はじめに
僕は普段アニメ見ないんですが、暇な時間があった時に友人に勧められた「五等分の花嫁」というアニメにとてもハマりました。無事映画も見ました。
内容を概説すると、主人公とヒロインの5つ子たちによるラブコメ作品になっていて、主人公の名前が「風太郎」です。彼は、初めこそ5つ子の見分けがつかないものの、時間を共にしていくほどに見分けられるようになります。僕はYOLOv7で風太郎になりたいと思います。
準備すること
- 必要なモジュールのインポート
- chromedriverのダウンロード
- labelImgのダウンロード
- YOLOv7のダウンロード
データ収集
機械学習をするにあたってデータは必須ですから、今回は Selenium を使ってスクレイピングを実施しました。また、 Selenium を使用する際に、今回は ChromeDriver を使用しています。こちらのページから ChromeDriver のダウンロードページにいけます。この時、自身の使用しているchromeと同じバージョンのChromeDriverにする必要がありますので注意して下さい。もし一致するバージョンのdriverがない場合は、一番バージョンが近いものを選べば大丈夫です。自身のchromeと ChromeDriver のバージョンがずれていると、エラーになりスクレイピングが動作しません。
ダウンロードした ChromeDriver は基本的にどこに置いてもパスで指定できれば動作できます。しかし、今後もスクレイピングを実施する場合は、奥まったローカル環境よりは、見えやすい場所に置くことをおすすめします。
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pandas as pd
def imgURL_scraping(driver_path, start_url):
img_urls = []
"""初期設定"""
# ドライバーの設定
driver = webdriver.Chrome(executable_path=driver_path)
# スクレイピング開始時の画面に遷移
driver.get(start_url)
time.sleep(1)
"""スクレイピングの実行"""
# スクロール
for _ in range(5):
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2)
element_cnts = len(driver.find_elements(by=By.XPATH, value='//*[@id="islrg"]/div[1]/*')) # 要素数を取得
for idx in range(1, element_cnts+1):
img_box = driver.find_element(by=By.XPATH, value=f"//*[@id='islrg']/div[1]/div[{idx}]")
# 画像じゃない場合は処理しない(エラー回避)
if not img_box.get_attribute('data-ved'):
continue
img_box.click()
time.sleep(1)
img_url_box = driver.find_element(by=By.XPATH, value='/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div[2]/div/div[2]/div[2]/div[2]/c-wiz/div[2]/div[1]/div[1]/div[2]/div/a/img')
