メモリアクセスとパイプラインのあれこれ
メモリ周りとパイプラインの話をしていこうかなと。
興味のある方はぜひ!
動作環境
IDE:VitisHLS 2023.1
ソースコード
概要
ここではメモリアクセス = BRAMへのアクセスと定義します。
今回は例として以下の構成を想定します。
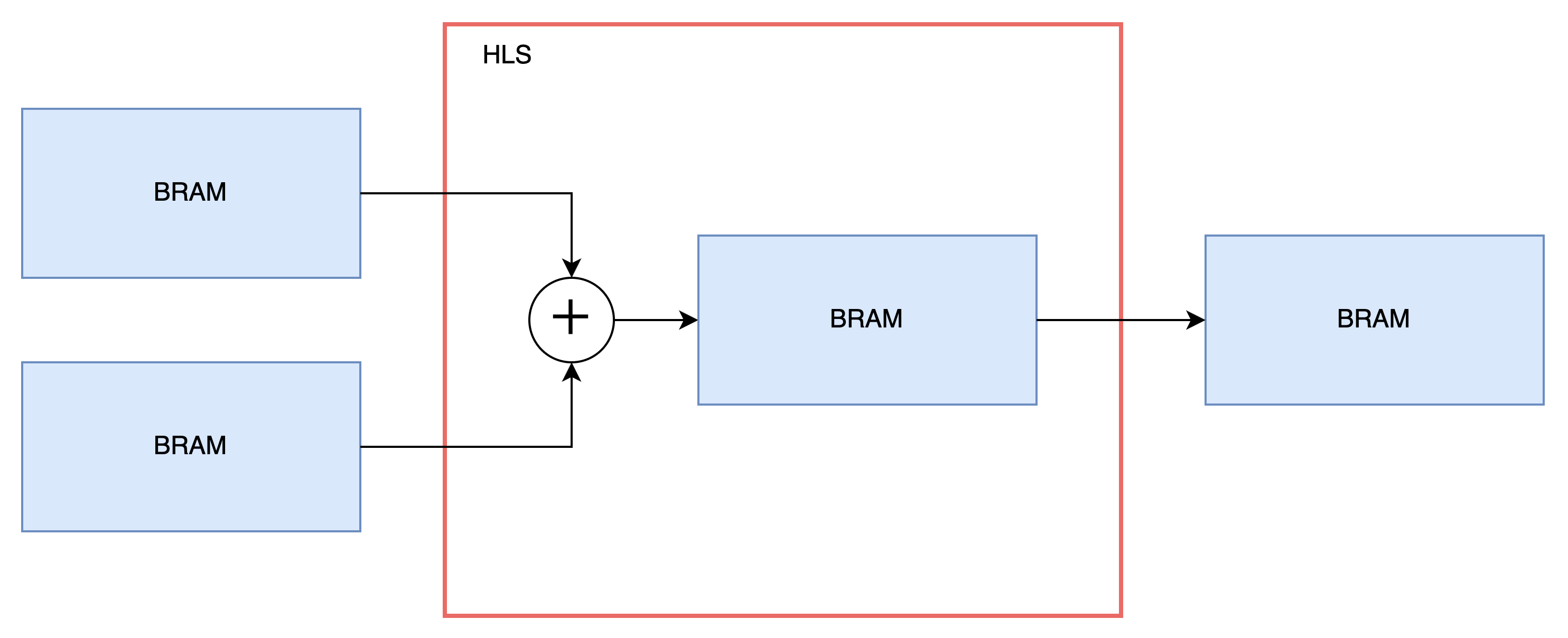
外部のBRAMからデータを引き抜いて、加算し、内部のBRAMへ保存。
その後、内部のBRAMからデータを引き抜いて、外部のBRAMへ保存。
HLSの中身をも少し詳しく書くと以下になります。
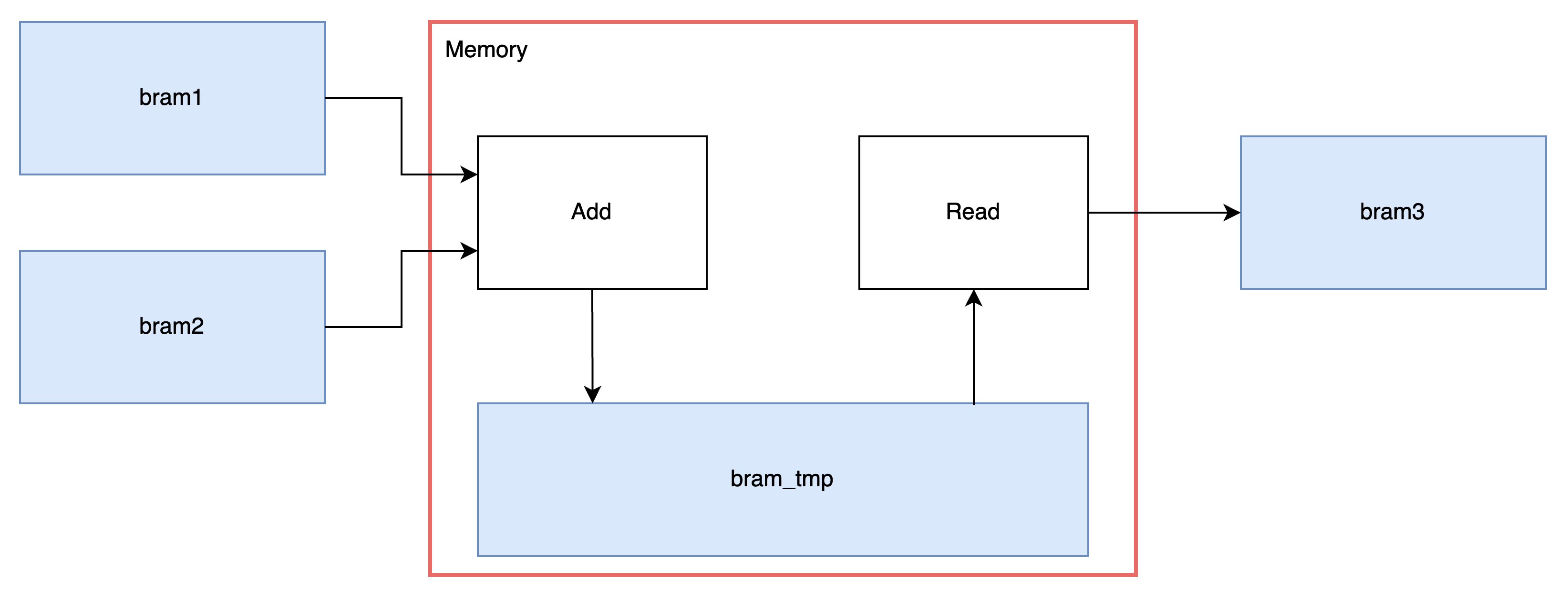
以下の順番で説明します。
- Memoryモジュール:TOP階層
- Addモジュール:加算処理
- Readモジュール:内部データを外部データへ転送処理
Memoryモジュール
ソースコード
void Memory(int bram1[BRAM_SIZE], int bram2[BRAM_SIZE], int bram3[BRAM_SIZE])
{
#pragma HLS INTERFACE ap_memory port = bram1
#pragma HLS INTERFACE ap_memory port = bram2
#pragma HLS INTERFACE ap_memory port = bram3
#pragma HLS INTERFACE ap_none port = return
int bram_tmp[BRAM_SIZE];
#pragma HLS BIND_STORAGE variable = bram_tmp type = RAM_S2P impl = BRAM
Add(bram1, bram2, bram_tmp);
Read(bram_tmp, bram3);
}
解説
- メモリからのアクセスになるため引数は配列になります。
データの信号だけで、アドレスや制御信号はいらないの?と思うかもしれませんが、それはツールが上手いことやってくれます。
その上手いことやってくれる定義がプラグマのap_memoryになります。
これを書くことによって、指定した変数がメモリアクセスの信号だということをツールに教えます。 - 内部のBRAMの定義については配列で宣言します。その後のプラグマが大事になります。
BIND_STORAGEとは指定した変数を、どのメモリタイプに割り当てるかを指定するプラグマになります。
variable:変数を指定
type:メモリのタイプを指定

impl:メモリをなにで実現するかを指定

※プラグマ指定をしなくても使えますが、実現方法はツール任せになります。
引数が配列ならポインタ引数にしないのはなぜか?
