はじめに

C#でLINQに慣れている人がPythonを触ると、データ操作の書き方に違いを感じることがあります。この記事では、実際に動かせるコード例を使って、LINQとPython内包表記の対応関係を整理してみます。
動作確認用のサンプルデータ
まず、この記事で使用するサンプルデータを定義します。
# サンプルデータの準備
from dataclasses import dataclass
from typing import List
import random
@dataclass
class Product:
id: int
name: str
price: float
category: str
@dataclass
class Customer:
id: int
name: str
city: str
@dataclass
class Order:
id: int
customer_id: int
product_id: int
quantity: int
# テストデータ生成
products = [
Product(1, "Laptop", 1500, "Electronics"),
Product(2, "Mouse", 50, "Electronics"),
Product(3, "Desk", 800, "Furniture"),
Product(4, "Monitor", 1200, "Electronics"),
Product(5, "Chair", 400, "Furniture"),
]
customers = [
Customer(101, "Alice", "Tokyo"),
Customer(102, "Bob", "Osaka"),
Customer(103, "Charlie", "Tokyo"),
]
orders = [
Order(1, 101, 1, 1),
Order(2, 102, 2, 3),
Order(3, 101, 4, 1),
Order(4, 103, 3, 1),
Order(5, 102, 5, 2),
]
基本操作の比較
1. Where(フィルタリング)
C# LINQ:
var expensiveProducts = products.Where(p => p.Price > 1000);
Python:
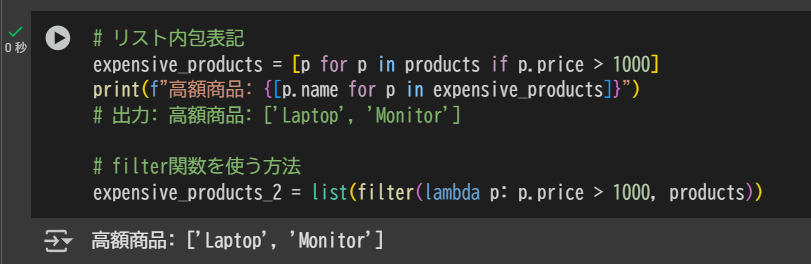
# リスト内包表記
expensive_products = [p for p in products if p.price > 1000]
print(f"高額商品: {[p.name for p in expensive_products]}")
# 出力: 高額商品: ['Laptop', 'Monitor']
# filter関数を使う方法
expensive_products_2 = list(filter(lambda p: p.price > 1000, products))
2. Select(射影・変換)
C# LINQ:
var productNames = products.Select(p => p.Name);
Python:
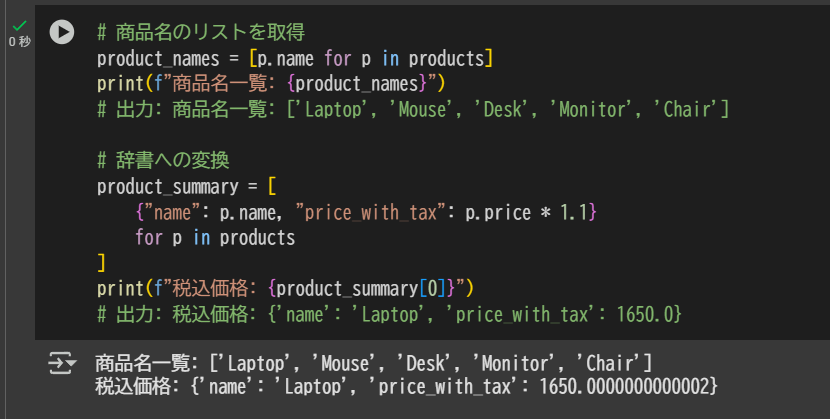
# 商品名のリストを取得
product_names = [p.name for p in products]
print(f"商品名一覧: {product_names}")
# 出力: 商品名一覧: ['Laptop', 'Mouse', 'Desk', 'Monitor', 'Chair']
# 辞書への変換
product_summary = [
{"name": p.name, "price_with_tax": p.price * 1.1}
for p in products
]
print(f"税込価格: {product_summary[0]}")
# 出力: 税込価格: {'name': 'Laptop', 'price_with_tax': 1650.0}
3. Where + Select の組み合わせ
C# LINQ:
var result = products
.Where(p => p.Category == "Electronics")
.Select(p => new { p.Name, DiscountPrice = p.Price * 0.9 });
Python:
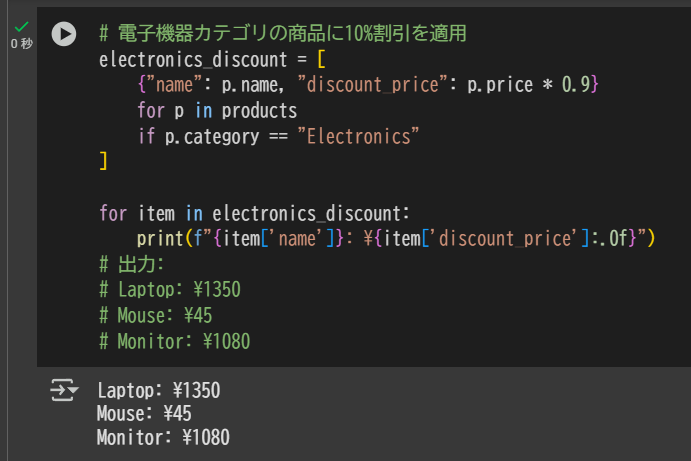
# 電子機器カテゴリの商品に10%割引を適用
electronics_discount = [
{"name": p.name, "discount_price": p.price * 0.9}
for p in products
if p.category == "Electronics"
]
for item in electronics_discount:
print(f"{item['name']}: ¥{item['discount_price']:.0f}")
# 出力:
# Laptop: ¥1350
# Mouse: ¥45
# Monitor: ¥1080
GroupBy の実装
itertoolsを使った方法
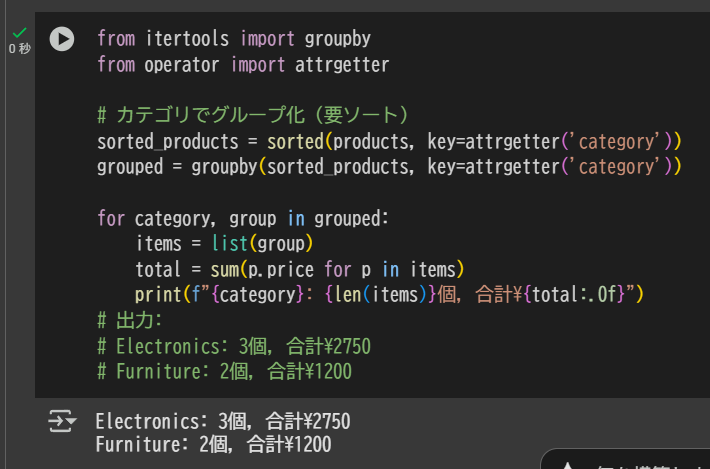
from itertools import groupby
from operator import attrgetter
# カテゴリでグループ化(要ソート)
sorted_products = sorted(products, key=attrgetter('category'))
grouped = groupby(sorted_products, key=attrgetter('category'))
