Docker pullからBuildまで
https://qiita.com/T_keigo_wwk/items/1a525768ad7585bda34f
Pytorch-ROCm DockerでPytorch-ROCmをビルドしてみる(ROCm2.4編)
Dockerコンテナを立ち上げる一連の流れはここを参照してください。
作業は主にコンテナでマウントした/dataディレクトリで行います。
python環境は前述の記事にありますがminicondaで構築し、py37で当方で動作確認を行いました。
環境
ホストOS Ubuntu16.04.06
ホストマシン ROCm version ROCm2.5.27
GPU RadeonⅦ
FastSpeechのダウンロード
ここから先はコンテナ内部での作業がメインになります。
必要なpythonパッケージをpip installしたり解凍したりする
pip install tqdm
pip install librosa
pip install inflect
pip install matplotlib
pip install unidecode
pip install pillow
apt install unzip
unzip ./alignment_targets.zip
cd /data
git clone https://github.com/xcmyz/FastSpeech.git
cd ./FastSpeech/data
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xf ./LJSpeech-1.1.tar.bz2
FastSpeechのgit cloneからデーターセットのダウンロードまでです
データーセットはそれなりにサイズが大きいので太い回線を用意してください。
train.pyが走るまで
データーの前処理をします。
cd ../
python ./preprocess.py
mkdir Tacotron2/pre_trained_model/
少し時間がかかるので待ちます。
数分~10分程度です。
Tacotron2/pre_trained_model/は後で使うディレクトリなので作っておきます。
こんな結果がアウトプットされればOK
Wrote 13100 utterances, 6911588 frames (24.00 hours)
Max input length: 187
Max output length: 810
次に Tacotron2 modelをダウンロードしますがwgetコマンドでうまく行かなかったのでホストマシン側からダウンロードして
ホストマシンの~/data/FastSpeech/Tacotron2に
https://drive.google.com/a/salesio-sp.ac.jp/uc?export=download&confirm=XAHL&id=1c5ZTuT7J08wLUoVZ2KkUs_VdZuJ86ZqA
上記のURLからpre_trained_modelを解凍してコピーしてください。
コマンド上でやるならホストマシンの端末に戻って
cd ~/Download
sudo cp ./tacotron2_statedict.pt ../data/FastSpeech/Tacotron2/pre_trained_model
こんな感じのコマンドでコピーすると良いと思います。
またコンテナ側の端末に戻ってbatch_sizeを弄ります。
なぜ弄るかと言うと初期設定ではbatch_size=64ですがこれではVRAM16GBでは足りず、コンシューマー向けGPUでは最高クラスのVRAMが乗っているRadeonⅦですらメモリ不足でエラーになってしまうのでこれをbatch sizeを32にします。
hparams.pyの39行目にbatch_size = 64があると思うのでこれを修正して32にします
8GBぐらいのVRAMしかない場合はもっと小さい値にしないと動かないかもしれません、
python ./train.py
これで一応学習が開始されます。
https://arxiv.org/abs/1905.09263
FastSpeechはテキスト読み上げを合成音声をするための
動作チェック
warning: <unknown>:0:0: loop not unrolled: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering
warning: <unknown>:0:0: loop not unrolled: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering
こんな感じでループ展開がうまく言ってない旨のwarnigが出ますが一応動きます。
48時間ぐらい回したらloss=nanになってしまいました・・・
Epoch [73/10000], Step [29580/4090000], Mel Loss: nan, Mel PostNet Loss: nan;
Duration Predictor Loss: nan, Total Loss: nan.
Current Learning Rate is 0.000297.
Time Used: 122397.563s, Estimated Time Remaining: 16473894.178s.
どうやら430stepでnanになってしまったようです
Epoch [2/10000], Step [420/4090000], Mel Loss: 0.1314, Mel PostNet Loss: 0.8466;
Duration Predictor Loss: 0.1173, Total Loss: 1.0953.
Current Learning Rate is 0.000085.
Time Used: 2240.385s, Estimated Time Remaining: 16827231.119s.
Epoch [2/10000], Step [430/4090000], Mel Loss: nan, Mel PostNet Loss: nan;
Duration Predictor Loss: nan, Total Loss: nan.
Current Learning Rate is 0.000087.
Time Used: 2280.694s, Estimated Time Remaining: 16532341.754s.
hparas.pyの40行目epochs = 10000をepoch=3```に変更して回してみます。
またSave Pointも細かく500stepごとにしました。
# Train
pre_target = True
n_warm_up_step = 4000
learning_rate = 1e-3
batch_size = 32
epochs = 3
dataset_path = "dataset"
logger_path = "logger"
alignment_target_path = "./alignment_targets"
waveglow_path = "./model_waveglow"
checkpoint_path = "./model_new"
grad_clip_thresh = 1.0
decay_step = [200000, 500000, 1000000]
save_step = 500
log_step = 10
clear_Time = 20
1200stepまで回したのもloss=nanにならなかったので今回の現象は再現性がなさそうです。
ひとまずリザルトを吐いてみます、syntheis.pyは結果にnanがあると途中で落ちるので取得するセーブポイントを指定するかしてやる必要があります(あってはだめなことですが)
python ./synthesis.py
Model Have Been Loaded.
Wav Have Been Synthesized.
Wav Have Been Synthesized.
Wav Have Been Synthesized.
Synthesized.
./imgに model_test.jpgが吐かれるはずです。
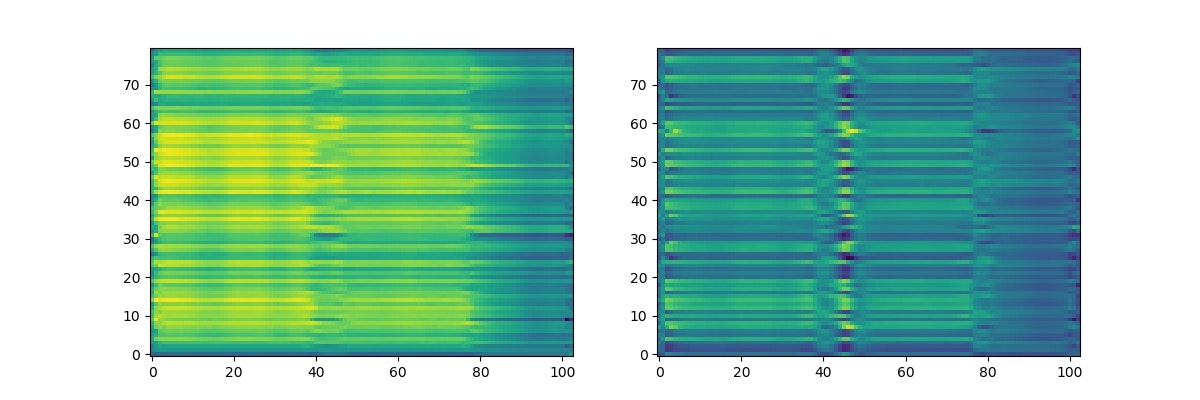
図1.1 model_test.jpg
音声も/FastSpeech/resultsにI am very happy to see you again.normal.wav I am very happy to see you again.quick.wav I am very happy to see you again.slow.wav の3種類が出力されます。
実際聞いてみましたがとてもI am very happy to see you ageinには聞こえませんでした.
もっとステップを増やして学習する必要がありそうです。