img_url = img_url_box.get_attribute('src')
print(img_url)
img_urls.append(img_url)
driver.close()
return img_urls
# 取得した画像URLを一度csvファイルに保存
def write_csv(img_urls, OUTPUT_CSV_PATH):
dict = {'image_URL': []}
for img_url in img_urls:
dict['image_URL'].append(img_url)
df = pd.DataFrame.from_dict(dict)
df.to_csv(OUTPUT_CSV_PATH)
"""定数定義"""
DATA_PATH = os.path.join('..','data') # 親ディレクトリ
OUTPUT_CSV_PATH = os.path.join(DATA_PATH,'csv','image_url.csv') # 収集した画像データのURLを保存するパス
KEYWORD = '五等分の花嫁 アニメ' # 検索するワード
URL = f"https://www.google.com/search?q={KEYWORD}&hl=ja&source=lnms&tbm=isch" # chromeの画像検索結果のURL
DRIVER_PATH = os.path.join('/usr','local','bin','chromedriver') # chromedriverのパス
"""実行"""
os.makedirs(os.path.dirname(OUTPUT_CSV_PATH), exist_ok=True)
img_urls = imgURL_scraping(DRIVER_PATH, URL)
write_csv(img_urls, OUTPUT_CSV_PATH)
上記で実行したスクレイピングはあくまでデータセットとなる画像のURLを収集してcsvファイルにまとめたものになります。というのも、何らかのバグ(遷移時間が間に合わない,通信環境が途切れた等)でスクレイピングの処理がずれると、スクレイピングをやり直す必要があるからです。それが画像のダウンロードとなると面倒です。そのため、一度画像のURLを取得してから、次の処理で画像をダウンロードすることにしています。
(ついでに)
スクレイピング自体は Selenium に限らず、 requests, BeautifulSoup を使う方法もあります。僕は後者で実行を試みたのですが、画像サイズが元画像サイズではなく小さい画像の状態でしか取得できませんでした。おまけに、画面のスクロール操作ができないため、一度のスクレイピングで取得できる枚数が少なかったです。そのため、 Selenium を使うことにしました。
以下の処理にて画像データセットをダウンロードしてきます。
import os
import pandas as pd
import requests
from bs4 import BeautifulSoup as BS
"""定数定義"""
DATA_PATH = os.path.join('..','data')
CSV_PATH = os.path.join(DATA_PATH,'csv','image_url.csv')
OUTPUT_IMAGE_FOLDER = os.path.join(DATA_PATH,'images')
"""実行"""
os.makedirs(OUTPUT_IMAGE_FOLDER, exist_ok=True)
df = pd.read_csv(CSV_PATH, index_col=0) # 画像URLが記述されているcsvファイルの読み込み