for category, group in grouped:
items = list(group)
total = sum(p.price for p in items)
print(f"{category}: {len(items)}個, 合計¥{total:.0f}")
# 出力:
# Electronics: 3個, 合計¥2750
# Furniture: 2個, 合計¥1200
defaultdictを使った方法(推奨)
from collections import defaultdict
# より実践的なグループ化
category_groups = defaultdict(list)
for product in products:
category_groups[product.category].append(product)
# カテゴリごとの統計
for category, items in category_groups.items():
avg_price = sum(p.price for p in items) / len(items)
print(f"{category}: 平均価格¥{avg_price:.0f}")
# 出力:
# Electronics: 平均価格¥917
# Furniture: 平均価格¥600
Join の実装
Inner Join
C# LINQ:
var query = from o in orders
join c in customers on o.CustomerId equals c.Id
join p in products on o.ProductId equals p.Id
select new { c.Name, p.Name, o.Quantity };
Python:
# 注文情報を顧客・商品情報と結合
customers_dict = {c.id: c for c in customers}
products_dict = {p.id: p for p in products}
order_details = [
{
"customer": customers_dict[o.customer_id].name,
"product": products_dict[o.product_id].name,
"quantity": o.quantity,
"total": products_dict[o.product_id].price * o.quantity
}
for o in orders
if o.customer_id in customers_dict and o.product_id in products_dict
]
for detail in order_details:
print(f"{detail['customer']}が{detail['product']}を{detail['quantity']}個購入 (¥{detail['total']:.0f})")
# 出力:
# Aliceが Laptopを1個購入 (¥1500)
# Bobが Mouseを3個購入 (¥150)
# Aliceが Monitorを1個購入 (¥1200)
# Charlieが Deskを1個購入 (¥800)
# Bobが Chairを2個購入 (¥800)
集計処理
基本的な集計
# 各種集計
total_price = sum(p.price for p in products)
avg_price = total_price / len(products)
max_price = max(p.price for p in products)
min_price = min(p.price for p in products)
print(f"合計: ¥{total_price:.0f}")
print(f"平均: ¥{avg_price:.0f}")
print(f"最高: ¥{max_price:.0f}")
print(f"最低: ¥{min_price:.0f}")
# 出力:
# 合計: ¥3950
# 平均: ¥790
# 最高: ¥1500
# 最低: ¥50
# 条件付きカウント
expensive_count = sum(1 for p in products if p.price > 1000)
print(f"1000円以上の商品: {expensive_count}個")
# 出力: 1000円以上の商品: 2個
顧客ごとの購入金額集計
# 顧客ごとの購入金額を集計
customer_totals = defaultdict(float)
for order in orders:
customer = customers_dict[order.customer_id]
product = products_dict[order.product_id]
customer_totals[customer.name] += product.price * order.quantity
# ランキング表示
ranking = sorted(customer_totals.items(), key=lambda x: x[1], reverse=True)
for rank, (name, total) in enumerate(ranking, 1):
print(f"{rank}位: {name} - ¥{total:.0f}")
# 出力:
# 1位: Alice - ¥2700
# 2位: Bob - ¥950
# 3位: Charlie - ¥800
pandasを使ったLINQライクな実装
pandasを使うとLINQに近い書き心地になります。
import pandas as pd
