こちらの記事で知ったのですが、DevToysというツールが流行っているそうですね。実際に軽く触ってみた感じ、色々まとまっていて大変便利なツールだと感じました。
同時にこのツールは普段の業務で使うものではない、とも感じました。
なぜかと言うとこのツール、GUIでしか使えないんですよ。vimなりVS Codeなりで作業している時、わざわざマウスに手を伸ばしてポチポチするのは面倒で仕方がありません。また、わざわざテキストをコピーしたりファイルをひとつひとつ選択したりするのも非効率です。
ではこのツールの使いどころはいつか。
それは「普段はやらないけどたまに必要になるタスク」を処理する時です。
例えばJWTデコーダーが分かりやすいですね。こんなものはJWTの仕様を少しでも知っていればワンライナーで書けます。そちらの方が応用も効きますからワークフローに組み込むのも容易に違いありません。わざわざGUIのツールを使うメリットなんてないのです。
しかし普段JWTを扱わない人がたまたまこれをパースしなければならなくなった場合なら話は違います。わざわざトークンひとつをパースするために「JWTとは…」と仕様を調べるよりもその辺の適当なツールにコピペしてしまったほうが早い。そして「その辺の適当なツール」がひとつにまとまっていればツールを探す手間が省ける。これがDevToysの価値だと感じました。
本記事では、DevToysに実装されている機能に対して「もし自分が普段の業務に組み込むなら」という前提で代替案を提案します。「もっと楽なやり方があるよ!」というものがあればぜひコメントで教えてください。
変換ツール
JSON <> YAML変換ツール
調べた限り、このような機能を実現するツールは存在しないようでした。しかしJSONやYAMLを扱う機能はほとんどの言語で提供されているので、これを利用すれば簡単に実装可能です。とりあえずPythonで書いてみました。(どうせなら、とTOMLも扱ってみました)
# ! /usr/bin/env python3
import argparse
import sys
import traceback
import json
import yaml
import toml
class JsonFormatter:
def load(self, src):
return json.load(src)
def dump(self, obj):
return json.dumps(obj)
class YamlFormatter:
def load(self, src):
return yaml.load(src, Loader=yaml.BaseLoader)
def dump(self, obj):
return yaml.dump(obj, Dumper=yaml.Dumper)
class TomlFormatter:
def load(self, src):
return toml.load(src)
def dump(self, obj):
return toml.dumps(obj)
def parse_arguments():
parser = argparse.ArgumentParser(
description='Convert data format to other')
parser.add_argument('-f', '--from', dest='from_format', default='json',
help='Source format [' + ','.join(FORMATS.keys()) + ']')
parser.add_argument('-t', '--to', dest='to_format', default='yaml',
help='Target format [' + ','.join(FORMATS.keys()) + ']')
parser.add_argument('filepath', type=argparse.FileType('r'),
nargs='?', default=sys.stdin)
return parser.parse_args()
def exit_if_arguments_invalid(args):