for i, url in enumerate(df['image_URL']):
rq = requests.get(url)
img = rq.content
file_name = f"{str(i+1).zfill(4)}.png"
file_path = os.path.join(OUTPUT_IMAGE_FOLDER,file_name)
with open(file_path, 'wb') as wf:
wf.write(img)
ここでは元画像サイズの画像URLを既に取得しているので、 requests, BeautifulSoup を使ったスクレイピングにしています(コード書く量も少ないので)。
アノテーション
検知したい画像を矩形で囲み、ラベル付けをする作業です。YOLOv7に学習させる上で、YOLOv7が何を検知してほしいかを知る必要があるので、ここは人力で頑張る他ないです。結構地道な同じ作業の繰り返しなので、人によってはここで挫折すると思います。
僕の場合は、収集した画像が全部で400枚くらいでしたが、最終的には200枚程度に減ったため、そこまで苦ではありませんでした。
(画像が減った理由)
いくつかの理由があります。
- リーケージ画像があった
- リーケージとは全く同じ画像のことを指し、全く同じ画像が機械学習で訓練データとテストデータに分類されたりするとカンニングになり、適切な分類ができなくなってしまいます。特にスクレイピングでは、同じ画像が複数枚集まることがあるので、気をつける必要があります。
- 画像サイズが小さかった
- 画像サイズが小さすぎると機械学習が難しくなるので、あまりにも小さい場合は除くのが一般的だと思います。
- 横顔があった
- これは意見が割れると思われますが、少なくとも僕は正面の顔だけを機械学習させた方が精度が出せると思ったので、横顔の画像は除きました。加えて、横顔の検知に強いこだわりがなかったです。ここで僕の中での横顔は、目が1つしか写っていないことを指しています。
- あくまで横顔だけの画像データセットがあった場合の話であって、正面の顔と横顔が混在している画像データセットに対しては、正面の顔をアノテーションして、横顔をアノテーションしなければ良いだけの話です。
アノテーションにはlabelImgを使用しました。特に、YOLO形式のアノテーションに対応しているので、すぐに機械学習の段階に移れます。こちらにlabelImgのGitHubのページを載せておきます。自身の環境に合わせてセットアップを行ってください。
次に、ダウンロードしてきたlabelImgフォルダに対して、 labelImg/data/predefined_classes.txt を確認して下さい。デフォルトの状態になっているはずなので、このテキストファイルの中身をアノテーションしたいラベル名に書き換えましょう。今回は、 Ichika,Nino,Miku,Yotsuba,Itsuki (改行区切り) に中身を書き換えました。
あとは、labelImgを起動して、 ディレクトリを開く から先ほど収集してきたデータセットフォルダを指定してあげて、ひたすらアノテーション作業です。こんな感じ。
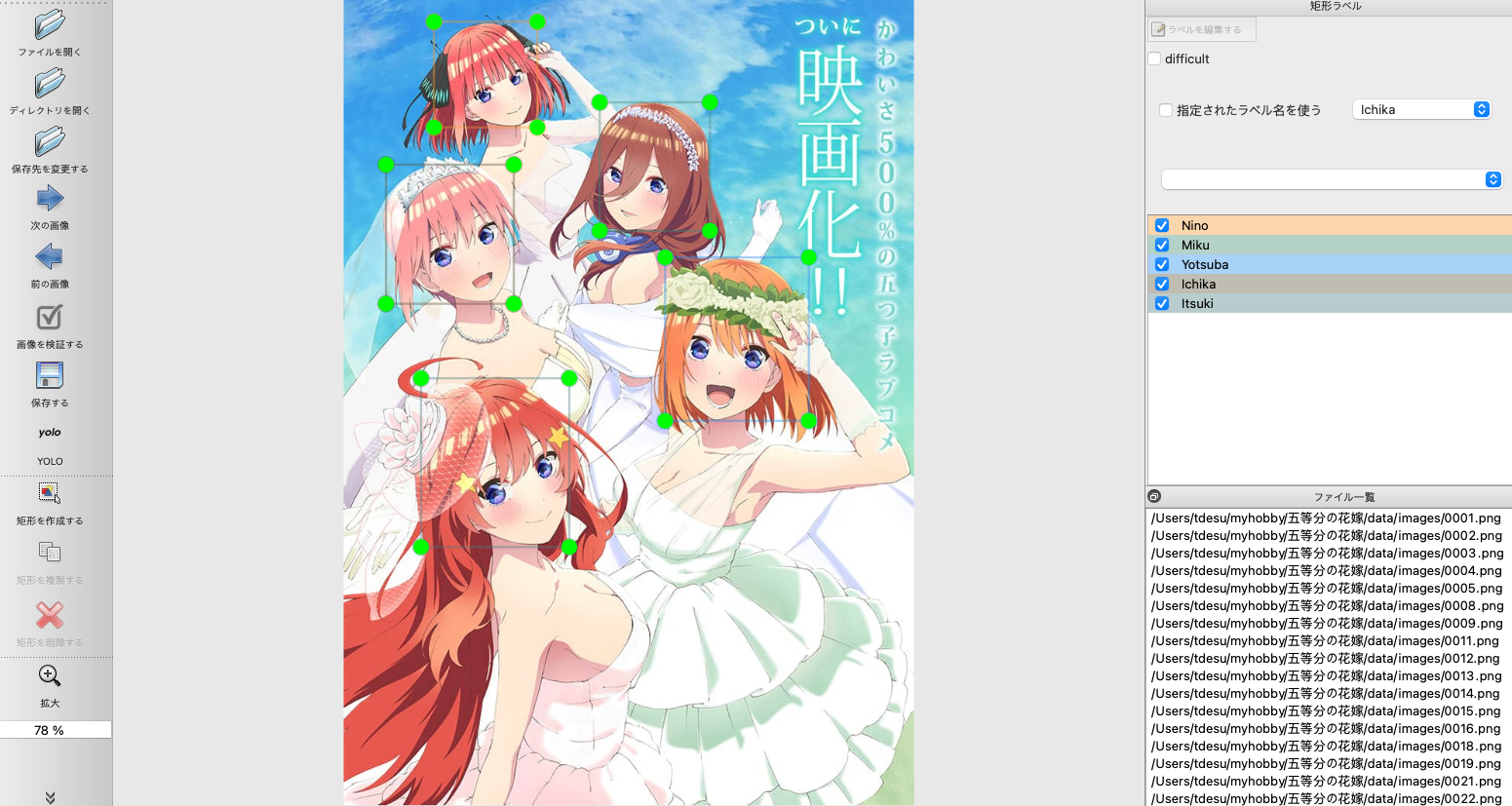
この時、画像左の中央やや下にあるマークがyoloになっていることを確認してください(デフォルトでyoloだった気がします)。その状態で アノテーションをする→保存するの繰り返し です。
