はじめに
AWS SysOps Administraitor - Associateが2021/07/26をもって、SOA-C01から完全にSOA-C02へと移行されます。
ちょっとずつまとめていきます。
とりあえず、試験ガイドの比較だけ見ていただければ(笑)
※この記事に網羅性はありません。すべて個人的に出そうだな~というところをまとめたものです。
試験ガイド
比較
・SOA-C01
試験ガイドはこちら
・SOA-C02
試験ガイドはこちら
・試験ガイドの比較
| 項目 | SOA-C01 | SOA-C02 |
|---|---|---|
| 評価項目 | ・AWS での拡張性、可用性、フォルトトレランス性の高いシステムのデプロイ、管理、運用 ・AWS との間で送受信されるデータフローの実現と制御 ・コンピューティング、データ、セキュリティの要件に基づく、適切な AWS サービスの選択 ・AWS の運用に関するベストプラクティスの適切な適用方法の特定 ・AWS の利用料金の見積りと、運用コストの管理方法の特定 ・ |
・AWS 上のワークロードを展開、管理、および運用する。 ・AWS Well-Architected フレームワークに従って AWS ワークロードをサポートおよび保守する。 ・AWS Management Console および AWS CLI を使用して運用する。 ・セキュリティコントロールを実装することにより、コンプライアンス要件を満たす。 ・システムを監視、ロギング、およびトラブルシューティングする。 ・ネットワーキングに関する概念 (例: DNS、TCP/IP、ファイアウォール) を適用する。 ・アーキテクチャ要件 (例: 高可用性、パフォーマンス、キャパシティ) を実装する。 ・事業継続およびディザスタリカバリに関する手順を実行する。 ・インシデントを特定、分類、および解決する。 |
| 回答タイプ | 2種類 ・択一選択問題: 選択肢には 1 つの正解と 3 つの不正解 (誤答) があります。 ・複数選択問題: 5 つ以上の選択肢の中に 2 つ以上の正解があります。 |
3種類(増えた…) ・択一選択問題:選択肢には 1 つの正解と 3 つの不正解 (誤答) があります。 ・複数選択問題:5 つの選択肢のうち、2 つが正解です。(選択肢5個以上じゃなくなった?) ・試験ラボ:AWS Management Console または AWS CLI で実行するタスクで構成されたシナリオです。(後述)(!?) |
| 合格スコア | 720 | 720 |
| 試験内容の概要 | 分野1:モニタリングとレポート 22% 分野2:高可用性 8% 分野3:展開とプロビジョニング 14% 分野4:ストレージ及びデータの管理 12% 分野5:セキュリティとコンプライアンス 18% 分野6:ネットワーク 14% 分野7:自動化と最適化 12% |
分野1:監視、ロギング、及び解決 20% 分野2:信頼性および事業継続性 16% 分野3:展開、プロビジョニング、および自動化 18% 分野4:セキュリティおよびコンプライアンス 16% 分野5:ネットワークおよびコンテンツ配信 18% 分野6:コストおよびパフォーマンスの最適化 12% |
全体的にすごく豪華になった印象です(笑)
回答タイプは増えていますし、概要の分野は減ってこそいますが、すべての分野で「および」が入っているので、実質増えています(笑)
新回答タイプ!試験ラボ!!
