https://github.com/keithito/tacotron
TensorFlowでのTacotron音声合成の実装です。
cudaとrocmでtrainの動作テストをしたのですが色々あったので今後再現性を確保するためのメモとして残します
環境を揃える
python仮想環境はminicondaを使用
ROCm versionは2.7
CUDA versionはV10.1.243 (Driver Version: 430.26 )
GPUはRadeonⅦとGTX1080TI
git clone https://github.com/keithito/tacotron
requirements.txt にかかれているバージョンが古いみたいなので若干修正
falcon
inflect
librosa
matplotlib
numpy
scipy
tqdm
Unidecode
データーセットの用意と下処理
LJ Speechデーターセットを今回は使用
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xf ./ LJSpeech-1.1.tar.bz2
python preprocess.py --dataset ljspeech
rocmでの環境構築と動作
sudo apt update
pip install tensorflow-rocm==1.14.1
sudo apt-get update && sudo apt-get install -y --allow-unauthenticated rocm-dkms rocm-dev rocm-libs rocm-device-libs hsa-ext-rocr-dev hsakmt-roct-dev hsa-rocr-dev rocm-opencl rocm-opencl-dev rocm-utils rocm-profiler cxlactivitylogger miopen-hip miopengemm
pip install -r ./requirements.txt
どうもrocm1.13.1では動かず1.14.1でテストを行った。
実行したところRadeonⅦの16GB RAMがほとんど使われてしまい学習もCPUより遅くなるという事態になってしまいました・・・

Step 1 [169.216 sec/step, loss=0.94706, avg_loss=0.94706]
NVIDIA-CUDAでの環境構築と動作テスト
nvidia用環境構築
conda create -n cuda python=3.6
pip install tensorflow-gpu==1.14.0
pip install -r requirements.txt
注意
CUDA10.1ではGPUが無視されて動かないのでCUDA10.0環境を構築する or Docker環境を立てるのが無難です
sudo docker pull tensorflow/tensorflow:1.14.0-gpu-py3
sudo docker run --runtime=nvidia --rm -it tensorflow/tensorflow:1.14.0-gpu-py3
コンテナ内ではpip3で既にtf1.14.0が動いているはずなので適時置き換えて使えば動きます。
https://hub.docker.com/r/tensorflow/tensorflow/tags?page=1&name=1.14.0
tf1.14.0コンテナを立てるのが無難かもしれません。
なんかsound関連でエラーが出たらここらへんが参考になる
http://www.codemarvels.com/2017/09/sndfile-not-found-error-while-installing-scikits-audiolabs/
https://improve-future.com/python-caution-on-scikits-audiolab-installation.html
動作テスト
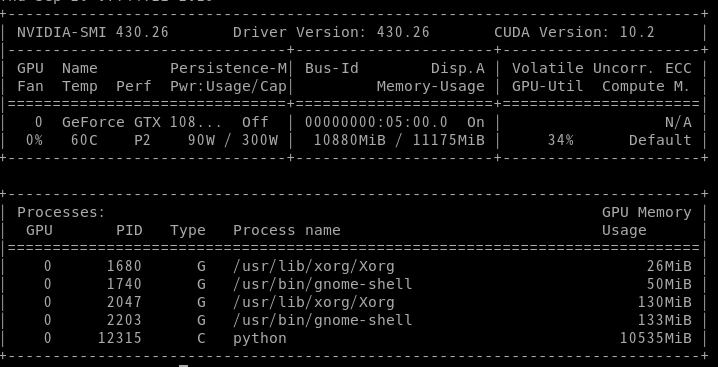
それなりに10GBほどVRAMを消費します
プロファイリング
train.pyのdef trainを下記のように書き換えると任意のstepでtimeline.jsonが出力されます
def train(log_dir, args):
commit = get_git_commit() if args.git else 'None'
checkpoint_path = os.path.join(log_dir, 'model.ckpt')
input_path = os.path.join(args.base_dir, args.input)
log('Checkpoint path: %s' % checkpoint_path)
log('Loading training data from: %s' % input_path)
log('Using model: %s' % args.model)
log(hparams_debug_string())
# Set up DataFeeder:
coord = tf.train.Coordinator()
with tf.variable_scope('datafeeder') as scope:
feeder = DataFeeder(coord, input_path, hparams)
# Set up model:
global_step = tf.Variable(0, name='global_step', trainable=False)
with tf.variable_scope('model') as scope:
model = create_model(args.model, hparams)
model.initialize(feeder.inputs, feeder.input_lengths, feeder.mel_targets, feeder.linear_targets)
model.add_loss()
model.add_optimizer(global_step)
stats = add_stats(model)
# Bookkeeping:
step = 0
time_window = ValueWindow(100)
loss_window = ValueWindow(100)
saver = tf.train.Saver(max_to_keep=5, keep_checkpoint_every_n_hours=2)