また、YOLOの機械学習ではラベルと画像データセットを別々のフォルダに配置する必要があるので、画面左やや上にある「保存先を変更する」から別のフォルダにアノテーションしたtxtファイルを置くと、楽になります。僕は、画像をダウンロードしたフォルダと同じパスの高さに labels という名称のフォルダを管理して保存していました。
YOLOv7の学習用に前準備
アノテーションしたtxtファイルと画像データセットが1対1で対応できていれば、あとはYOLOv7で学習させるために少しだけフォルダ構造を整理してあげます。
import os
from glob import glob
from collections import defaultdict
import random
import shutil
"""定数定義"""
DATA_PATH = os.path.join('..','data')
IMAGE_PATH = os.path.join(DATA_PATH,'images')
LABEL_PATH = os.path.join(DATA_PATH,'labels')
"""変更の必要なし"""
CUSTOM_DATASET_PATH = os.path.join(DATA_PATH,'custom_dataset')
CUSTOM_IMAGE_PATH = os.path.join(CUSTOM_DATASET_PATH,'images')
CUSTOM_LABEL_PATH = os.path.join(CUSTOM_DATASET_PATH,'labels')
TRAIN_IMAGE_PATH = os.path.join(CUSTOM_IMAGE_PATH,'train')
VALID_IMAGE_PATH = os.path.join(CUSTOM_IMAGE_PATH,'valid')
TRAIN_LABEL_PATH = os.path.join(CUSTOM_LABEL_PATH,'train')
VALID_LABEL_PATH = os.path.join(CUSTOM_LABEL_PATH,'valid')
"""実行"""
# 必要なフォルダ作成
os.makedirs(TRAIN_IMAGE_PATH, exist_ok=True)
os.makedirs(TRAIN_LABEL_PATH, exist_ok=True)
os.makedirs(VALID_IMAGE_PATH, exist_ok=True)
os.makedirs(VALID_LABEL_PATH, exist_ok=True)
# 画像とアノテーション、それぞれのデータを取得
imgAry = sorted([img_path for img_path in glob(os.path.join(IMAGE_PATH,'*.png'))])
lblAry = sorted([lbl_path for lbl_path in glob(os.path.join(LABEL_PATH,'*.txt'))])
lblAry.remove(os.path.join(LABEL_PATH,'classes.txt')) # classes.txtを除く
# アノテーションしたクラスラベルの数を数える
dict = defaultdict(int)
for lbl_path in glob(os.path.join(LABEL_PATH,'*.txt')):
if 'class' in lbl_path:
continue
with open(lbl_path, 'r') as rf:
lines = rf.readlines()
for line in lines:
line = line.rstrip('\n')
num = int(line.split()[0])