こちらを見ていただけるとイメージが沸くかなと思いますが、右側の指示に対して実際にオペレーションをしていくというハンズオンみたいな形式ですね。
サンプル見る限りではラッキー問題に見えますが、どうなんでしょうか。
例えば、「災対環境への切替を行え」とか来たら、なかなか普段行わない業務なので、戸惑いそうですね。
なにより、これから上位資格でもこの形式が追加されるかもしれないと思うと…
概要
試験ガイドが非常に丁寧になったこともあり、まとめやすくなったので、時間があるときに少しずつまとめていきます。
とりあえず書けるところまで、メモ書き程度に…
分野 1: 監視、ロギング、および解決
1.1 AWS の監視サービスおよびロギングサービスを使用して、メトリクス、アラーム、およびフィルタを実装する。
ログを識別、収集、分析、およびエクスポートする
(例: Amazon CloudWatch Logs、CloudWatch Logs Insights、AWS CloudTrail ログ)。
■CloudWatch Logs
公式ドキュメントはこちら
EC2インスタンス、CloudTrail、Route53などのAWS内の多くのサービスのログを保存することができます。
↓ロググループとログストリームのイメージ

【機能】
・ CloudWatch Logs Insights
Amazon CloudWatch Logsのログデータを検索し分析することができます。
CloudWatch Logs Insightsで使用されるクエリについてはこちらを参照してください。
・ ログの保持期間
ロググループごとに保持期間を設定できます。(デフォルトは無制限)
選択可能な範囲は1日間~10年間
ずっとロググループに保存しているとコストが高くつくので、特定の期間ロググループで保存した後は、S3に移動するのが推奨ですね。
■AWS CloudTrail ログ
APIコールを取得します。
証跡を追うために用いられるサービスですね。
イベント履歴の保持期間は90日間のため、証跡を作成して、S3バケットに保存します。
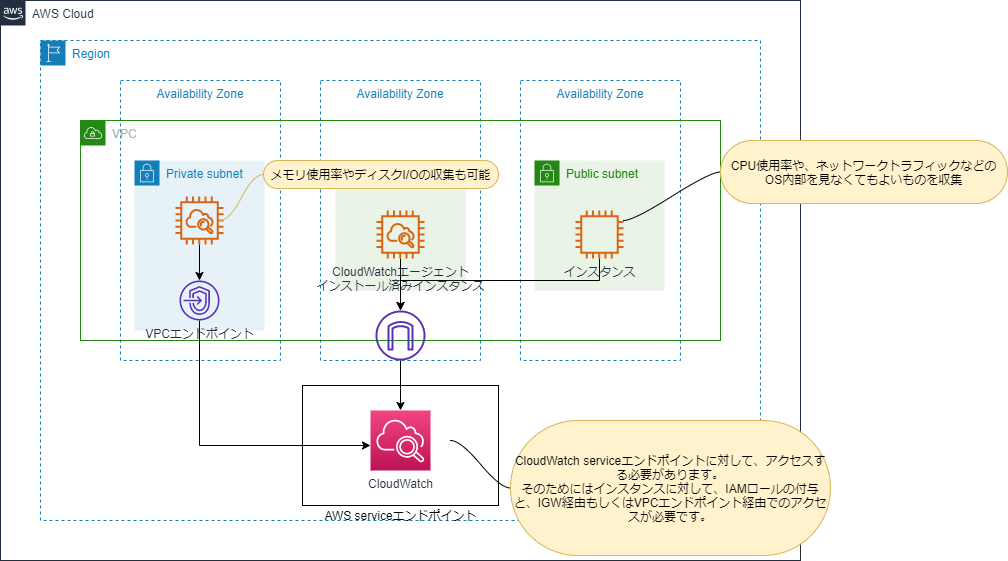
CloudWatch エージェントを使用して、メトリクスおよびログを収集する。
CloudWatch Agentを使用すると、OS内部から情報を取得できます。
例えば、メモリ使用率やディスクI/Oなどを取得する要件がある場合はCloudWatch Agentのインストールが必要になります。
