---|---|---|---|
| Alice | FAVORITE | Spicy King | 5 | 10 |
| Bob | VISITED | Green Curry House | 4 | 3 |
| Charlie | FAVORITE | Veggie Delight | 5 | 8 |
| David | FAVORITE | Meat Paradise | 4 | 6 |
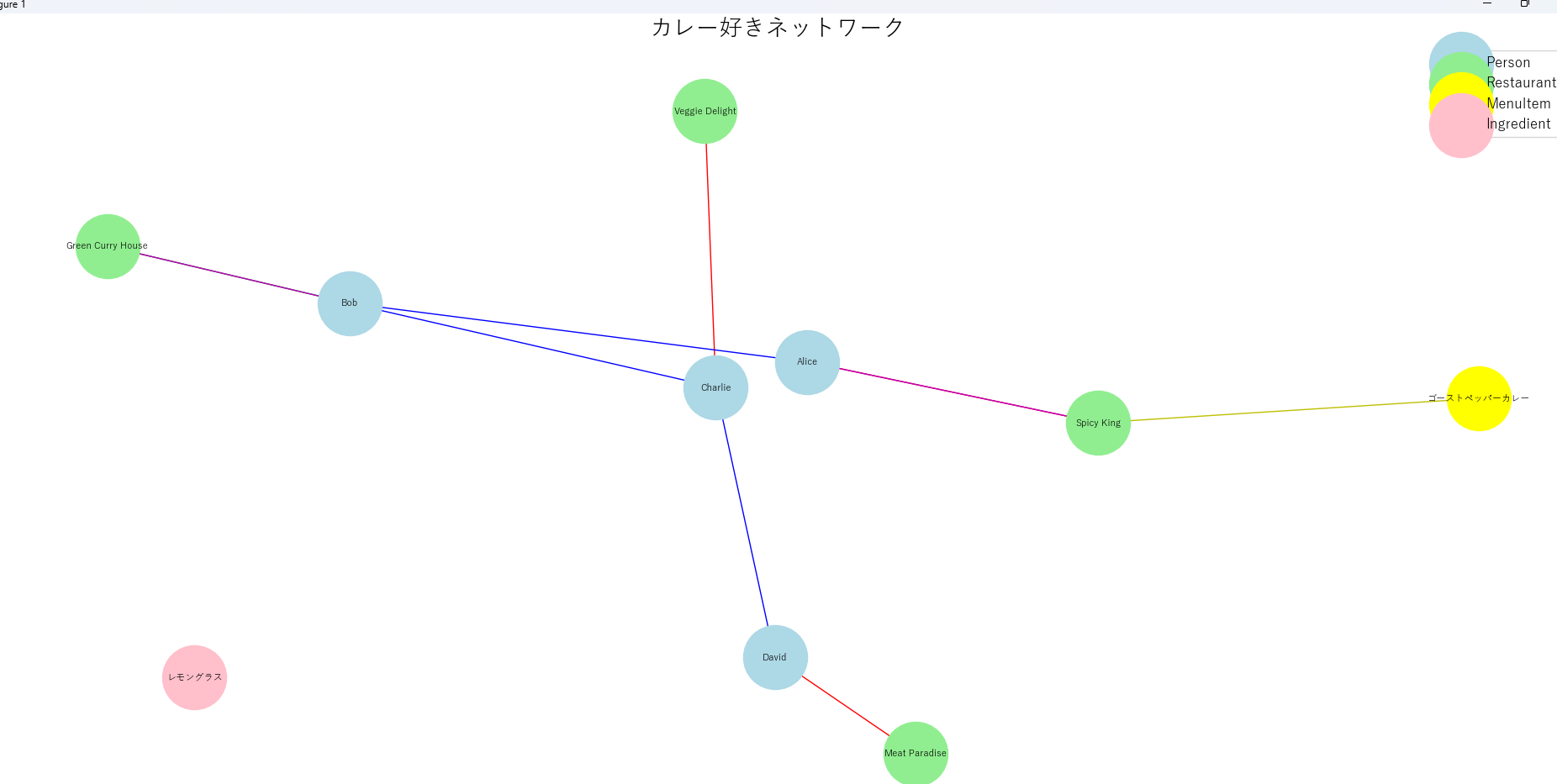
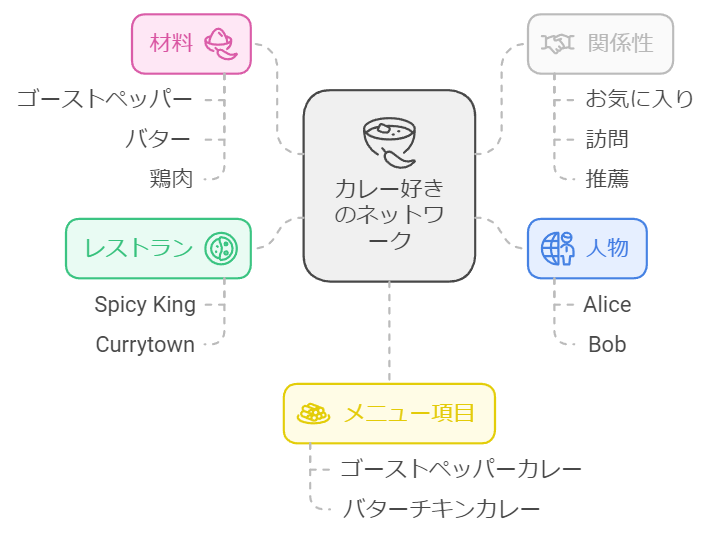
このグラフはカレー好きのソーシャルネットワークを表しています。青い丸は人物、緑の丸はレストラン、黄色の丸はメニュー項目、ピンクの丸は材料を示します。線の色は関係の種類を表し、赤はお気に入り、緑は訪問、青は推薦を意味します。例えば、AliceがSpicy Kingを頻繁に訪れていることや、新しく追加されたゴーストペッパーカレーの情報などが一目で分かります。このグラフを通じて、カレー好きのコミュニティの傾向や、人気のメニュー、レストラン間の関係性などを直感的に理解できます。
知識グラフに対してのLLM経由での質問と回答の例

| 質問 | 回答 | 評価 | コメント |
|---|---|---|---|
| 最も人気のあるカレー店はどこですか? | 与えられたグラフ情報からは十分な回答ができません。 | 適切 | システムは情報不足を正直に認識。誠実性と信頼性を示している。 |
| 新しく追加されたメニューや材料はありますか? | 与えられたグラフ情報からは、新しく追加されたメニューや材料は特定できません。 | 適切 | システムの限界を理解し、不確実な回答を避けている。 |
| 辛いカレーが好きな人におすすめの店は? | 辛いカレーが好きな人におすすめの店は、Aliceが好きなSpicy Kingです。 | 良好 | 知識グラフの情報を適切に活用し、論理的な推論を行っている。他の可能性も考慮できるとさらに良い。 |
| Bob氏のカレーの好みは? | Bob氏のカレーの好みは「Mild」です。 | 正確 | 知識グラフから直接得られる情報を正確に提供。関連情報(好きな店舗など)も提供できるとより良い。 |
| Charlie氏のお気に入りのレストランは? | Charlie氏のお気に入りのレストランはVeggie Delightです。 | 正確 | 個人とレストランの関係性を適切に把握し、具体的な情報を提供している。 |
総合評価:
- 情報の正確性: 高
- システムの限界認識: 優れている → 分からないことは分からないと回答できてる
- 知識グラフの活用: 効果的
- 回答の一貫性: 保たれている
改善の余地:
- より詳細な関連情報の提供
- 推論能力の向上(他の可能性の考慮)
- 動的な情報更新機能の実装
実装の詳細
それでは、実際の実装を見ていきましょう。
必要なライブラリのインポート
import networkx as nx
import matplotlib.pyplot as plt
import japanize_matplotlib
from typing import Dict, List, Any
import os
import json
from langchain_openai import ChatOpenAI
グラフ構造の管理(CurryKnowledgeGraph クラス)
class CurryKnowledgeGraph:
def __init__(self):
self.G = nx.MultiDiGraph()
self.initialize_graph()
def initialize_graph(self):
# 初期ノードとエッジの追加
persons = [
("Alice", "Spicy"),
("Bob", "Mild"),
("Charlie", "Veggie"),
("David", "Meaty")
]
for name, preference in persons:
self.add_node(name, "Person", {"name": name, "preference": preference})
restaurants = [
("Spicy King", "Vindaloo", "Medium"),
("Green Curry House", "Thai Green Curry", "Low"),
("Meat Paradise", "Rogan Josh", "High"),
("Veggie Delight", "Vegetable Korma", "Medium")
]
for name, specialty, price_range in restaurants:
self.add_node(name, "Restaurant", {"name": name, "specialty": specialty, "price_range": price_range})
self.add_edge("Alice", "Spicy King", "FAVORITE", {"rating": 5, "visits": 10})
self.add_edge("Bob", "Green Curry House", "VISITED", {"rating": 4, "visits": 3})
self.add_edge("Charlie", "Veggie Delight", "FAVORITE", {"rating": 5, "visits": 8})
self.add_edge("David", "Meat Paradise", "FAVORITE", {"rating": 4, "visits": 6})
def visualize(self):
plt.figure(figsize=(12, 8))
pos = nx.spring_layout(self.G)
nx.draw(self.G, pos, with_labels=True, node_color='lightblue', node_size=3000, font_size=10)
edge_labels = nx.get_edge_attributes(self.G, 'relationship')
nx.draw_networkx_edge_labels(self.G, pos, edge_labels=edge_labels)
plt.title("カレー好きネットワーク")
plt.axis('off')
plt.show()
def get_graph_info(self) -> str:
info = "グラフ情報:\n"
for node, data in self.G.nodes(data=True):
info += f"ノード: {node}, タイプ: {data.get('entity', 'Unknown')}, プロパティ: {data.get('properties', {})}\n"
for u, v, data in self.G.edges(data=True):
info += f"エッジ: {u} -> {v}, 関係: {data.get('relationship', 'Unknown')}, プロパティ: {data.get('properties', {})}\n"
return info
def add_node(self, name: str, entity: str, properties: Dict[str, Any]):
if name not in self.G:
self.G.add_node(name, entity=entity, properties=properties)
else:
self.G.nodes[name]['entity'] = entity
self.G.nodes[name]['properties'].update(properties)
def add_edge(self, source: str, target: str, relationship: str, properties: Dict[str, Any] = {}):
self.G.add_edge(source, target, relationship=relationship, properties=properties)
知識システム(CurryKnowledgeSystem クラス)
class CurryKnowledgeSystem:
def __init__(self):
self.graph = CurryKnowledgeGraph()
self.llm = ChatOpenAI(
model_name='gpt-3.5-turbo-16k',
temperature=0
)
def query_knowledge(self, question: str) -> str:
graph_info = self.graph.get_graph_info()
prompt = f"""
以下の情報は、カレー好きのソーシャルネットワークを表すグラフ構造です。この情報に基づいて質問に答えてください。
{graph_info}
質問: {question}
回答する際は、与えられたグラフ情報のみを使用し、それ以外の情報は使用しないでください。
情報が不足している場合は、「与えられた情報からは十分な回答ができません」と答えてください。
"""
response = self.llm.invoke(prompt)
return response.content
