はじめに
この記事は、「PDFで受領する紙の情報(デジタル情報)から、CSVなどの構造化情報を取得したい」という要望にお応えするものです。
DXが各所で叫ばれ、業務の自動化も進んでいます。本来であれば送信元と合意形成をしデータで受け取ることがよいと思います。しかし合意に時間も必要となり、PDFからデータを取得したいという要望もあるかと思い、Pythonモジュールを紹介してみます。
概要
PDF→Text→CSV
PDFから非構造のテキストデータを抽出し、構造化されたCSVデータを生成する、という2段ステップです。
PDF→Text はPythonの知識は不要です。Text→CSVはPythonの知識が必要です。とはいえ必要部分を修正するだけですのでPython未経験者も是非取り組んでみていただけると良いかと思います。
PDF:infile.pdf
https://drive.google.com/file/d/1JY7JXfjkvbSK1Eo65805Gq-z9t3bQOg8/view?usp=sharing
↓
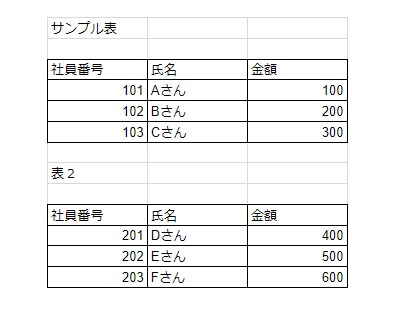
サンプル表
社員番号 氏名 金額
101 Aさん 100
102 Bさん 200
103 Cさん 300
表2
社員番号 氏名 金額
201 Dさん 400
202 Eさん 500
203 Fさん 600
↓
,syainNo,shimei,kingaku
0,201,Dさん,400
1,202,Eさん,500
2,203,Fさん,600
表2のみ取得してみました。
必要条件
PDFは画像ではなくデジタル(文字情報を含む)である必要があります。変換したいPDFに対し検索(CTRL + F)をかけて文書の文字列を検索できれば、それはデジタルPDF(と呼ぶことにします)になります。
まずはPDFをTextにします。(pdf2txt)
pdf2txtというモジュールがあります。以下の記事を参照いただけると良いかと考えます。
(上述のフォルダには格納していません)
こちらでpdfをテキスト化したファイルを中間成果物とします。
https://qiita.com/T_Umezaki/items/84086e8da5188ef8ca8d
上述の例では以下を実施しています。
python .\pdf2txt.py -M 15.0 -o c:\work\OutFile.txt c:\work\InFile.pdf
pdf2txtの成果物のTextをCSVにします。
モジュールは設定ファイルとプログラム本体、および入出力用フォルダの構成です。
in フォルダにpdf2txtの成果物(outfile.txt)を格納し、txt_to_txt.py を実行すると、outフォルダに成果物(CSV)を作成する仕組みです。
txt_to_txt.cfgは設定ファイルになります。
txt_to_txt.pyは読み取る内容に合わせた改修が必要です。
# coding:utf-8
# copy right saison infomation systens co.,ltd
import os
import configparser
import argparse
import glob
import pandas as pd
import re
# 設定ファイルから情報を取得
parser = argparse.ArgumentParser()
parser.add_argument("param")
args = parser.parse_args()
print(args.param)
cfgpath = args.param
cfgfile = configparser.ConfigParser()
cfgfile.read(cfgpath, 'UTF-8')
in_folder = cfgfile.get('settings', 'in_folder')
out_folder = cfgfile.get('settings', 'out_folder')
filesname = cfgfile.get('settings', 'files_name') # 拡張子 *.txt のみを取得
print(in_folder)
dirname = os.path.dirname(cfgpath)
print(dirname)
os.chdir(in_folder)
in_files = glob.glob(filesname)
os.chdir(dirname)
# pandas dataflame を作成し、処理を実施して格納、最後にCSVで出力
cols = ['syainNo', 'shimei', 'kingaku']
df = pd.DataFrame(index=[], columns=cols)
for in_file in sorted(in_files):
print(in_file)
infile_path = in_folder + '\\' + in_file
outfile_path = out_folder + '\\' + in_file
textFile = open(infile_path, 'r', encoding='utf-8')
textLine = ''
sectionflag = '' # 表の判別用。
for textLineTmp in textFile:
textLine = textLineTmp.rstrip('\n')
# print (textLine)
# 表2を判別
if re.match('表2', textLine):
sectionflag = '表2'
if sectionflag == '表2':
# データ行を判別しデータを取得。例題の場合は表2という文字列の下で3桁の数値で始まる行
res = re.match(r'^\d{3}\s', textLine)
if res:
columns = textLine.split()
df = df.append({'syainNo': columns[0], 'shimei': columns[1], 'kingaku': columns[2]}, ignore_index=True)
# print(columns)
textFile.close()
print(df)
df.to_csv(outfile_path)
[settings]
in_folder = C:\work\in
out_folder = C:\work\out
files_name = *.txt
最後に
以上pdf文書をcsv化する方法を簡単にまとめてみました。
今回は業務自動化までは言及しませんでしたが、DataSpiderなどでの業務自動化も相性はよいと考えます。
面倒な業務は少しでも楽にし、GDPを向上しましょう!w