1. はじめに
IBM Cloud Pak for Data as a Service(CP4DaaS)のSPSS Modelerにはテキストデータ分析を行うノードが提供されています。これまでは日本語に対応していませんでしたが、2024年10月9日の新機能により日本語のテキストデータにも対応しました。
SPSS Modelerの「テキスト分析」カテゴリーには以下の3つのノードが含まれます。

| ノード | 説明 |
|---|---|
| 言語の識別子 | ソース・データ内のテキスト・フィールドの自然言語を識別します。 |
| テキスト・リンク分析 | 既知のパターンに基づいてテキスト・データのコンセプト間の関連性を特定します。 |
| テキスト・マイニング | テキストから主要なコンセプトを抽出し、これらのコンセプトとその他のデータを使用してカテゴリーを作成します。 |
製品ドキュメントにテキスト分析のチュートリアルとしてホテル満足度のテキスト分析
が提供されています。
このチュートリアルで使用しているストリームやテキスト・データはリソース・ハブのSPSS Modeler projectに含まれていますが、英語のテキストを使用しています。
(CP4DaaSにログインすると画面右上のリンクからプロジェクトをダウンロードできます。)

この記事ではチュートリアルと同様の方法で、「テキスト・リンク分析」ノードを使用して日本語のテキストを分析する手順を記載します。
-
作成するストリーム

-
実行結果例(Raw TLA output)
テキストデータに含まれるワードが「コンセプト」と「タイプ」のペアで分析された結果を確認できます。

-
実行結果例(Positive/Negative)
コメントごとにポジティブな内容とネガティブな内容が含まれている数をカウントした結果を確認できます。

使用する日本語テキストデータと作成するSPSSストリームのサンプルはこちらからダウンロードできます。
なお「テキスト・マイニング」ノードを使用した手順は別の記事で記載しています。
2. プロジェクトの作成
最初にwatsonx.ai Studioのプロジェクトを作成します。
リソース・ハブで提供されているプロジェクトをインポートするか、新規に空のプロジェクトを作成します。
3. 日本語テキストデータの準備
リソース・ハブからダウンロードしたプロジェクトに含まれるテキストデータを日本語化します。対象のファイルは「hotelSatisfaction.xlsx」です。
820件のホテルの満足度に関する文章が含まれますが、機会翻訳サービス等を使用してヘッダー行以外を日本語に翻訳します。
以下は翻訳後のデータ例です。ここでは「hotelSatisfaction_japanese.xlsx」として保存し、プロジェクトにアップロードします。

4. SPSS Modelerストリームの作成
プロジェクトにSPSS Modelerストリームを作成します。
ここでは「Hotel Satisfaction Text Link Analysis」という名前で作成しています。

5. 「テキスト・リンク分析」ノードを使用したテキスト分析
ここでは2つのブランチ・ターミナル・ノードを作成します。
- Raw TLA Output
テキストデータに含まれるワードが「コンセプト」と「タイプ」のペアで分析された結果を確認できます。 - Positive/Negative
コメントごとにポジティブな内容とネガティブな内容が含まれている数をカウントした結果を確認できます。
5-1. Raw TLA Output
-
作成したSPSS Modelerストリームを開きます。
「データ資産」ノードを追加し、日本語テキストデータ(hotelSatisfaction_japanese.xlsx)を指定します。

-
「テキスト・リンク分析」ノードを追加し、「データ資産」ノードと接続後、設定画面を表示します。IDフィールドに「id」、テキストフィールドに「Comments」、「リソースの選択 +」から「Hotel Satisfaction (Japanese)」を指定して保存します。