for f in [args.from_format, args.to_format]:
if f.lower() not in FORMATS:
print_format_error(f)
sys.exit(1)
def print_format_error(user_format):
msg = 'Invalid format: {}\nPlease select one of the following.\n{}'
msg = msg.format(
user_format,
'\n'.join([' - ' + f for f in FORMATS.keys()]))
print(msg, file=sys.stderr)
def load(src, fmt):
try:
formatter = FORMATS[fmt.lower()]()
return formatter.load(src)
except:
traceback.print_exc()
sys.exit(1)
def dump(obj, fmt):
try:
formatter = FORMATS[fmt.lower()]()
return formatter.dump(obj)
except:
traceback.print_exc()
sys.exit(1)
if __name__ == '__main__':
FORMATS = {
'json': JsonFormatter,
'yaml': YamlFormatter,
'toml': TomlFormatter,
}
args = parse_arguments()
exit_if_arguments_invalid(args)
input_data = load(args.filepath, args.from_format)
output_data = dump(input_data, args.to_format)
print(output_data, end='')j
基数変換ツール
16進数、10進数、8進数の場合は比較的簡単にコマンドライン上で扱うことが可能です。
Bashでは各基数の値をこのように表します。
# 16進数
0x32
# 10進数
50
# 8進数
062
# n進数(例はn=2の場合)
$((2#00110010))
これを使って基数を変換するとこうなります。
# 16進数
printf '%x\n' 50
printf '%x\n' 072
printf '%x\n' $((2#1110))
# 10進数
echo $((0xfa))
echo $((051))
echo $((2#0100))
printf '%d\n' 0xfa
printf '%d\n' 051
printf '%d\n' $((2#0100))
# 8進数
printf '%o\n' 0x9a
printf '%o\n' 80
printf '%o\n' $((2#0101))
基数が上記以外(例:2進数)だと少し難易度が上がります。bcという計算用のコマンドが用意されているのでこれを使用します。bcは任意の精度で計算をするためのツールで独自の言語を使用します。普通はこのように対話的に使用します。
$ bc
bc 1.07.1
Copyright 1991-1994, (以下略)
1 + 1
2
しかし計算式を標準入力やファイルから入力してやることで、bcを非対話的に使用することが可能です。また入力および出力の基数はibaseとobaseで指定します。
$ echo '2 + 3' | bc
5
$ cat sample
obase=16
3 * 4
$ bc < sample
C
従って基数を変換する計算はこのようになります。
# obase-->ibaseの順に書く必要がある点に注意。
# さもないとobaseの入力が4進数で解釈されてしまう。
$ echo "obase=16;ibase=4;3210" | bc
E4
エンコーダー/デコーダー
HTMLエンコーダー/デコーダー
これも適当なツールが見つかりませんでした。しかしWeb用途で使われる言語であれば簡単に実現可能です。
今回は標準ライブラリで実現可能だったPythonで実装します。