# DataFrameに変換
df_products = pd.DataFrame([vars(p) for p in products])
df_orders = pd.DataFrame([vars(o) for o in orders])
df_customers = pd.DataFrame([vars(c) for c in customers])
# LINQライクなメソッドチェーン
result = (
df_orders
.merge(df_customers, left_on='customer_id', right_on='id')
.merge(df_products, left_on='product_id', right_on='id')
.assign(total=lambda x: x['price'] * x['quantity'])
.groupby(['name_x', 'city'])
.agg({'total': 'sum', 'quantity': 'sum'})
.reset_index()
.rename(columns={'name_x': 'customer'})
.sort_values('total', ascending=False)
)
print(result)
# 出力:
# customer city total quantity
# 0 Alice Tokyo 2700 2
# 1 Bob Osaka 950 5
# 2 Charlie Tokyo 800 1
パフォーマンス比較
import time
import itertools
# 大量データでのパフォーマンステスト
numbers = list(range(1000000))
# リスト内包表記
start = time.time()
result1 = [x * 2 for x in numbers if x % 2 == 0]
print(f"リスト内包表記: {time.time() - start:.3f}秒")
# filter + map
start = time.time()
result2 = list(map(lambda x: x * 2, filter(lambda x: x % 2 == 0, numbers)))
print(f"filter + map: {time.time() - start:.3f}秒")
# ジェネレータ式(遅延評価)
start = time.time()
result3 = (x * 2 for x in numbers if x % 2 == 0)
first_100 = list(itertools.islice(result3, 100))
print(f"ジェネレータ式(先頭100件): {time.time() - start:.6f}秒")
# 通常のforループ
start = time.time()
result4 = []
for x in numbers:
if x % 2 == 0:
result4.append(x * 2)
print(f"通常のforループ: {time.time() - start:.3f}秒")
# 実行結果例:
# リスト内包表記: 0.064秒
# filter + map: 0.134秒
# ジェネレータ式(先頭100件): 0.016秒
# 通常のforループ: 0.103秒
パフォーマンスの解釈
ポイント:
- 全件処理ならリスト内包表記
- 一部のみ必要ならジェネレータ式
- LINQの遅延評価に相当するのがジェネレータ式
C#開発者がハマりやすいポイント
1. 内包表記の順序
# 正しい: [出力 for 変数 in イテラブル if 条件]
result = [x * 2 for x in numbers if x > 0]
# LINQの順序で書くとエラー
# result = [for x in numbers if x > 0 select x * 2] # NG
2. groupbyの注意点
# Pythonのgroupbyは事前ソートが必須!
from itertools import groupby
# ソートしないと正しくグループ化されない
data = [1, 2, 1, 3, 2]
grouped = groupby(data) # 期待通りに動かない
# 正しい使い方
sorted_data = sorted(data)
grouped = groupby(sorted_data)
for key, group in grouped:
print(f"{key}: {list(group)}")
機能比較表
| 処理 | C# (LINQ) | Python | 備考 |
|---|---|---|---|
| フィルタ | Where |
[x for x in items if ...] |
内包表記のif部分 |
| 変換 | Select |
[f(x) for x in items] |
内包表記の出力部分 |
| グループ化 | GroupBy |
defaultdict or groupby
|
groupbyは要ソート |
| 結合 | Join |
辞書化して内包表記 | 手動実装が必要 |
| ソート | OrderBy |
sorted() |
keyパラメータを活用 |
| 集計 | Sum/Count/Average |
sum()/len()/mean() |
標準関数を組み合わせ |
まとめ

C#のLINQとPythonの内包表記は発想は似ていますが、規模や用途に応じて適切な手法が異なります。数千件程度なら内包表記で十分ですが、数十万件規模ではジェネレータ式がメモリ効率に優れます。さらに複雑な処理ではpandasを使うことでLINQのような操作が可能になります。
参考リンク