-
「置換」ノードを追加し、「テキスト・リンク分析」ノードと接続後、設定画面を開きます。対象フィールドに「id」、置換に「常時」、置換文字列に「to_integer(@FIELD)」を指定して保存します。
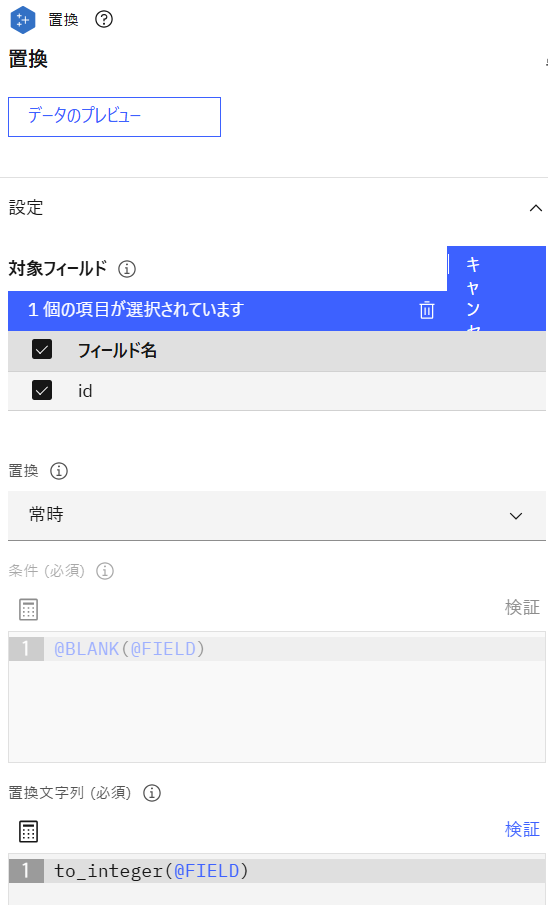
-
「タイプ」ノードを追加し、「置換」ノードと接続後、設定画面を開きます。「値の読み込み」をクリックし、値が読み込まれたら保存します。

-
「フィルター」ノードを追加し、「タイプ」ノードと接続後、設定画面を開きます。「コンセプト5」から「条件規則名」までの入力フィールドをフィルターして保存します。

-
「ソート」ノードを追加し、「フィルター」ノードと接続後、設定画面を開きます。ソート順に「id」「昇順」を指定して保存します。

-
「表」ノードを追加し、「ソート」ノードと接続後、設定画面を開きます。名前に「Raw TLA output」を指定して保存します。
-
以下のストリームができたら実行して表の出力を確認してみます。

-
テキストデータに含まれるワードが「コンセプト」と「タイプ」のペアで分析されていることが分かります。
5-2. Positive/Negative
-
最初に追加した「データ資産」ノード(hotelSatisfaction_japanese.xlsx)をコピーして貼り付けます。

-
「マージ」ノードを追加し、直前に追加した「データ資産」ノードと「5-1. Raw TLA Output」のブランチで追加した「タイプ」ノードと接続後、設定画面を開きます。マージ法に「キー」、キーに「id」を指定して保存します。