# !/usr/bin/env python3
import html
import sys
if __name__ == '__main__':
print(html.escape(sys.argv[1]), end='') # デコードする場合はunescapeを使用
URLエンコーダー/デコーダー
適当なツールが見つかりませんでした。Pythonの標準ライブラリで実現可能です。
# !/usr/bin/env python3
import urllib.parse
import sys
if __name__ == '__main__':
print(urllib.parse.quote(sys.argv[1]), end='') # デコードする場合はunquoteを使用
Base64エンコーダー/デコーダー
base64というコマンドが利用可能です。
base64にエンコードする際は特にオプションの指定は必要ありません。デコードする際は-dまたは--decodeオプションを指定してください。
# エンコード
$ echo 'data' | base64
ZGF0YQo=
# デコード
$ echo 'ZGF0YQo=' | base64 --decode
data
余談ですが、フロントで仕事をする際バイナリをデータURLに変換したいことがあるのですが、こういうスクリプトを用意しておくと大変便利でした。
# !/bin/bash
mimetype=$(file -b --mime-type $1)
hash=$(base64 -w 0 $1)
printf 'data:%s;base64,%s' $mimetype $hash
GZipを利用した文字列の圧縮と展開
gzipコマンドを利用します。通常gzipは指定したファイルを圧縮後の結果に置き換えてしまうのですが、-cオプションを付けることで標準出力に書き出すことができます。またgzipで解凍する際には-d、--decompress、--uncompressのいずれかのオプションが必要です。
DevToysでは圧縮したデータをBase64しているので、同じ結果を得るためには次のようなコマンドになります。
# エンコード
$ echo 'data' | gzip -c | base64
H4sIAAAAAAAAA0tJLEnkAgCCxcHmBQAAAA==
# デコード
$ echo 'H4sIAAAAAAAAA0tJLEnkAgCCxcHmBQAAAA==' | base64 -d | gzip --decompress
data
JWTデコーダー
JWTは単純にヘッダー、ペイロード、署名をBase64でエンコードしたものを"."で結合しただけの文字列です。従ってcutコマンドを使えば簡単に元の値を取得することができます。
cutコマンドはCSVのような文字列からデータを切り出すことができるコマンドです。-dオプションで区切り文字を指定し、-fオプションで何番目のフィールドを表示するかを指定します。これを使ってJWTから値を取り出す例は次のようになります。
jwt_data="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c"
# ヘッダー(Base64でInvalid Inputが出る場合があっても無視しています)
$ echo $jwt_data | cut -d. -f1 | base64 -d 2>/dev/null
{"alg":"HS256","typ":"JWT"}
# ペイロード(Base64でInvalid Inputが出る場合があっても無視しています)
$ echo $jwt_data | cut -d. -f2 | base64 -d 2>/dev/null
{"sub":"1234567890","name":"John Doe","iat":1516239022}
フォーマッター
JSONフォーマッター
jqという、JSONをCLI上で操作することのできるツールがあります。これを利用すれば、成形されたJSON文字列を取得することが可能です。
$ echo '{"foo":"FOO"}' | jq
{
"foo": "FOO"
}