# Train!
with tf.Session() as sess:
try:
summary_writer = tf.summary.FileWriter(log_dir, sess.graph)
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
#プロファイル
sess.run(tf.global_variables_initializer())
count = 0
if args.restore_step:
# Restore from a checkpoint if the user requested it.
restore_path = '%s-%d' % (checkpoint_path, args.restore_step)
saver.restore(sess, restore_path)
log('Resuming from checkpoint: %s at commit: %s' % (restore_path, commit), slack=True)
else:
log('Starting new training run at commit: %s' % commit, slack=True)
feeder.start_in_session(sess)
while not coord.should_stop():
start_time = time.time()
step, loss, opt = sess.run([global_step, model.loss, model.optimize],
options=run_options,
run_metadata=run_metadata)
time_window.append(time.time() - start_time)
loss_window.append(loss)
message = 'Step %-7d [%.03f sec/step, loss=%.05f, avg_loss=%.05f]' % (
step, time_window.average, loss, loss_window.average)
log(message, slack=(step % args.checkpoint_interval == 0))
count = count + 1
step_stats=run_metadata.step_stats
tl = timeline.Timeline(step_stats)
ctf = tl.generate_chrome_trace_format(show_memory=False,
show_dataflow=True)
with open("timeline.json", "w") as f:
f.write(ctf)
if loss > 100 or math.isnan(loss):
log('Loss exploded to %.05f at step %d!' % (loss, step), slack=True)
raise Exception('Loss Exploded')
if step % args.summary_interval == 0:
log('Writing summary at step: %d' % step)
summary_writer.add_summary(sess.run(stats), step)
if step % args.checkpoint_interval == 0:
log('Saving checkpoint to: %s-%d' % (checkpoint_path, step))
saver.save(sess, checkpoint_path, global_step=step)
log('Saving audio and alignment...')
input_seq, spectrogram, alignment = sess.run([
model.inputs[0], model.linear_outputs[0], model.alignments[0]])
waveform = audio.inv_spectrogram(spectrogram.T)
audio.save_wav(waveform, os.path.join(log_dir, 'step-%d-audio.wav' % step))
plot.plot_alignment(alignment, os.path.join(log_dir, 'step-%d-align.png' % step),
info='%s, %s, %s, step=%d, loss=%.5f' % (args.model, commit, time_string(), step, loss))
log('Input: %s' % sequence_to_text(input_seq))
except Exception as e:
log('Exiting due to exception: %s' % e, slack=True)
traceback.print_exc()
coord.request_stop(e)
chrome://tracing/
ここから.jsonを開けます
ROCmの分析
1step 50~100秒かかっていただけあって.jsonもすごいサイズになってしまっています.
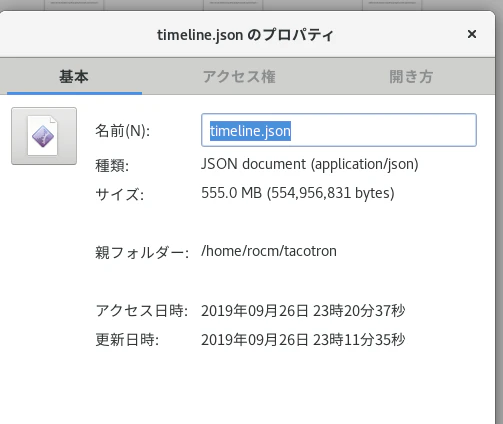
これをクロームで開こうとしたらブラウザが固まってしまいました.