def add_comment(self, user: str, comment: str):
analysis_prompt = f"""
以下のユーザーコメントを分析し、カレーに関する情報を抽出してください。
ユーザー: {user}
コメント: {comment}
抽出する情報:
1. 言及されているレストラン名
2. 新しいメニュー項目
3. 使用されている材料
4. コメントの感情(ポジティブ/ネガティブ)
5. 評価(もし明示されていれば)
JSON形式で回答してください。
"""
response = self.llm.invoke(analysis_prompt)
try:
analysis = json.loads(response.content)
if 'restaurant' in analysis and analysis['restaurant']:
self.graph.add_node(analysis['restaurant'], "Restaurant", {"name": analysis['restaurant']})
self.graph.add_edge(user, analysis['restaurant'], "COMMENTED_ON", {
"sentiment": analysis.get('sentiment', ''),
"rating": analysis.get('rating', '')
})
if 'menu_item' in analysis and analysis['menu_item']:
self.graph.add_node(analysis['menu_item'], "MenuItem", {"name": analysis['menu_item']})
if 'restaurant' in analysis and analysis['restaurant']:
self.graph.add_edge(analysis['restaurant'], analysis['menu_item'], "HAS_MENU_ITEM")
if 'ingredients' in analysis and analysis['ingredients']:
for ingredient in analysis['ingredients']:
self.graph.add_node(ingredient, "Ingredient", {"name": ingredient})
if 'menu_item' in analysis and analysis['menu_item']:
self.graph.add_edge(analysis['menu_item'], ingredient, "CONTAINS")
print(f"コメントを分析し、グラフに追加しました: {analysis}")
except json.JSONDecodeError:
print(f"Error: LLMの応答をJSONとして解析できませんでした。")
def get_graph_summary(self) -> str:
summary = "現在のグラフ概要:\n"
summary += f"ノード数: {self.graph.G.number_of_nodes()}\n"
summary += f"エッジ数: {self.graph.G.number_of_edges()}\n"
summary += "ノードタイプ:\n"
node_types = {}
for _, data in self.graph.G.nodes(data=True):
node_type = data.get('entity', 'Unknown')
node_types[node_type] = node_types.get(node_type, 0) + 1
for node_type, count in node_types.items():
summary += f" - {node_type}: {count}\n"
return summary
システムの起動と実行 (main関数)
if __name__ == "__main__":
system = CurryKnowledgeSystem()
print("初期グラフの概要")
print(system.get_graph_summary())
system.graph.visualize()
# ユーザーコメントの追加
system.add_comment("Alice", "Spicy Kingの新メニュー、ゴーストペッパーカレーが激辛で美味しかった!辛さ好きにはたまらない一品です。")
system.add_comment("Bob", "Green Curry Houseで初めてレモングラスを使ったカレーを食べたけど、爽やかな風味が斬新だった。おすすめです!")