jqはJSONを成形する以外にも、JSONデータの中から必要な個所だけを抽出したり簡単な計算もできる優れものですので、ご存じなければこの機会にぜひインストールしてみてください。
# Web APIから取得したユーザー情報からIDのみ取得する例
$ curl https://api.example.com/user | jq .id
1234
SQLフォーマッター
Node.jsで実装されているsql-formatterがシンプルで使い易いと思います。
$ sql-formatter sample.sql
select
post.ID,
post.post_title,
post.post_content,
meta.meta_key,
meta.meta_value
from
wp_posts post
inner join wp_postmeta meta on post.ID = meta.post_id
where
post.ID in (123, 456);
ただ、エディターに整形用のプラグインが公開されている場合はそちらを使用した方がより手軽だと思います。
XMLフォーマッター
Linux環境ならlibxml2-utilsパッケージに含まれるxmllintが使い易いですが、他のOSも含めるならPythonのxml.dom.minidomを使うのが良さそうに思えました。
このようなコードを書いておけば大体のケースで何とかなると思います。
# !/usr/bin/env python3
import argparse
import sys
import xml.dom.minidom
def get_parser():
parser = argparse.ArgumentParser(description='Pretty print XML')
parser.add_argument('FILE', type=argparse.FileType('r'), default=sys.stdin, nargs='?')
parser.add_argument('-i', '--indent', default='\t')
return parser
if __name__ == '__main__':
parser = get_parser()
args = parser.parse_args()
data = args.FILE.read()
dom = xml.dom.minidom.parseString(data)
print(dom.toprettyxml(indent=args.indent), end='')
こちらもSQLと同様に、エディターに整形用のプラグインが公開されている場合はそちらを使用した方がより手軽だと思います。
生成ツール
ハッシュ生成ツール / チェックサム生成
Linuxには各アルゴリズムに対応したコマンドが用意されています。
$ md5sum file.dat # MD5
$ sha1sum file.dat # sha1
$ sha256sum file.dat # sha256
$ sha512sum file.dat # sha512
Macの場合はopensslを利用可能です。
$ openssl md5 file.dat # MD5
$ openssl sha1 file.dat # sha1
$ openssl sha256 file.dat # sha256
$ openssl sha512 file.dat # sha512
UUID生成ツール
uuidgenというコマンドが利用可能です。
UUIDはバージョン1から5までが定義されており、それぞれ値を生成する方法が異なります。DevToysではバージョン1とバージョン4が利用可能です。UUIDのバージョン1は「コンピューターの識別子+生成時刻」、バージョン4は「乱数」を利用して生成されるので、おそらく以下のコマンドに相当するものなのではないかと思います。
# バージョン1
$ uuidgen --time
# バージョン4
$ uuidgen --random
なおuuidgenはオプションを与えない場合、コンピュータが乱数生成機を備えているなら--randomオプションを、そうでないなら--timeオプションを暗黙で指定します。