dict[num] += 1
print(dict)
dataset = []
for img_path, lbl_path in zip(imgAry, lblAry):
dataset.append([img_path, lbl_path])
# ランダムにtrain:valid = 7:3に分ける
train_n = int(7*len(imgAry)/10) # 訓練データが7割
train = random.sample(dataset, train_n) # 7割
valid = [i for i in dataset if i not in train] # 残る3割
# データのコピー
def copy_files(target_dataset, img_folder, lbl_folder):
for img_path, lbl_path in target_dataset:
mv_img_path = os.path.join(img_folder,os.path.basename(img_path))
mv_lbl_path = os.path.join(lbl_folder,os.path.basename(lbl_path))
shutil.copy(img_path, mv_img_path)
shutil.copy(lbl_path, mv_lbl_path)
# 学習用フォルダの作成
copy_files(train, TRAIN_IMAGE_PATH, TRAIN_LABEL_PATH)
copy_files(valid, VALID_IMAGE_PATH, VALID_LABEL_PATH)
これを実行することで、 custom_dataset という新たなフォルダが作成され、以下のような構造になっているはずです。こうなっていれば大丈夫です。
ーーcustom_dataset
┣ーimages
┣ーtrain
┣ーvalid
┣ーlabels
┣ーtrain
┣ーvalid
(内訳)
僕のアノテーションした全200枚の画像における、クラスラベルの内訳は以下のようになりました。
0(=Ichika): 125, 1(=Nino): 130, 2(=Miku): 132, 3(=Yotsuba): 129, 4(=Itsuki):132
思いのほか、バランス良くアノテーションができていました。この結果で明らかにクラスラベルに偏りがある場合は、データセットを見直した方が良いかもしれません。
YOLOv7による学習
こちらのサイトを参考にさせていただきましたmm
YOLOv7による学習にあたって。僕の環境ではGPUマシンが使えないため、Google Colabにお世話になることにしました。
自身のGoogle Driveに適当にフォルダを作成して、そのフォルダに Google Colab, custom_dataset, yolov7 を配置しましょう。僕はこんな感じです。
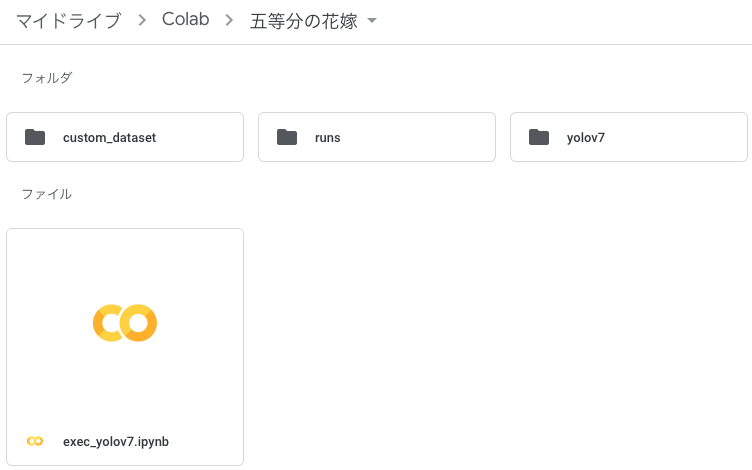
(runsフォルダは学習を開始すると自動で作成されます。学習実行前は存在しません。)
次に、Google Colabの簡単なセットアップです。作成したGoogle Colabの .ipynb ファイルを開いて、「ドライブのマウント」を実施します。Google Drive上にアップロードしたデータセット(custom_dataset)を使用できるようにするためです。
そして、.ipynbページの画面上部にある ランタイム タブから「ランタイムのタイプを変更」を選択→「ハードウェアアクセラレータを選択」にて「GPU」を選択して保存しましょう。これでGPUマシンによる高速な学習が可能になります。基本無料です(自動で有料プランに移行することはないですのでご安心を)。
