はじめに
ビッグデータの時代において、大規模なCSVファイルの処理は多くの開発者が直面する課題です。特に、メモリ使用量の制御と処理効率の向上は重要な問題となっています。この記事では、Pythonのイテレータを活用して、メモリ効率が良く、柔軟性の高いCSVデータ処理方法を紹介します。
実際のビジネスシナリオを想定したユースケースに焦点を当て、中級者のプログラマーにも役立つ実践的な技術を解説していきます。さらに、サンプルデータを生成するコードも含めることで、読者が直接コードを試せるようにします。
イテレータの基本と利点
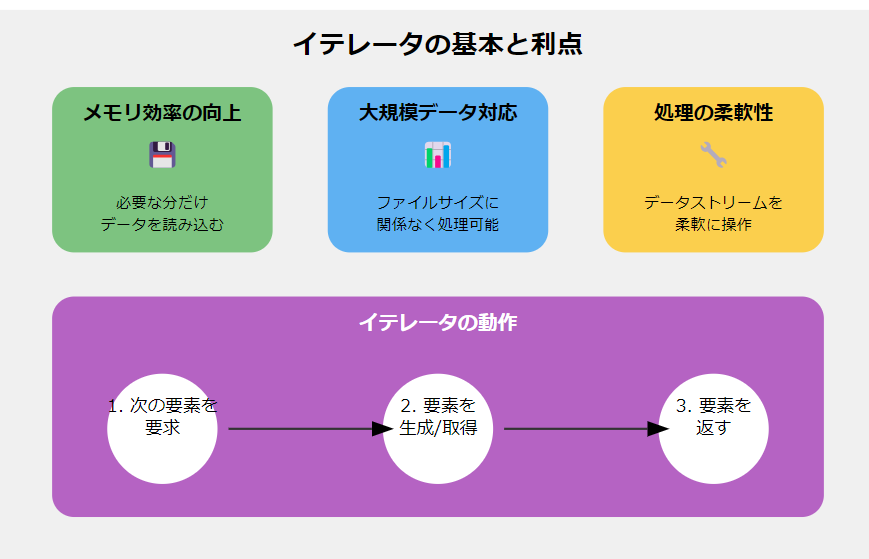
まず、イテレータを使用することの利点について簡単に説明しましょう:
- メモリ効率の向上: データを一度にすべてメモリに読み込む代わりに、必要なときに必要な分だけ読み込みます。
- 大規模データセットへの対応: ファイルサイズに関係なく、一定のメモリ使用量で処理が可能です。
- 処理の柔軟性: データストリームを柔軟に操作し、必要に応じて処理を追加や変更できます。
これらの利点は、特に大量のデータを扱う実務において重要です。
実践的なユースケース
ケース1: 販売データの分析と変換

ある小売店の大規模な販売データCSVファイルを処理するシナリオを考えてみましょう。このファイルには、日付、商品ID、価格、数量などの情報が含まれています。我々の目標は以下の処理を行うことです:
- 特定の期間のデータのみを抽出
- 価格を税込みに変換
- 売上金額(価格 * 数量)を計算
- カテゴリ別に集計
以下に、これらの要件を満たすコードを示します:
import csv
from datetime import datetime, timedelta
from typing import Iterator, Dict
from collections import defaultdict
import random
# サンプルデータ生成関数
def generate_sample_data(filename: str, num_rows: int):
categories = ['Electronics', 'Clothing', 'Food', 'Books', 'Toys']
start_date = datetime(2023, 1, 1)
with open(filename, 'w', newline='') as csvfile:
fieldnames = ['date', 'product_id', 'category', 'price', 'quantity']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for _ in range(num_rows):
date = start_date + timedelta(days=random.randint(0, 364))
writer.writerow({
'date': date.strftime('%Y-%m-%d'),
'product_id': f'PROD{random.randint(1, 1000):03d}',
'category': random.choice(categories),
'price': round(random.uniform(10, 1000), 2),
'quantity': random.randint(1, 10)
})
def process_sales_data(file_path: str, start_date: str, end_date: str) -> Iterator[Dict[str, any]]:
start = datetime.strptime(start_date, "%Y-%m-%d")
end = datetime.strptime(end_date, "%Y-%m-%d")
with open(file_path, 'r', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
date = datetime.strptime(row['date'], "%Y-%m-%d")
if start <= date <= end:
yield process_row(row)
def process_row(row: Dict[str, str]) -> Dict[str, any]:
# 税率を10%と仮定
tax_rate = 1.1
price = float(row['price'])
quantity = int(row['quantity'])
return {
'date': row['date'],
'product_id': row['product_id'],
'category': row['category'],
'price_with_tax': round(price * tax_rate, 2),
'quantity': quantity,
'total_sales': round(price * tax_rate * quantity, 2)
}
def analyze_sales(file_path: str, start_date: str, end_date: str):
category_sales = defaultdict(float)
total_sales = 0
for row in process_sales_data(file_path, start_date, end_date):
category_sales[row['category']] += row['total_sales']
total_sales += row['total_sales']
print(f"期間合計売上: ¥{total_sales:,.2f}")
print("\nカテゴリ別売上:")
for category, sales in category_sales.items():
print(f"{category}: ¥{sales:,.2f}")
# サンプルデータの生成と処理
sample_file = 'sample_sales_data.csv'
generate_sample_data(sample_file, 1000)
analyze_sales(sample_file, '2023-01-01', '2023-12-31')
このコードの特徴と利点を解説します:
-
イテレータの活用:
process_sales_data関数がイテレータを返すことで、大規模なCSVファイルでもメモリ効率よく処理できます。 - 日付による絞り込み: 指定された期間のデータのみを処理することで、不要なデータの処理を回避しています。
-
柔軟な行処理:
process_row関数で各行のデータを変換し、必要な計算を行っています。この部分は簡単にカスタマイズできます。 -
効率的な集計:
defaultdictを使用することで、カテゴリ別の集計を効率的に行っています。 -
サンプルデータ生成:
generate_sample_data関数により、テスト用のデータを簡単に生成できます。
ケース2: データクレンジングと変換