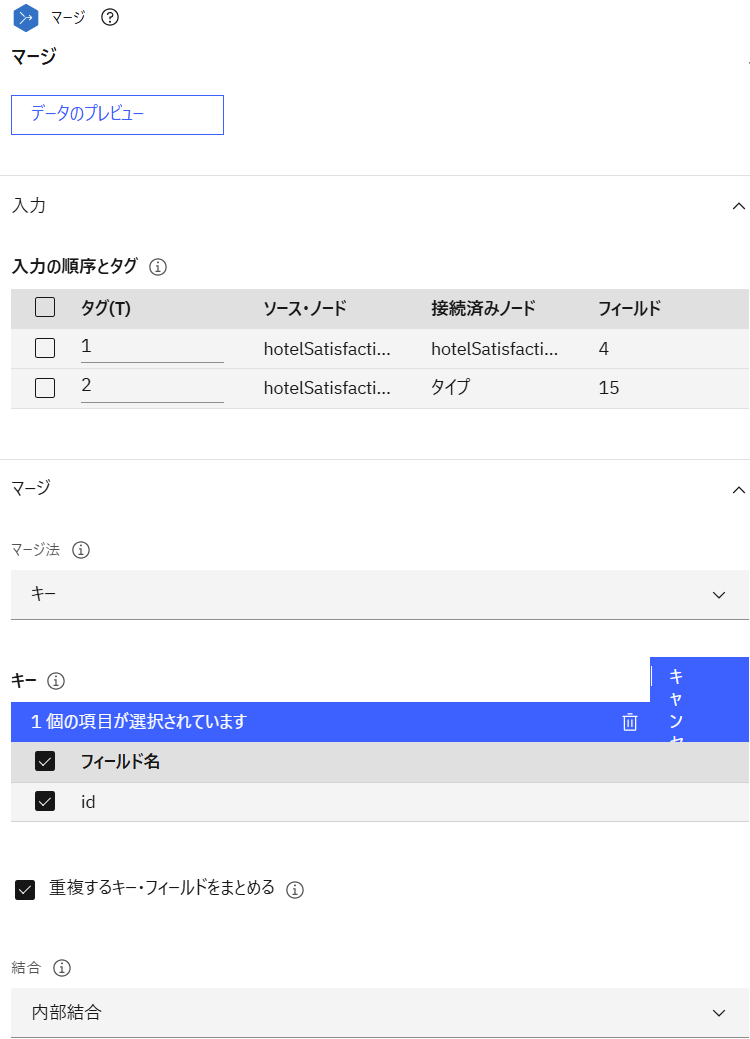
-
「置換」ノードを追加し、「マージ」ノードと接続後、設定画面を開きます。対象フィールドに「タイプ1」と「タイプ2」、置換に「常時」、置換文字列に以下の式を指定して保存します。
置換文字列if @FIELD matches 'Positive*' then 1 elseif @FIELD matches 'Negative*' or @FIELD = 'NO' or @FIELD = 'Contextual' or @FIELD = 'Suggestion' then -1 else 0 endif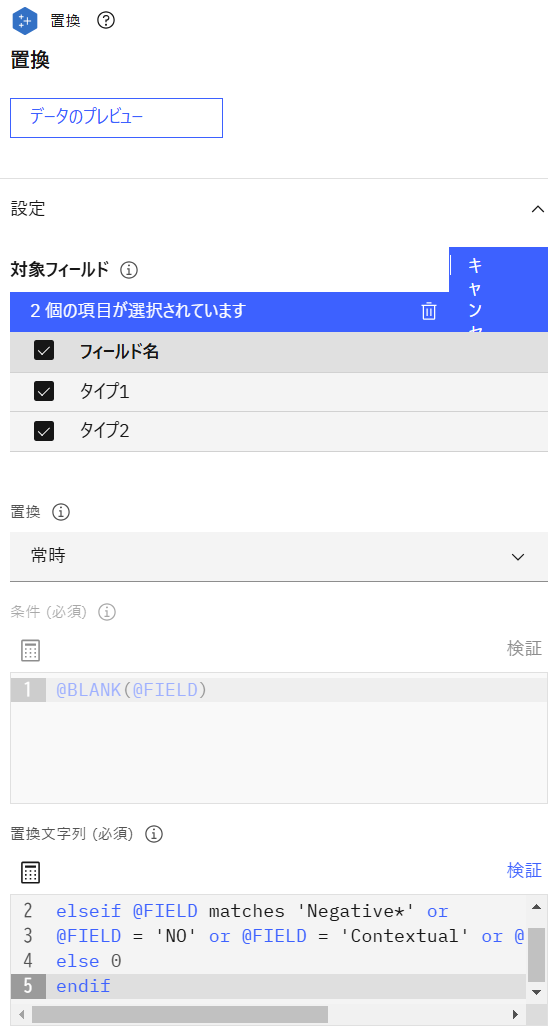
-
「フィールド順序」ノードを追加し、「置換」ノードと接続後、設定画面を開きます。最後に配置するフィールドに「コンセプト1」「コンセプト2」「タイプ1」「タイプ2」の順になるように設定して保存します。