次にここから学習に使用するモデルを選びましょう。僕は参考サイトを元に、 yolov7_training.pt を選んでダウンロードしました。このダウンロードしたファイルは、Google Driveの yolov7 フォルダ以下に weights という名称の新たなフォルダを作成して、その下に置きます。
最後に、学習で用いるための.yamlファイルを作成します。 yolov7/data/coco.yamlというサンプルファイルがありますので、これを真似る形で.yamlファイルを作ります。僕は dataset.yaml という名称で作りました。 nc=5 で、 class_names=['Ichika', 'Nino', 'Miku', 'Yotsuba', 'Itsuki'] にしました。
あとは、以下のコードをセルごとに分けて実行しましょう(全て同じ.ipynb上での実行です)。うまく実行できない場合は、ドライブのマウントを更新してみてください。
%cd /content/drive/MyDrive/Colab/五等分の花嫁 # 自身の作成したフォルダまで移動
!pip install -r ./yolov7/requirements.txt
!python ./yolov7/train.py --workers 8 --device 0 --batch-size 4 --epochs 100 --data ./yolov7/data/dataset.yaml --cfg ./yolov7/cfg/training/yolov7.yaml --weight ./yolov7/weights/yolov7_training.pt --name ./yolov7/yolov7_five_sisters --hyp ./yolov7/data/hyp.scratch.p5.yaml
すると、学習が開始されるのであとは待つだけです。
この学習開始時にエラーが出る場合があります。僕は出ました。 RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu) こんなやつでした。これはこちらに解決方法が載っています。 yolov7/utils/loss.py の742行目を matching_matrix = torch.zeros_like(cost, device="cpu") に書き換えるとエラーがなくなり、無事に学習が開始されました。
YOLOv7による学習結果
runs というフォルダ名に結果が入っています。僕はこんな感じの学習曲線でした。
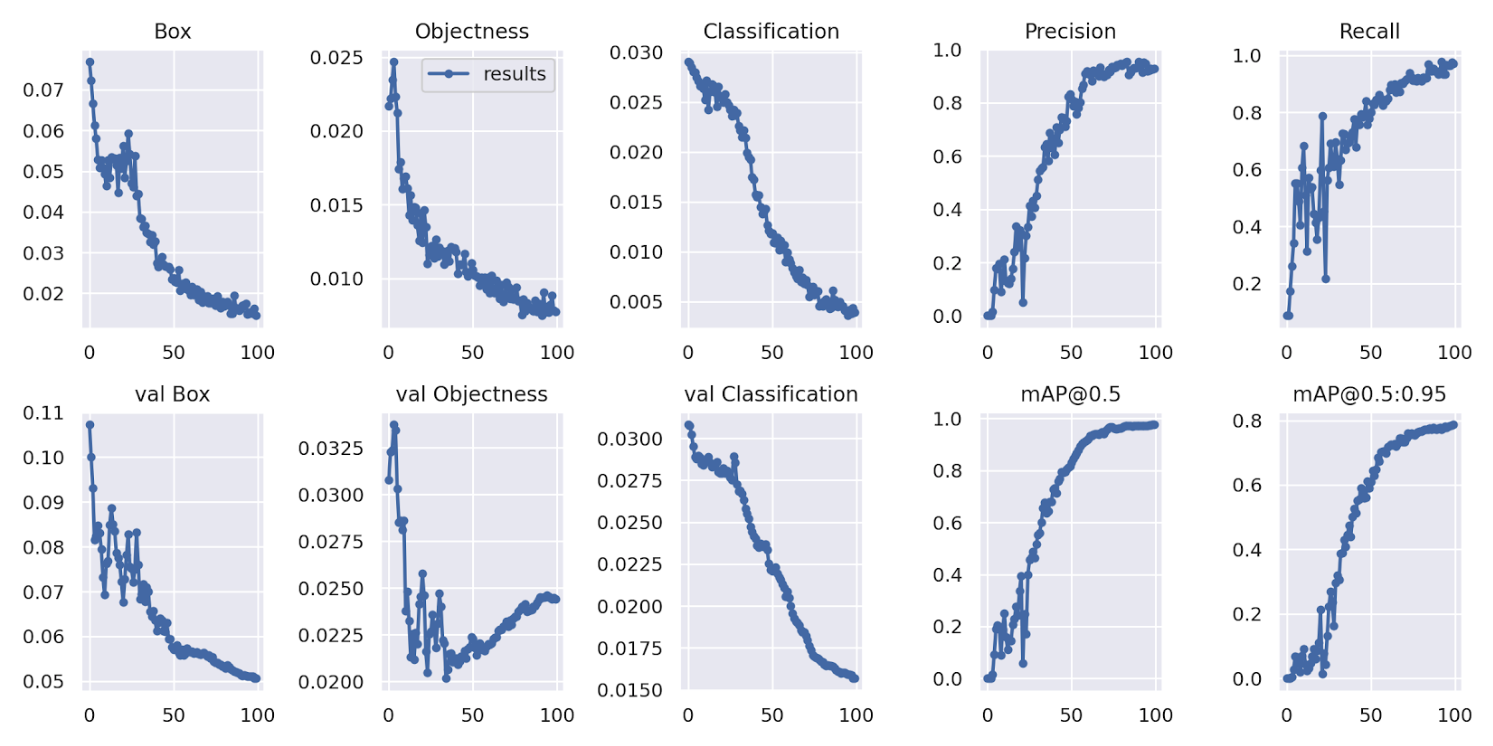
結果を直感的に知りたい場合は、混同行列が見やすいかもしれません。
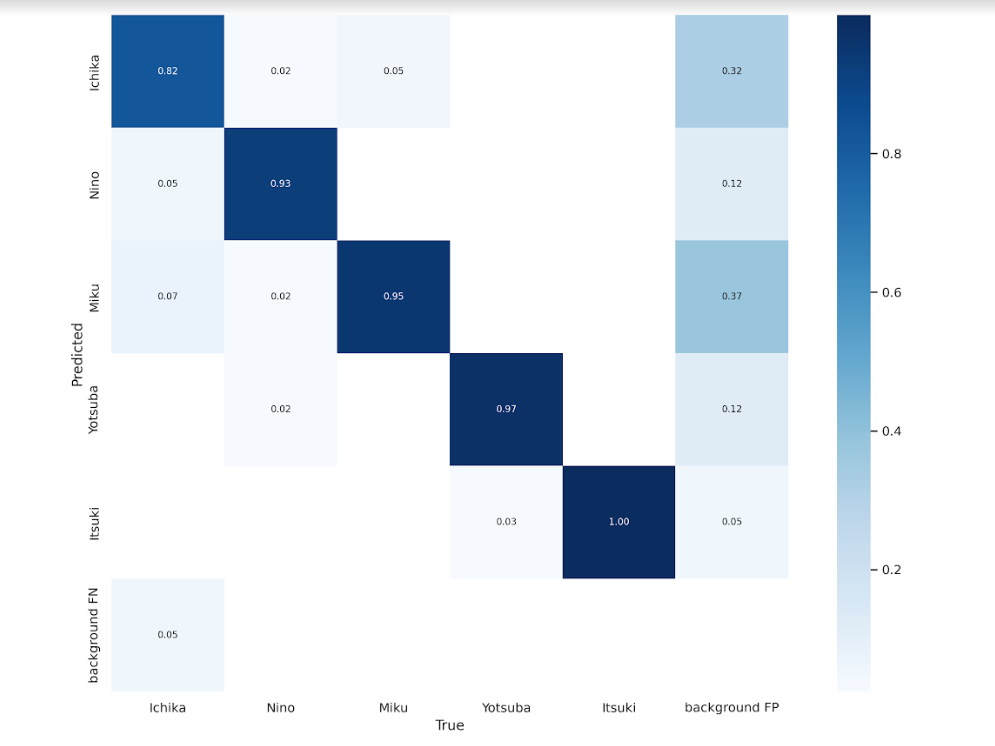
僕の学習結果では、なんとItsukiが正解率1.00でした。その他も悪くはないですが、Ichikaは周りに比べ低めの結果ですね。
テストデータによる分類結果
生成された runs フォルダの中に学習したモデルが入っています。 best.pt が名称から察するに一番良い結果のモデルでしょう( last.pt も良い結果かもしれません)。こちらをダウンロードします(面倒でしたら、そのままGoogle Colab上でこれ以降の実行をしていただいて構いません)。
また、以下で定義している TEST_IMAGES_PATH にはテストデータ用の画像を準備しておいてください。複数枚でも実行できます。ただし、リーケージにならないような画像にしてください。
