AMDで動く各種深層学習モデルのバックエンドはHIP-Tensorflow(hip-MIOpen)だけではなくPlaidMlでもOpenCLで実装されているのでMacなどでも動くバックエンドとなっており、ここではこの部分も測定してみたいと思います。
環境
CPU Xeon E5-2603 v4
MB msi-x99 Gaming7
RAM DDR4-2400 32GB
GPU0 NVIDIA GTX1080Ti (グラフィック表示用兼CUDA用)
GPU1 AMD Vega20 RadeonⅦ
OS Ubuntu16.04.6 LST kernel version 4.15
GPU1については必要に応じて変更してます
AMDドライバーに関してはROCm2.4を使用しROCm OpenCLを使用して動かします
nvidiaドライバに関しては Driver Version: 418.67 CUDA Version: 10.1 となっています。
環境構築
http://blog.gpueater.com/ja/2018/03/13/00004_tech_plaidml/
環境構築はほぼこのままでやりました
相違点としてはminicondaを使用している点です。
$ conda create -n ml python=3.6
$ conda activate ml
$ pip install -U plaidml-keras h5py
$ plaidml-setup
PlaidML Setup (0.6.0)
Thanks for using PlaidML!
Some Notes:
* Bugs and other issues: https://github.com/plaidml/plaidml
* Questions: https://stackoverflow.com/questions/tagged/plaidml
* Say hello: https://groups.google.com/forum/#!forum/plaidml-dev
* PlaidML is licensed under the Apache License 2.0
Default Config Devices:
opencl_nvidia_geforce_gtx_1080_ti.0 : NVIDIA Corporation GeForce GTX 1080 Ti (OpenCL)
Experimental Config Devices:
llvm_cpu.0 : CPU (LLVM)
opencl_nvidia_geforce_gtx_1080_ti.0 : NVIDIA Corporation GeForce GTX 1080 Ti (OpenCL)
opencl_amd_gfx803.0 : Advanced Micro Devices, Inc. gfx803 (OpenCL)
Using experimental devices can cause poor performance, crashes, and other nastiness.
Enable experimental device support? (y,n)[n]:y
Multiple devices detected (You can override by setting PLAIDML_DEVICE_IDS).
Please choose a default device:
1 : llvm_cpu.0
2 : opencl_nvidia_geforce_gtx_1080_ti.0
3 : opencl_amd_gfx803.0
Default device? (1,2,3)[1]:1
Selected device:
llvm_cpu.0
Almost done. Multiplying some matrices...
Tile code:
function (B[X,Z], C[Z,Y]) -> (A) { A[x,y : X,Y] = +(B[x,z] * C[z,y]); }
Whew. That worked.
Save settings to /home/rocm2/.plaidml? (y,n)[y]:y
Success!
plaidml-setupコマンドが使えるようになるので使用GPUなどを設定します、GPUを切り替えたい場合は再度plaid-mlコマンドでGPUを切り替えればよいです。
VGG19テスト
#!/usr/bin/env python
import numpy as np
import os
import time
os.environ["KERAS_BACKEND"] = "plaidml.keras.backend"
import keras
import keras.applications as kapp
from keras.datasets import cifar10
(x_train, y_train_cats), (x_test, y_test_cats) = cifar10.load_data()
batch_size = 8
x_train = x_train[:batch_size]
x_train = np.repeat(np.repeat(x_train, 7, axis=1), 7, axis=2)
model = kapp.VGG19()
model.compile(optimizer='sgd', loss='categorical_crossentropy',
metrics=['accuracy'])
print("Running initial batch (compiling tile program)")
y = model.predict(x=x_train, batch_size=batch_size)
# Now start the clock and run 10 batches
print("Timing inference...")
start = time.time()
for i in range(10):
y = model.predict(x=x_train, batch_size=batch_size)
print("Ran in {} seconds".format(time.time() - start))
これは公式リポジトリにもあるテスト用のコードになります。
VGG19での実行時間は以下のような感じになります
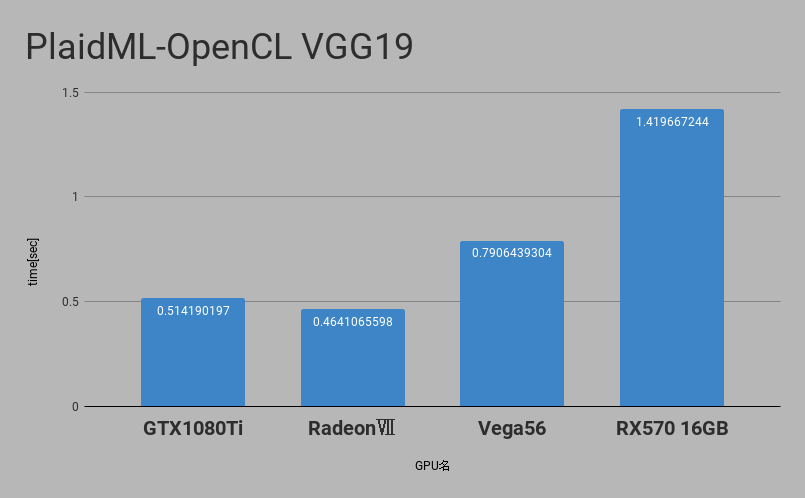
最速では比較用にNVIDIA GTX1080Tiも居ますがRadeonⅦでもそこそこの性能が確保されていることがわかります。
ベンチマーク plaidbench(resnet50)
次にplaidbenchを取ります
https://github.com/plaidml/plaidbench
git clone https://github.com/plaidml/plaidbench.git
cd ./plaidbench/
pip install onnx-plaidml
resnet50モデルを動かしてみたいと思います。
python plaidbench.py --result ~/shuffle_results --onnx --batch-size 32 --plaid resnet50
vega56の場合はこのように出力されます
Compiling network...INFO:plaidml:Opening device "opencl_amd_gfx900.0"
Warming up... Running...
