QiitaではAPIが公開されているので、これを利用して記事をバックアップします。
1. QiitaのAPIを利用する
Qiitaのアクセストークンを取得する
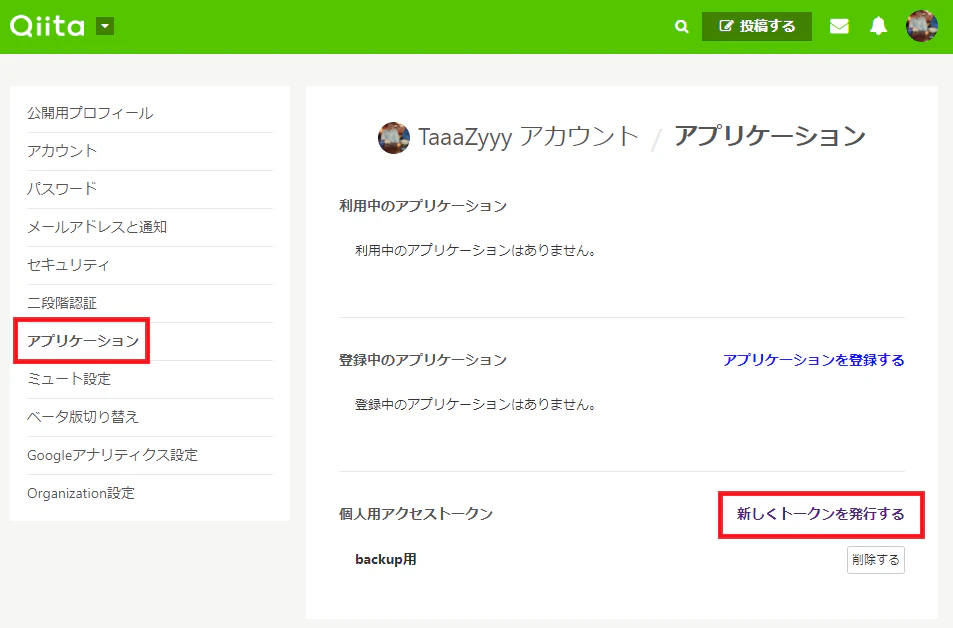
Qiitaにログインした状態で、[設定] - [アプリケーション]にアクセスします。
個人用アクセストークンの「新しくトークンを発行する」をクリックします。
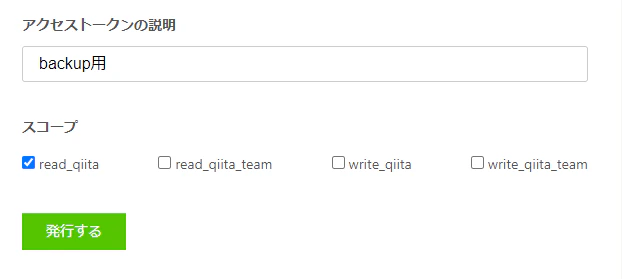
アクセストークンの説明を入力し、read_qiitaにチェックを入れ、「発行する」ボタンをクリックします。
アクセストークンが表示されるので、控えておきます。

APIを使用する
投稿した記事一覧を取得するにはGET /api/v2/authenticated_user/itemsのリソースを使用します。
PostmanなどのAPIクライアントを使用してQiita APIを叩きます。
ヘッダーにAuthorization: Bearer {qiitaで取得したアクセストークン}を追加します。
Bearerとアクセストークンの間に半角スペースが必要です。

下記のようなレスポンスがかえってきます。bodyにマークダウンの本文が設定されています。以下ではこれをPythonで取得するプログラムを作成します。
[
{
"rendered_body": "\n<h2>\n<span id=\"apex-pmdとは\" class=\"fragment\"></span>...",
"body": "## Apex PMDとは\nApex PMDはApexのソースコードを静的解析...",
"coediting": false,
"comments_count": 0,
"created_at": "2021-09-01T00:30:21+09:00",
"group": null,
"id": "d85a93009acefceaf10d",
"likes_count": 2,
"private": false,
"reactions_count": 0,
"tags": [
{
"name": "Salesforce",
"versions": []
},
{
"name": "Apex",
"versions": []
},
],
"title": "[Apex PMD] VSCodeでApexの静的解析を行う",
"updated_at": "2021-09-01T00:30:21+09:00",
"url": "https://qiita.com/TaaaZyyy/items/d85a93009acefceaf10d",
// 略
2. Pythonでバックアップツールを実装する
下記の「FILL_ME_IN」をアクセストークンに置換して実行するとバックアップできます。
qiita_backup_tool.py
#!/usr/bin/python
##########################################################################################
# SECURITY_TOKENにQiitaのアクセストークンを設定してください。
SECURITY_TOKEN = 'FILL_ME_IN'
DIRECTORY_NAME = 'output'
##########################################################################################
import urllib.request
import json
import os
import shutil
from datetime import datetime
from io import BytesIO
# download function
def download_qiita():
print('Qiita記事のバックアップを開始します。')
dir = DIRECTORY_NAME
# バックアップフォルダをリフレッシュ
if os.path.exists(dir):
shutil.rmtree(dir)
os.makedirs(dir)
# 一度に100件までしか取得できないため、ループで処理する
for i in range(100):
# Qiita記事を取得
url = 'https://qiita.com/api/v2/authenticated_user/items'
url += '?page=' + str(i + 1) + '&per_page=100'
headers = {'Authorization' : 'Bearer ' + SECURITY_TOKEN}
req = urllib.request.Request(url, None, headers)
res = urllib.request.urlopen(req)
items = json.load(res)
res.close
if not items:
break
# Qiita記事をマークダウン形式で保存
for item in items:
body = item['body']
private = item['private']
url = item['url']
title = item['title']
tags = item['tags']
created_at = item['created_at']
updated_at = item['updated_at']
# 公開記事と限定公開記事のフォルダを分ける
subDir = dir + '/private' if private else dir + '/public'
if not os.path.exists(subDir):
os.makedirs(subDir)
# マークダウンで保存
file = open(subDir + '/' + create_filename(title, created_at), 'w', encoding='utf-8', newline="\n")
file.write(create_info(title, tags, created_at, updated_at, url) + body)
print('バックアップが完了しました。')
def create_info(title, tags, created_at, updated_at, url):
# ファイルの冒頭にメタデータを追加する
info = '---\n'
info += 'title: ' + title + '\n'
info += 'tags: '
for tag in tags:
info += tag['name'] + ' '
info += '\n'
info += 'created_at: ' + created_at + '\n'
info += 'updated_at: ' + updated_at + '\n'
info += 'url: ' + url + '\n'
info += '---\n'
return info
def create_filename(title, created_at):
# ファイル名に「作成日_タイトル」を使用する
filename_date = format(datetime.strptime(created_at, '%Y-%m-%dT%H:%M:%S%z'), '%Y%m%d')
# ファイル名に使用できない文字列を置換する
filename_title = title.replace('\\', ' ')
filename_title = filename_title.replace('/', ' ')
filename_title = filename_title.replace(':', ' ')
filename_title = filename_title.replace('*', ' ')
filename_title = filename_title.replace('?', ' ')
filename_title = filename_title.replace('"', ' ')
filename_title = filename_title.replace('<', ' ')
filename_title = filename_title.replace('>', ' ')
filename_title = filename_title.replace('|', ' ')
return filename_date + '_' + filename_title + '.md'
download_qiita()
下図のようにバックアップファイルが作成されていきます。

メタデータはファイルの冒頭に追加されます。