-
「フィールド作成」ノードを追加し、「フィールド順序」ノードと接続後、設定画面を開きます。派生フィールド名に「sentiment_sum」、式に以下の式を指定して保存します。
式sum_n(@FIELDS_BETWEEN('タイプ1','タイプ2'))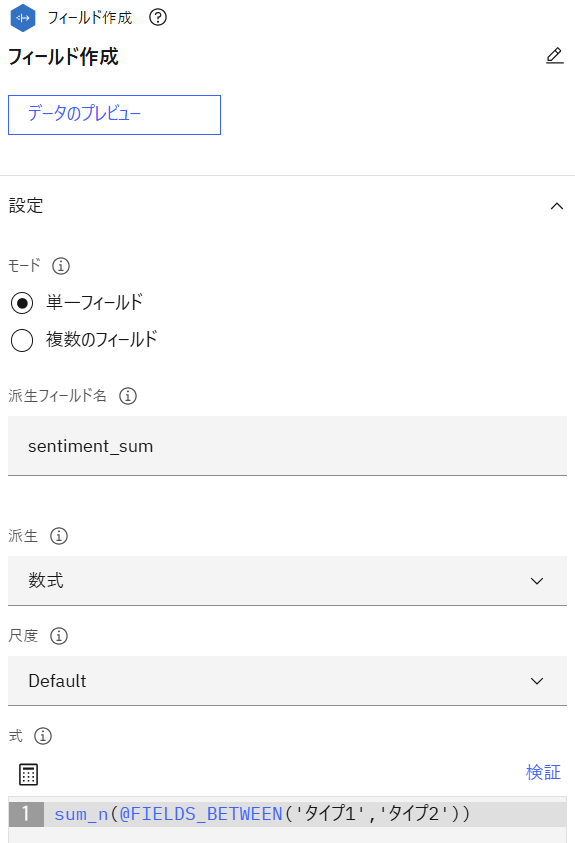
-
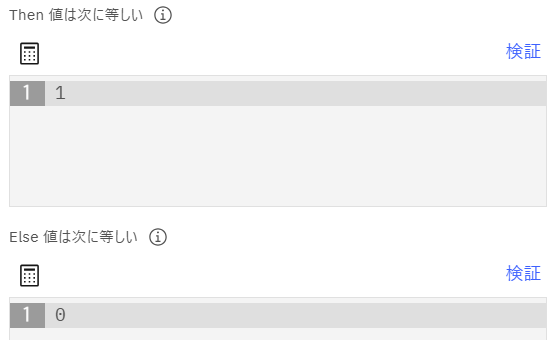
「フィールド作成」ノードを追加し、直前に追加した「フィールド作成」ノードと接続後、設定画面を開きます。派生フィールド名に「Pos_Count」、派生に「条件付き」、Ifに以下の式、「Then 値は次に等しい」に「1」、「Else 値は次に等しい」に「0」を指定して保存します。
Ifsentiment_sum > 0
-
「フィールド作成」ノードを追加し、直前に追加した「フィールド作成」ノードと接続後、設定画面を開きます。派生フィールド名に「Neg_Count」、派生に「条件付き」、Ifに以下の式、「Then 値は次に等しい」に「1」、「Else 値は次に等しい」に「0」を指定して保存します。
Ifsentiment_sum < 0

-
「レコード集計」ノードを追加し、「フィールド作成」ノードと接続後、設定画面を開きます。キー・フィールドに「id」と「Comments」、集計フィールドに「Pos_Count」と「Neg_Count」(集計操作は「Sum」)、「レコード・カウントを含める」のチェックを外して保存します。


-
「表」ノードを追加し、「レコード集計」ノードと接続後、設定画面を開きます。名前に「Positive/Negative」を指定して保存します。
-
以下のストリームができたら「Positive/Negative」ノードを選択してストリームを実行し、表の出力を確認してみます。
-
コメントごとにポジティブな内容とネガティブな内容が含まれている数をカウントした結果が出力されています。
おことわり
このサイトの掲載内容は私自身の見解であり、必ずしも所属会社の立場、戦略、意見を代表するものではありません。 記事は執筆時点の情報を元に書いているため、必ずしも最新情報であるとはかぎりません。 記事の内容の正確性には責任を負いません。自己責任で実行してください。