Lorem Ipsum(ダミーテキスト)生成ツール
普段の業務でダミーテキストを使うことがないのでこういったツールはあまり馴染みがなかったのですが、どうやらLorem Ipsumというツールはあらかじめ決めておいた約200個の文を順に出力するだけのツールのようです。同様のツールを検索したところ多数の実装を見つけられました。
Emmet記法に対応しているエディター(例:VS Code)なら"lorem"と入力してTabを押下すると"Lorem ipsum..."という文字列を出力してくれます。
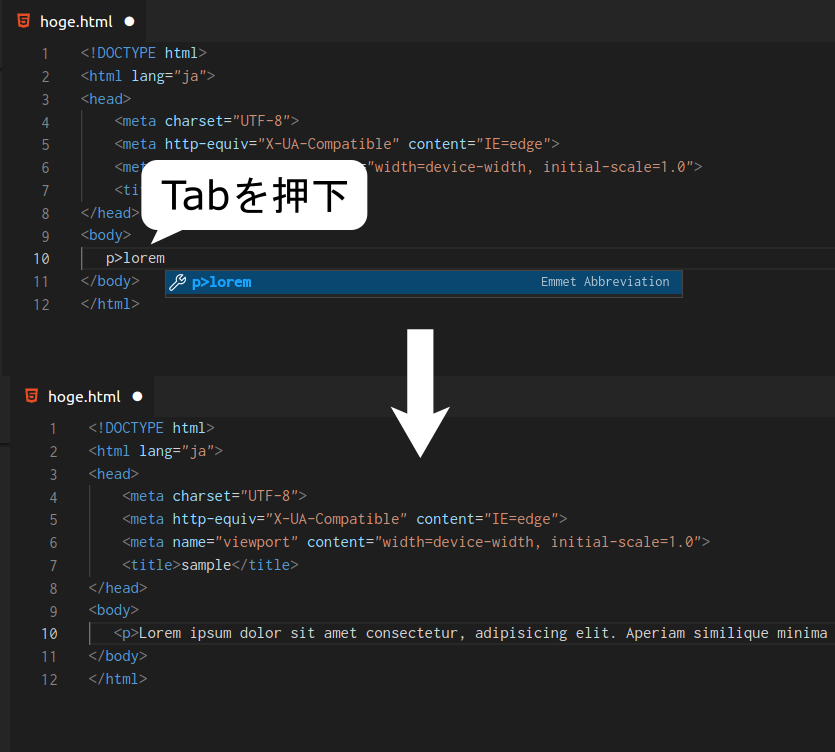
テキスト
文字列の検査と変換
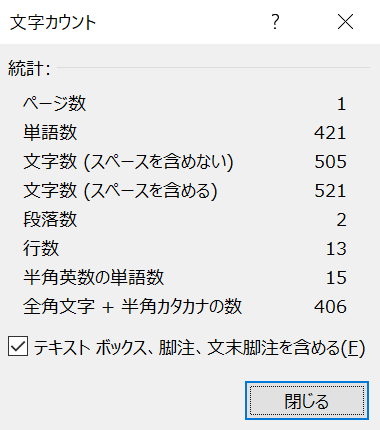
文字数や使用単語をチェックしたいならおそらく文章を書いている時でしょうから、ワープロソフトに実装されている機能を利用した方が手軽です。例えばWordのステータスバーにある"n/N文字"のところをクリックするとこのようなウィンドウが表示されます。
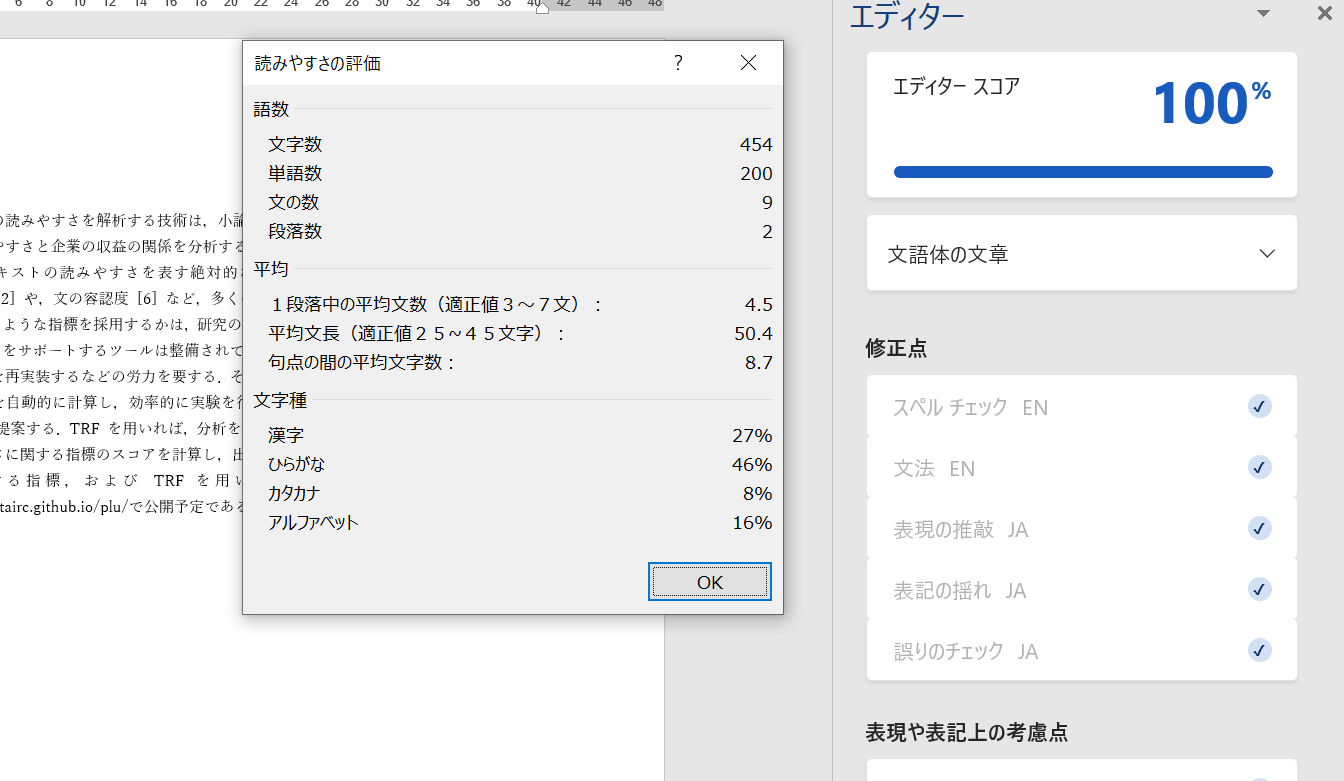
また、Wordには「表記ゆれのチェック」「文章の読みやすさのチェック」「アクセシビリティのチェック」といった機能が実装されており、DevToysから一歩進んだチェックが可能です。
正規表現テスター
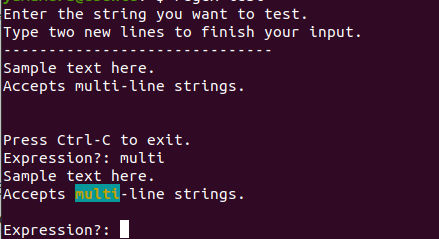
使用しているエディターにプラグインとして実装されている場合があります(例:VS Code)。またちょっとしたコードで自作することも可能です。もしテストしたい正規表現の動作がDevToysのそれと異なるようなら、このようなコードを書く必要があるでしょう。(そうそうそのような状況があるとも思えませんが)
# !/usr/bin/env python3
import argparse
import re
import sys
class Styles:
CLEAR = '\033[0m'
HIT = '\033[1;33;46m'
def please_input():
print('Enter the string you want to test.')
print('Type two new lines to finish your input.')
print('-' * 30)
data = []
newline_count = 0
while newline_count < 2:
try:
user_input = input()
except (KeyboardInterrupt, EOFError):
print('')
sys.exit(0)
if user_input == '':
newline_count += 1
else:
data.extend(['' for _ in range(newline_count)])
newline_count = 0
data.append(user_input)
return '\n'.join(data)
def interactive_test(sample_data, flags):
while True:
try:
matches = re.finditer(input('Expression?: '), sample_data, flags)
i = 0
result = ''
for m in matches:
(start, stop) = m.span()
result += sample_data[i:start]
result += Styles.HIT
result += sample_data[start:stop]
result += Styles.CLEAR
i = stop
result += sample_data[i:]
print(result, end='\n\n')
except (KeyboardInterrupt, EOFError):
print('')
break
def get_parser():
parser = argparse.ArgumentParser(description='Regular expression test tool.')