import os
from glob import glob
"""定数定義"""
DATA_PATH = os.path.join('..','data')
TEST_IMAGES_PATH = os.path.join(DATA_PATH,'test_images')
OUTPUT_FOLDER_PATH = os.path.join(DATA_PATH,'detect')
"""実行"""
img_pathAry = sorted([img_path for img_path in glob(os.path.join(TEST_IMAGES_PATH,'*'))])
!python ../yolov7/detect.py --source ../data/test_images --weights ../yolov7/runs/train/yolov7/yolov7_five_sisters/weights/last.pt --project ../data/detect --name ''
ここで、上の最後の行で実行している引数は yolov7/detect.py にて説明があるのでそれを見てみてください。
(余談)
僕はYOLOv7によって予測された矩形の色にもこだわりたかったんです。ヒロインの5つ子にはそれぞれイメージカラーがあるので、僕は矩形の色をそのイメージカラーにしました。
やることは簡単で、 yolov7/detect.py の61行目の colors を書き換えるだけです。初期状態ではランダムに色が決められているので、僕はイメージカラーになるように以下に書き換えました。クラスラベルの順番に合わせて色を決めるのですが、順番がBGRの順なので注意してください。RGBの順じゃないです。
colors = [(50,240,240), (255,0,204), (240,240,50), (50,240,50), (0,0,255)] # BGR
風太郎になれたのか?
そして、いよいよ僕が風太郎になるときが来ました。その結果が以下です。


結構いい感じじゃないですか?
3枚目の画像に関しては、左から2番目の二乃が重複して予測されました。矩形の色から判断するに、重複しているいずれも合っていないという...これは学習データセットが少なかったのか。はたまた、髪の毛の色や分け目といった特徴量で学習されたのか。時間に余裕があればGradCAMなんかを使って、学習の根拠を見てみたいですね。
ということで、残念ながら風太郎になることは叶いませんでした。が、改めてYOLOの凄さに驚きますね。機械学習でモデル作る箇所やハイパーパラメータを調整する箇所が個人的に大変だと感じていますが、多くを操作せずに簡単にできちゃいました。
おまけ
読者は、主人公の風太郎がヒロインである5つ子の誰かと結婚をすることを分かっているうえで物語は進みます。それが誰なのか明らかになるのはうんと後半の方になるのですが。ということで、誰と結婚するのでしょうか?予測してみた結果が以下です。

矩形の色から判断するに一花か三玖らしいです。画像から数値がはみ出てしまっているのが悔やまれますが。
おそらく髪の色が一花で、髪の長さが三玖になった理由ですかね?
おわりに
ここに記載したPythonコードですが、僕は全てjupyter notebookを使ってコーディングしていたので、グローバル変数を使ったり、オブジェクト化してなかったりしています。ご了承下さいmm
風太郎になることはできませんでしたが、これが物語の序盤だった頃の風太郎と比較すると、良く見分けられた方だと思います(強気)。また、風太郎はAIよりも素晴らしいスペックの持ち主であるとも解釈できそうですね。