C言語をかじったことがある方ならこう思ったことかと。
結論を先に言うと、この書き方はダメなんです。
正確に言うとTOPモジュールのIF部分ではダメになります。
なぜかと言うと理由は単純で、メモリのサイズがわからないからです。
メモリサイズがわからない = アドレス幅がわからない
なので、TOPモジュールのIFでは使えないんですよね。
一方、内部の場合はメモリサイズがわかっているので使用できるんですよね。
Addモジュール
ソースコード
void Add(int *bram1, int *bram2, int *bram_tmp)
{
Add:
for (int i = 0; i < BRAM_SIZE; i++)
{
#pragma HLS PIPELINE II = 1
bram_tmp[i] = bram1[i] + bram2[i];
}
}
解説
- 先ほどのTOPモジュール同様にBRAMとのやりとりをするので配列を引数とします。
ここでは内部/外部のBRAMのサイズがわかっているので、ポインタ引数で定義しています。 - BRAM = 配列 なので、アクセスの方法はC言語と同じ方法でアクセスできます。
- for文の前に
Add:と記載していますが、これはラベルといいます。
意味としては、ループ処理に名前をつけると思ってもらえればいいです。
なぜループ処理に名前をつけるのか?は後で説明します。 -
PIPELINEプラグマとは何か?についても後で説明します。
Readモジュール
ソースコード
void Read(int *bram_tmp, int *bram3)
{
Read:
for (int i = 0; i < BRAM_SIZE; i++)
{
#pragma HLS PIPELINE II = 1
bram3[i] = bram_tmp[i];
}
}
解説
- 先ほどのAddモジュールとほぼ同じなので追加の説明は特になしです。
合成結果
IF結果
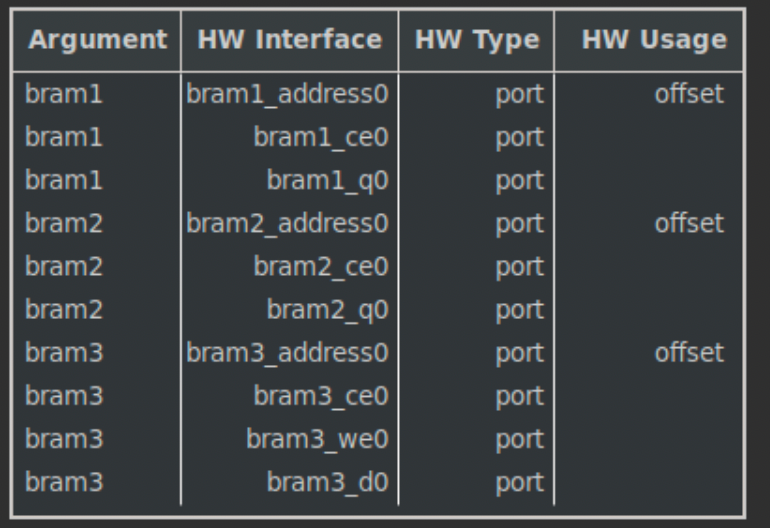
ap_memoryプラグマを定義したことにより、IFもきちんと定義されていますね。