parser.add_argument('FILE', type=argparse.FileType('r'), nargs='?')
parser.add_argument('-s', '--single-line', action='store_true')
parser.add_argument('-i', '--ignore-case', action='store_true')
return parser
if __name__ == '__main__':
args = get_parser().parse_args()
if args.FILE is None:
sample_data = please_input()
else:
sample_data = args.FILE.read()
flags = 0
if not args.single_line: flags |= re.M
if args.ignore_case: flags |= re.I
print('Press Ctrl-C to exit.')
interactive_test(sample_data, flags)
テキスト比較ツール
Qiitaの読者にいまさら説明は必要ないと思いますが、gitなりdiffコマンドなりを使えば同様のことが可能です。
Markdownプレビュー
エディターにMarkdownのプレビュー機能を追加するプラグインが公開されている場合はそれを利用するのが楽です。例えばVS Codeの場合はこの記事に情報がまとまっているので、参考になると思います。
グラフィック
PNG/JPEG最適化
有名な実装はjpegoptimとoptipngです。どちらもaptなどのパッケージマネージャーからインストールが可能です。また他にもSVGならsvgo、WebPへの変換ならcwebpなど、各画像形式に対応したツールが存在します。
当然、どのツールも複数のファイルに対して一括で最適化を適用することが可能です。
色覚異常シミュレーション
私はデザインをしませんのでこの手のツールに馴染みがないのですが、Color Oracleというツールを使えばPC全体の色を変更することができるようです。Webページのコーディング中に色覚異常のチェックをするならこちらの方が都合がよさそうでした。
またPhotoshopには色覚異常をシミュレートする機能があるようなので、デザイナーの方はこちらを利用したほうがより手軽な上、素早く修正ができると思います。
画像フォーマット変換
ImageMagickを使用すると自由度高く画像の変換が行えます。
ImageMagickでは画像フォーマットの変換の他、画像のリサイズ、画像品質の変更、文字列の挿入などの加工もできます。大体の状況において画像フォーマットを変換したい時というのは複数のファイルを一気に加工したい場合でしょうから、ImageMagickを使えるようになった方が便利なはずです。
ImageMagicで画像形式の変更を行うコマンドは次の通りです。(※ImageMagickをインストールするとconvertコマンドが使えるようになります)
# JPEGからPNGへの変換
$ convert logo.jpg logo.png
# PNGからBMPへの変換
$ convert logo.png logo.bmp
上記を見て頂ければ分かるように、convertコマンドはファイルの拡張子から自動的にファイル形式を推測してくれます。従って任意のディレクトリ配下の画像全てをPNGに統一したい場合のコマンドは次のようになります。
# images配下の画像をすべてPNGに変換してconvertedに出力する
$ for file in `find images -type f`
> do
> filebasename=$(basename ${file%.*})
> filedirname=$(dirname $file)
> newdirname=converted${filedirname#images}
> mkdir -p $newdirname
> convert $file $newdirname/$filebasename.png
> done
上記は"変数展開"という、シェルを書かない人にとっては馴染みのない記法を使っています。
# 変数展開を利用すると簡単な文字列加工ができる
# 上記で使用しているのは${#pattern}と${%pattern}の2つ
$ var=abc,def,ghi
$ echo ${var#*,} # パターンに前方一致(最短)した部分を削除
def,ghi
$ echo ${var%,*} # パターンに後方一致(最短)した部分を削除
abc,def
おわりに
現時点でDevToysに実装されている全機能の代替案は以上です。
私には馴染みのない機能もあったので「いやいや、それはおかしいでしょ」と思われるものもあるかもしれません。もしお気付きの点があれば、コメントで教えて頂けると幸いです。