Example finished, elapsed: 22.385s (compile), 0.754s (execution)
-----------------------------------------------------------------------------------------
Network Name Inference Latency Time / FPS
-----------------------------------------------------------------------------------------
resnet50 0.74 ms 0.52 ms / 1915.03 fps
RX570
Compiling network...INFO:plaidml:Opening device "opencl_amd_gfx803.0"
Warming up... Running...
Example finished, elapsed: 22.936s (compile), 1.033s (execution)
-----------------------------------------------------------------------------------------
Network Name Inference Latency Time / FPS
-----------------------------------------------------------------------------------------
resnet50 1.01 ms 0.72 ms / 1394.67 fps
RadeonⅦ
Running 1024 examples with resnet50, batch size 32, on backend BackendInfo(name='plaid', module_name='onnx_plaidml.backend', gpu_device=None, is_plaidml=True, requirements=['onnx-plaidml'])
Compiling network...INFO:plaidml:Opening device "opencl_amd_gfx906+sram-ecc.0"
INFO:plaidml:Analyzing Ops: 753 of 917 operations complete
Warming up... Running...
Example finished, elapsed: 22.277s (compile), 0.740s (execution)
-----------------------------------------------------------------------------------------
Network Name Inference Latency Time / FPS
-----------------------------------------------------------------------------------------
resnet50 0.72 ms 0.44 ms / 2275.58 fps
Correctness: PASS, max_error: 2.5339340936625376e-06, max_abs_error: 1.0803341865539551e-07, fail_ratio: 0.0
GTX1080Ti
Running 1024 examples with resnet50, batch size 32, on backend BackendInfo(name='plaid', module_name='onnx_plaidml.backend', gpu_device=None, is_plaidml=True, requirements=['onnx-plaidml'])
Compiling network...INFO:plaidml:Opening device "opencl_nvidia_geforce_gtx_1080_ti.0"
INFO:plaidml:Analyzing Ops: 908 of 917 operations complete
Warming up... Running...
Example finished, elapsed: 12.546s (compile), 0.755s (execution)
-----------------------------------------------------------------------------------------
Network Name Inference Latency Time / FPS
-----------------------------------------------------------------------------------------
resnet50 0.74 ms 0.28 ms / 3630.77 fps
結果
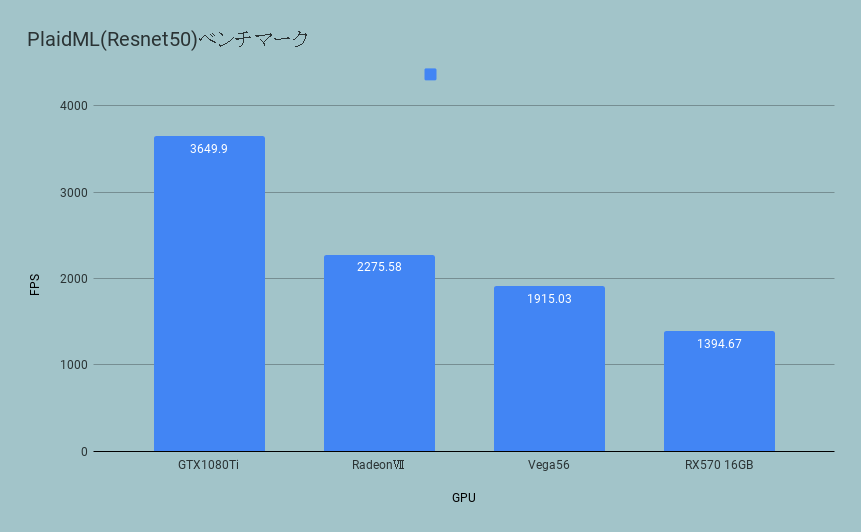
なぜかvgg19に比べてResnet50ではGTX1080Tiが圧倒的に速いと言う結果になってしまいました。
まだVega20は最適化の余地があるのかもしれません。