合成結果

上記の合成結果を見るときちんと合成されていますね。
先ほどループに名前をつけたのはここで確認するためです。AddやReadが確認できますよね。
で、ここに表示されてなにが嬉しいの?と思うかもしれませんが、解析する時に一目でどのループ処理かを判別できます。
今回はループ処理が少ないので特に旨味はないですが、業務で使う場合だともっと数が増えるので、どれがどのループ処理なのかを判断するのが難しくなります。
ちなみに名前をつけないとツール側が意味のわからん名前を勝手に割り振ってきます。
では、合成結果の見方をざっくり説明しますね。
項目を大きく分けると「処理関連」と「リソース関連」の見方ができます。
処理関連
項目だとSlack〜Pipelinedまで。
以下の項目が特に大事になってきますので説明しますね。
| 項目 | 説明 |
|---|---|
| Latency | 入力してから全ての出力結果が出るまでの時間 |
| Iteration Latency | 1回の処理時間 |
| Interval(II) | 次の入力を開始できるまでの時間 |
文字だけで説明しても微妙にイメージが湧きにくいと思いますので、Addモジュールを例に説明しますね。
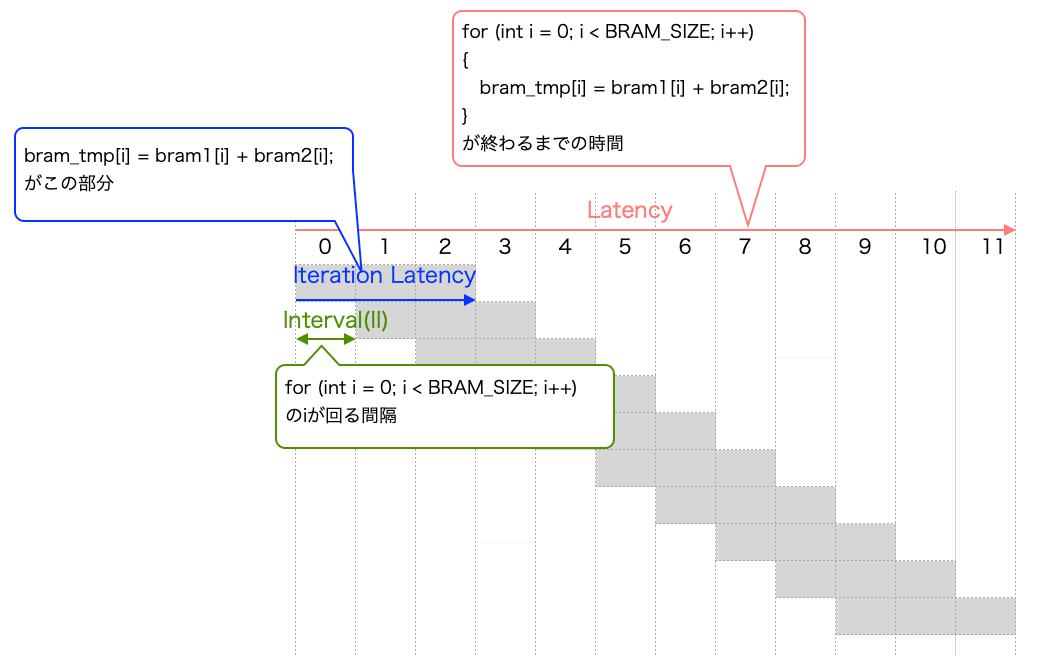
上記のような動作をパイプライン動作といいます。
高位合成において効率良く動作させるにはこのパイプライン動作が鍵を握っています。
パイプライン動作をするためにはIIが重要になってきます。
今回は II = 1 で毎クロック入力を受け付けることができるため、パイプライン動作が実現できています。
そしてパイプライン動作を指示するためのプラグマというのが、PIPELINE II = xxになります。
xx にはII間隔を指定します。
ちなみに、書かなくてもパイプライン動作にしてくれますが、明示的に書いた方がいいです。
逆にパイプライン動作をしたくない場合はPIPLELINE offと記載します。
処理が複雑でII間隔がわからないのでとりあえず大きめに書いておくのはアリか?