補足
1step目だと時間がかかりすぎるので3stepぐらいだと読み込みが出来ました
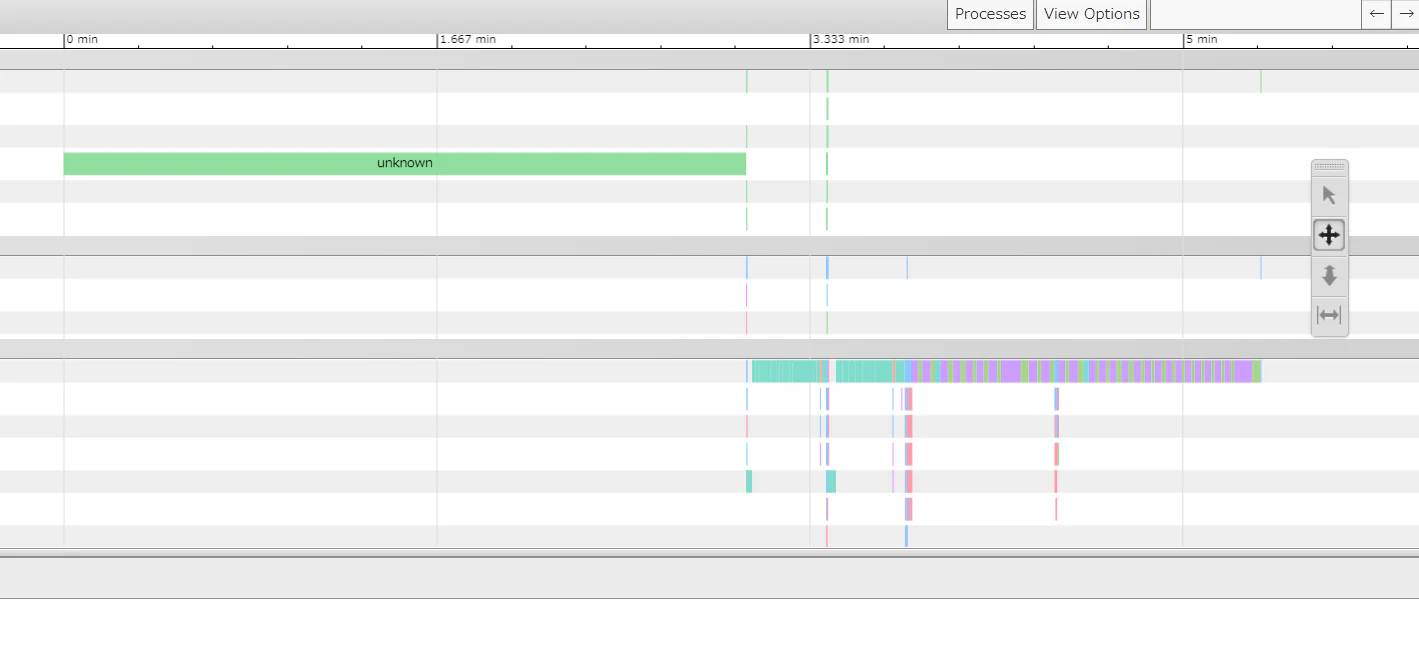
結構unknownが占めていて原因がわからなかったのが残念です.
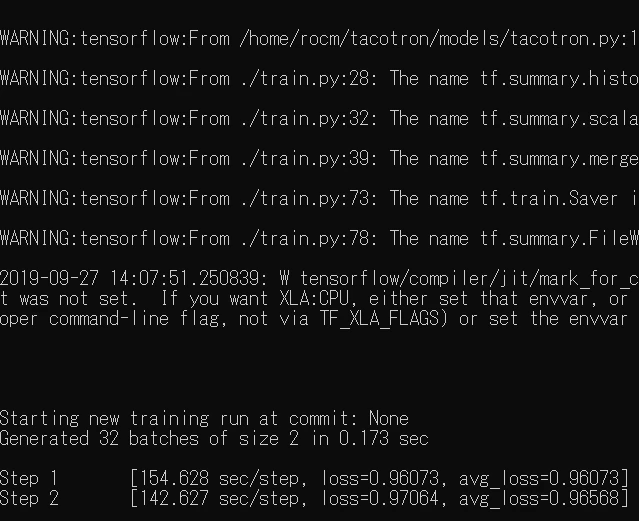
CUDAの分析
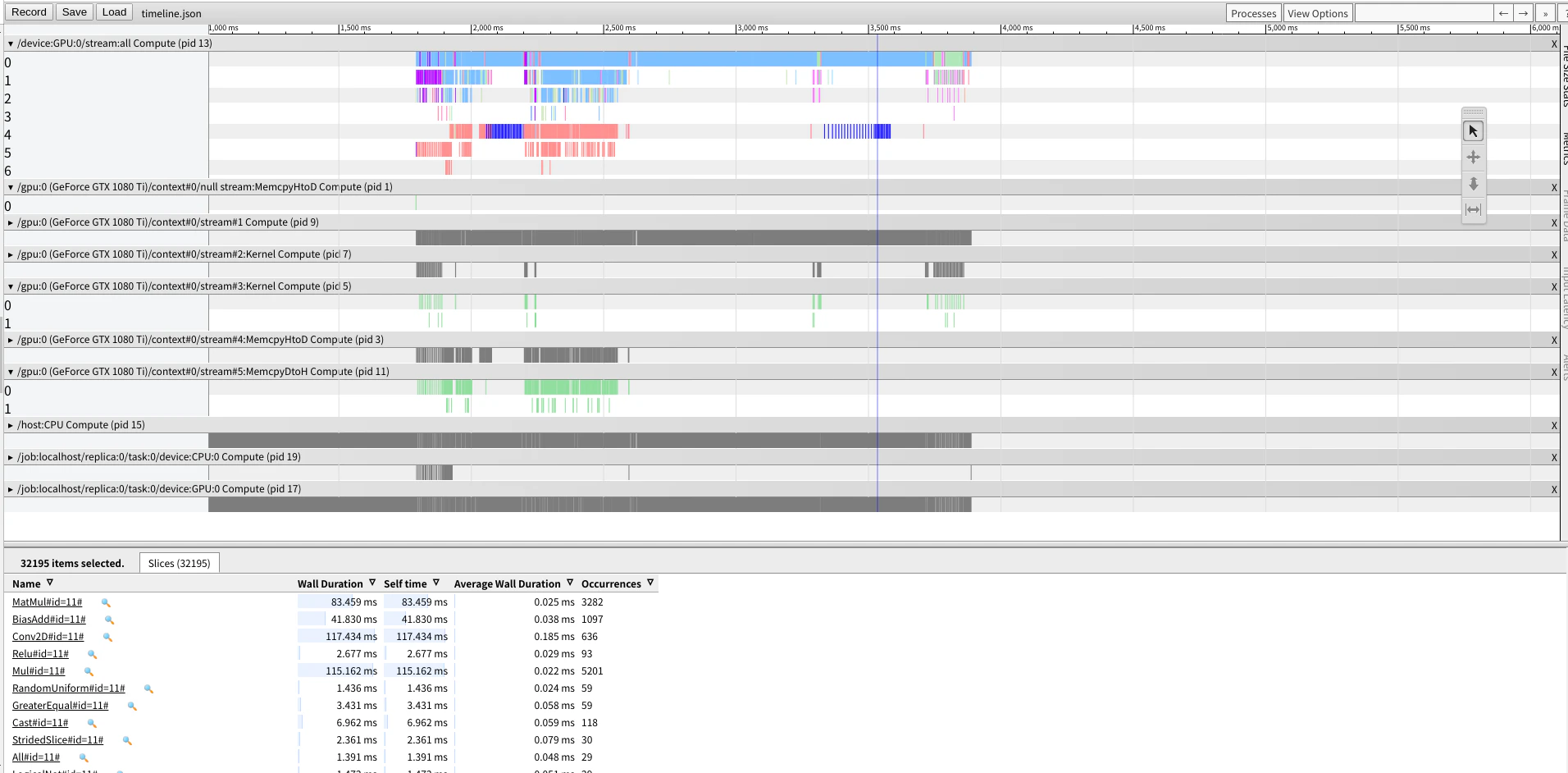
1step 10s~18sぐらいでステップが進みました。
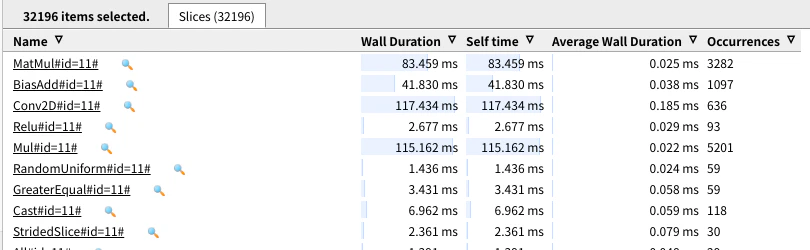
分析した感じではNatMulが普通に一番時間を消費してしたのでCUDAでは計算ワークが正常に行われていたものと思われます
ROCmについては明らかに実用域では動いてないのでtacotronではCUDAを使うのが無難でしょう.
参考