データ分析の前処理として、CSVファイルのクレンジングと変換が必要になることがよくあります。以下は、顧客データを処理する例です:
import csv
from typing import Iterator, Dict
import re
import random
import string
# サンプルデータ生成関数
def generate_sample_customer_data(filename: str, num_rows: int):
with open(filename, 'w', newline='') as csvfile:
fieldnames = ['name', 'email', 'phone', 'zip_code']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for _ in range(num_rows):
writer.writerow({
'name': f"{random.choice(['john', 'jane', 'bob', 'alice'])} {random.choice(['doe', 'smith', 'johnson', 'williams'])}",
'email': f"{''.join(random.choices(string.ascii_lowercase, k=5))}@{''.join(random.choices(string.ascii_lowercase, k=5))}.com",
'phone': f"{random.randint(100, 999)}-{random.randint(100, 999)}-{random.randint(1000, 9999)}",
'zip_code': f"{random.randint(10000, 99999)}"
})
def clean_customer_data(file_path: str) -> Iterator[Dict[str, str]]:
with open(file_path, 'r', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
yield clean_row(row)
def clean_row(row: Dict[str, str]) -> Dict[str, str]:
# 名前のフォーマット統一
row['name'] = row['name'].title()
# メールアドレスの検証
if not re.match(r"[^@]+@[^@]+\.[^@]+", row['email']):
row['email'] = 'invalid_email'
# 電話番号のフォーマット統一
row['phone'] = re.sub(r'\D', '', row['phone'])
if len(row['phone']) == 10:
row['phone'] = f"({row['phone'][:3]}) {row['phone'][3:6]}-{row['phone'][6:]}"
# 郵便番号のフォーマット統一
row['zip_code'] = row['zip_code'].zfill(5)
return row
def process_and_write(input_file: str, output_file: str):
with open(output_file, 'w', newline='') as csvfile:
fieldnames = ['name', 'email', 'phone', 'zip_code']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in clean_customer_data(input_file):
writer.writerow(row)
# サンプルデータの生成と処理
sample_input_file = 'sample_customer_data.csv'
sample_output_file = 'cleaned_customer_data.csv'
generate_sample_customer_data(sample_input_file, 100)
process_and_write(sample_input_file, sample_output_file)
# 結果の確認
print("クレンジング前のデータ (最初の5行):")
with open(sample_input_file, 'r') as f:
for _ in range(6):
print(f.readline().strip())
print("\nクレンジング後のデータ (最初の5行):")
with open(sample_output_file, 'r') as f:
for _ in range(6):
print(f.readline().strip())
このコードの特徴:
- イテレータベースの処理: 大規模なデータセットでもメモリ効率よく処理できます。
-
柔軟なデータクレンジング:
clean_row関数で各フィールドの検証と標準化を行っています。 - 再利用可能な設計: クレンジングロジックを分離することで、他のプロジェクトでも再利用しやすくなっています。
- 効率的な書き込み: 処理したデータを逐次的に新しいCSVファイルに書き込むため、メモリ使用量を抑えられます。
-
サンプルデータ生成:
generate_sample_customer_data関数により、テスト用のデータを簡単に生成できます。
まとめ

この記事では、Pythonのイテレータを活用してCSVデータを効率的に処理する方法を紹介しました。実際のビジネスシナリオに基づいた2つのユースケースを通じて、以下の点を学びました:
- イテレータを使用することで、大規模なデータセットでもメモリ効率よく処理できる
- 柔軟なデータ変換と集計が可能
- 再利用可能なコード設計の重要性
- サンプルデータ生成による容易な検証
これらの技術を活用することで、より効率的で信頼性の高いデータ処理システムを構築することができます。皆さんのプロジェクトでも、ぜひこれらの手法を試してみてください。
参考資料
この記事が皆さんのCSVデータ処理の効率化に役立つことを願っています。