答えはナシかなと思います。
例えば II = 1 で問題ないけど、II = 100 と書くとどうなるのかですが、
この場合は II = Iteration Latency で動作します。今回だと II = 3 ということですね。
なので、IIをIteration Latencyより大きい値にするとIteration Latency時間で動作します。
それ以上の最適化はしてくれませんのでご注意を。
ではどのように決めたらいいのかですが、とりあえず II = 1で合成してみる。そしてタイミングがメットしないようであれば、「II間隔を大きくする」or 「間に合わせるよに処理を工夫する」の選択になるかなと思います。
ここはシステムによるので臨機応変に対応しましょう。
リソース関連
項目だとBRAM〜URAMまで。
ここは特に説明しなくてもイメージはつきやすいかと思います。
それぞれのリソース量を表示しています。
今回だと、BRAMを内部で1つ使用しているため1となっています。
シミュレーション結果
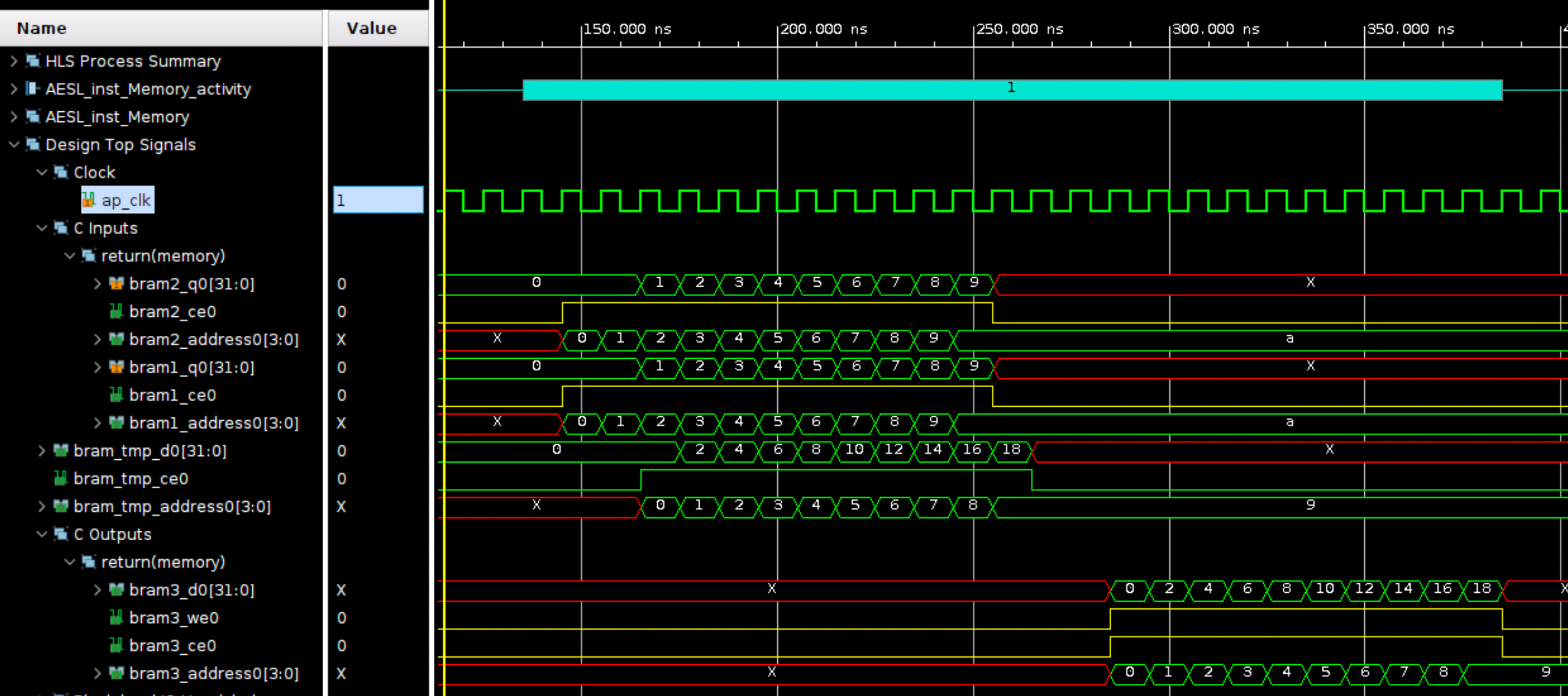
期待通りの結果になっていますね。
ちなみに先ほどの II = 100 にした場合のシミュレーション波形は以下です。
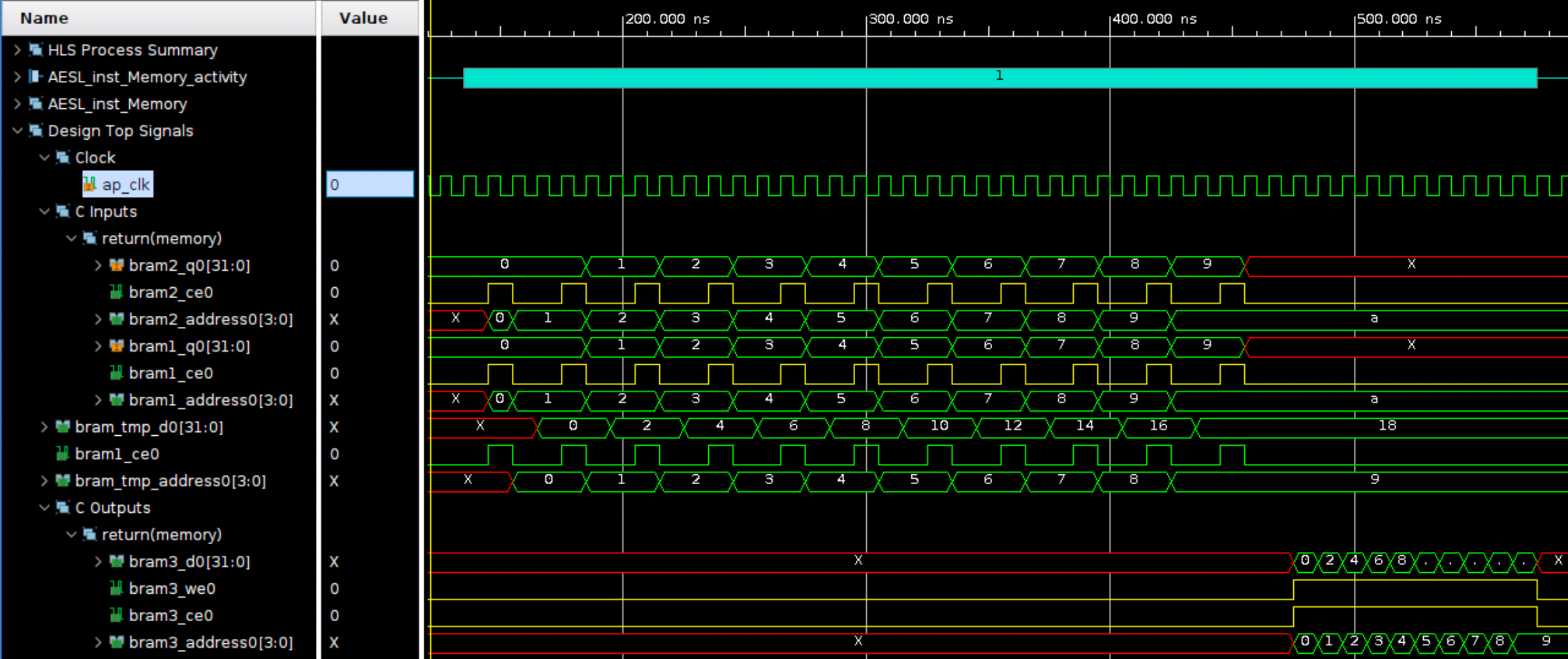
今回は以上。