print("\nコメント追加後のグラフの概要")
print(system.get_graph_summary())
system.graph.visualize()
# 知識の問い合わせ
questions = [
"最も人気のあるカレー店はどこですか?",
"新しく追加されたメニューはありますか?",
"辛いカレーが好きな人におすすめの店は?",
"Bob氏のカレーの好みは?",
"Charlie氏のお気に入りのレストランは?"
]
for question in questions:
answer = system.query_knowledge(question)
print(f"\n質問: {question}")
print(f"回答: {answer}")
今後の発展可能性
このシステムは、以下のような方向で拡張できます:
- 時系列データの導入:カレーの人気トレンドの分析
- 感情分析の詳細化:ユーザーの好みをより細かく把握
- レシピ情報の統合:材料や調理法の知識ベースを構築
- 地理情報の追加:位置情報を基にしたカレー店推薦
- ユーザーインターフェースの開発:Webアプリケーション化
- 画像認識の統合:カレーの写真からメニューや材料を自動識別
- 多言語対応:様々な言語でのカレー情報の収集と分析
まとめ
今回作成したカレー知識グラフシステムは、グラフ構造とLLMを組み合わせることで、カレーに関する知識を柔軟に管理し、ユーザーの質問に答えることができます。このシステムを基に、さらに機能を拡張していけば、カレー愛好家のためのより高度な推薦システムや知識ベースの構築が可能になるでしょう。
知識グラフの力を借りることで、カレーの世界がより豊かに、より深く理解できるようになります。例えば:
- カレーの味の系統樹を作成し、新しいフュージョンカレーのアイデアを生み出す
- 地域ごとのスパイス使用傾向を分析し、カレーの文化人類学的研究に貢献する
- ユーザーの好みパターンを分析し、パーソナライズされたカレー体験を提供する
可能性は無限大です!
カレー好きの皆さん、ぜひこのシステムを使って、新しいカレーの世界を探索してみてください!辛さと香りと味わいの魔法の世界が、あなたを待っています。🍛✨
備忘録
課題: 非機能要件の整理が未完了
- 現在の実装では、LLMの最大長に関する制約や、グラフデータの最大量に関する問題が発生する可能性がある。
参考資料
- NetworkX documentation: https://networkx.org/documentation/stable/
- LangChain documentation: https://python.langchain.com/docs/get_started/introduction
- 中川大海, 岩澤有祐, 松尾豊, "グラフ表現を用いた知識獲得予測による潜在知識構造の抽出と活用," 国際会議 ICLR 2019, https://rlgm.github.io/papers/70.pdf
Happy Coding & Curry Tasting! 🚀🍛
記事作成後のイベント登壇での発表資料
クラス図/シーケンス図/実装
クラス図
シーケンス図
実装
pip install networkx matplotlib openai
動作環境
OS: Windows 11
Python 3.11.9
japanize-matplotlib==1.1.3
langchain-openai==0.2.0
matplotlib==3.9.2
networkx==3.3
openai==1.47.0
import networkx as nx
import matplotlib.pyplot as plt
import openai
import os
from typing import Dict, List, Any
class CurryKnowledgeGraph:
def __init__(self):
self.G = nx.Graph()
self.initialize_graph()
def initialize_graph(self):
# カレーの種類
curry_types = ["バターチキンカレー", "グリーンカレー", "マッサマンカレー", "ビーフカレー"]
# 材料
ingredients = ["鶏肉", "ココナッツミルク", "牛肉", "ジャガイモ", "タマネギ"]
# スパイス
spices = ["ターメリック", "クミン", "コリアンダー", "カルダモン", "唐辛子"]
# ノードの追加
self.G.add_nodes_from(curry_types, type="curry")
self.G.add_nodes_from(ingredients, type="ingredient")
self.G.add_nodes_from(spices, type="spice")
# エッジの追加(例)
self.G.add_edge("バターチキンカレー", "鶏肉")
self.G.add_edge("バターチキンカレー", "ターメリック")
self.G.add_edge("グリーンカレー", "ココナッツミルク")
self.G.add_edge("マッサマンカレー", "ジャガイモ")
self.G.add_edge("ビーフカレー", "牛肉")
def visualize(self):
pos = nx.spring_layout(self.G)
plt.figure(figsize=(12, 8))
nx.draw(self.G, pos, with_labels=True, node_color='lightblue', node_size=3000, font_size=8)
plt.title("カレー知識グラフ")
plt.axis('off')
plt.tight_layout()
plt.show()
class LLMInterface:
def __init__(self):
openai.api_key = os.getenv("OPENAI_API_KEY")
def ask(self, question: str) -> str:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたはカレーの専門家です。カレーについての質問に答えてください。"},
{"role": "user", "content": question}
]
)
return response.choices[0].message['content']
class CurryKnowledgeSystem:
def __init__(self):
self.graph = CurryKnowledgeGraph()
self.llm = LLMInterface()
def enrich_graph(self):
for node in self.graph.G.nodes():
if self.graph.G.nodes[node]['type'] == 'curry':
# カレーの特徴を尋ねる
question = f"{node}の特徴と作り方について教えてください。"
answer = self.llm.ask(question)
self.graph.G.nodes[node]['description'] = answer
# 材料とスパイスの関係を強化
ingredients = [n for n in self.graph.G.neighbors(node) if self.graph.G.nodes[n]['type'] == 'ingredient']
spices = [n for n in self.graph.G.neighbors(node) if self.graph.G.nodes[n]['type'] == 'spice']
for ingredient in ingredients:
question = f"{node}における{ingredient}の役割を説明してください。"
answer = self.llm.ask(question)
self.graph.G.edges[node, ingredient]['role'] = answer
for spice in spices:
question = f"{node}における{spice}の効果を説明してください。"
answer = self.llm.ask(question)
self.graph.G.edges[node, spice]['effect'] = answer
def extract_curry_knowledge(self, curry_name: str) -> str:
if curry_name not in self.graph.G.nodes():
return "指定されたカレーが見つかりません。"
node = self.graph.G.nodes[curry_name]
neighbors = list(self.graph.G.neighbors(curry_name))
knowledge = f"{curry_name}の知識:\n"
knowledge += f"説明: {node.get('description', '情報なし')}\n\n"
knowledge += "材料:\n"
for n in neighbors:
if self.graph.G.nodes[n]['type'] == 'ingredient':
role = self.graph.G.edges[curry_name, n].get('role', '情報なし')
knowledge += f"- {n}: {role}\n"
knowledge += "\nスパイス:\n"
for n in neighbors:
if self.graph.G.nodes[n]['type'] == 'spice':
effect = self.graph.G.edges[curry_name, n].get('effect', '情報なし')
knowledge += f"- {n}: {effect}\n"
return knowledge
def query(self, question: str) -> str:
# 簡単なキーワードベースのクエリ処理
if "材料" in question.lower():
curry_name = question.split("の材料")[0]
return self.get_ingredients(curry_name)
elif "スパイス" in question.lower():
curry_name = question.split("のスパイス")[0]
return self.get_spices(curry_name)
else:
# それ以外の質問はLLMに直接問い合わせる
return self.llm.ask(question)
def get_ingredients(self, curry_name: str) -> str:
if curry_name not in self.graph.G.nodes():
return f"{curry_name}は見つかりません。"
ingredients = [n for n in self.graph.G.neighbors(curry_name) if self.graph.G.nodes[n]['type'] == 'ingredient']
return f"{curry_name}の材料: {', '.join(ingredients)}"
def get_spices(self, curry_name: str) -> str:
if curry_name not in self.graph.G.nodes():
return f"{curry_name}は見つかりません。"
spices = [n for n in self.graph.G.neighbors(curry_name) if self.graph.G.nodes[n]['type'] == 'spice']
return f"{curry_name}のスパイス: {', '.join(spices)}"
# 使用例
if __name__ == "__main__":
system = CurryKnowledgeSystem()
print("グラフの初期状態を可視化")
system.graph.visualize()
print("グラフを強化中...")
system.enrich_graph()
print("バターチキンカレーの知識を抽出")
knowledge = system.extract_curry_knowledge("バターチキンカレー")
print(knowledge)
print("\nクエリの例:")
print(system.query("バターチキンカレーの材料は何ですか?"))
print(system.query("グリーンカレーのスパイスを教えてください。"))
print(system.query("最も人気のあるカレーは何ですか?"))
# 注意: このコードを実行する前に、OPENAI_API_KEYを環境変数として設定してください。