また、CloudWatch AgentからCloudWatchサービスエンドポイントへのアクセスを許可する必要があります。
・インスタンスにIAMロールのアタッチ
・アクセス経路の確保
VPCエンドポイント経由 or IGW経由
CloudWatch アラームを作成する。
特定のイベントを検知して発報するサービスです。(「CPU使用率が80%を超えた」など)
【アラームの状態(ステータス)】
| 状態 | 説明 |
|---|---|
| OK | メトリクスや式は、定義されているしきい値の範囲内です。 |
| ALARM | メトリクスまたは式が、定義されているしきい値を超えています。 |
| INSUFFICIENT_DATA | アラームが開始直後であるか、メトリクスが利用できないか、メトリクス用のデータが不足しているため、アラームの状態を判定できません。 |
【設定値】
| 設定項目 | 説明 | 例 |
|---|---|---|
| 期間 | メトリクスや式を評価する期間 | 1分と指定した場合、1分に1回評価を行います |
| 評価期間 | アラームの状態を決定するまでに要する最新の期間またはデータポイントの数 | 5と指定すると、最新の5個のデータポイントを評価します |
| アラームを実行するデータポイント | アラームが ALARM 状態に移るためにしきい値を超過する必要がある評価期間内のデータポイントの数 | 3と指定すると評価期間内の3個のデータポイントで閾値を超過した場合に、ALARM状態に移行します |
例)
期間:1分
評価期間:5
アラームを実行するデータポイント:3
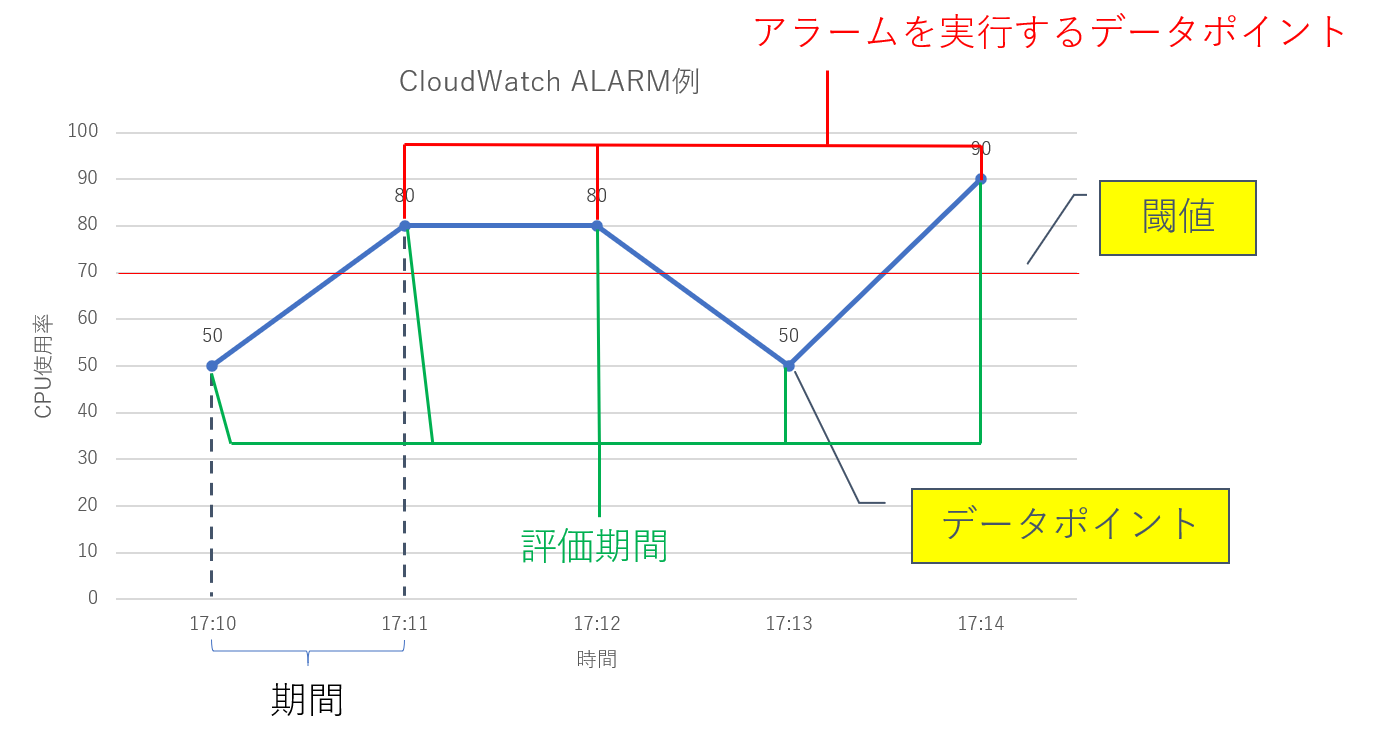
評価期間(5)のうち、アラームを実行するデータポイント(3)が閾値を超えたときアラームを発報します。
【高解像度アラーム】
通常のアラームの場合には、60秒の倍数でしか期間を設定できません。
しかし、高解像度アラームを使用することで、10秒または30秒の期間を指定できます。
(高解像度アラームは有料です。料金はこちらから)
【数式に基づくアラーム】
1 つ以上の CloudWatch メトリクスに含む数式の結果に基づいてアラームを設定できます。
アラーム用の数式には 10 個までのメトリクスを含めることができます。各メトリクスは同じ期間を使用している必要があります。
数式に基づくアラームでは Amazon EC2 アクションを実行できません。
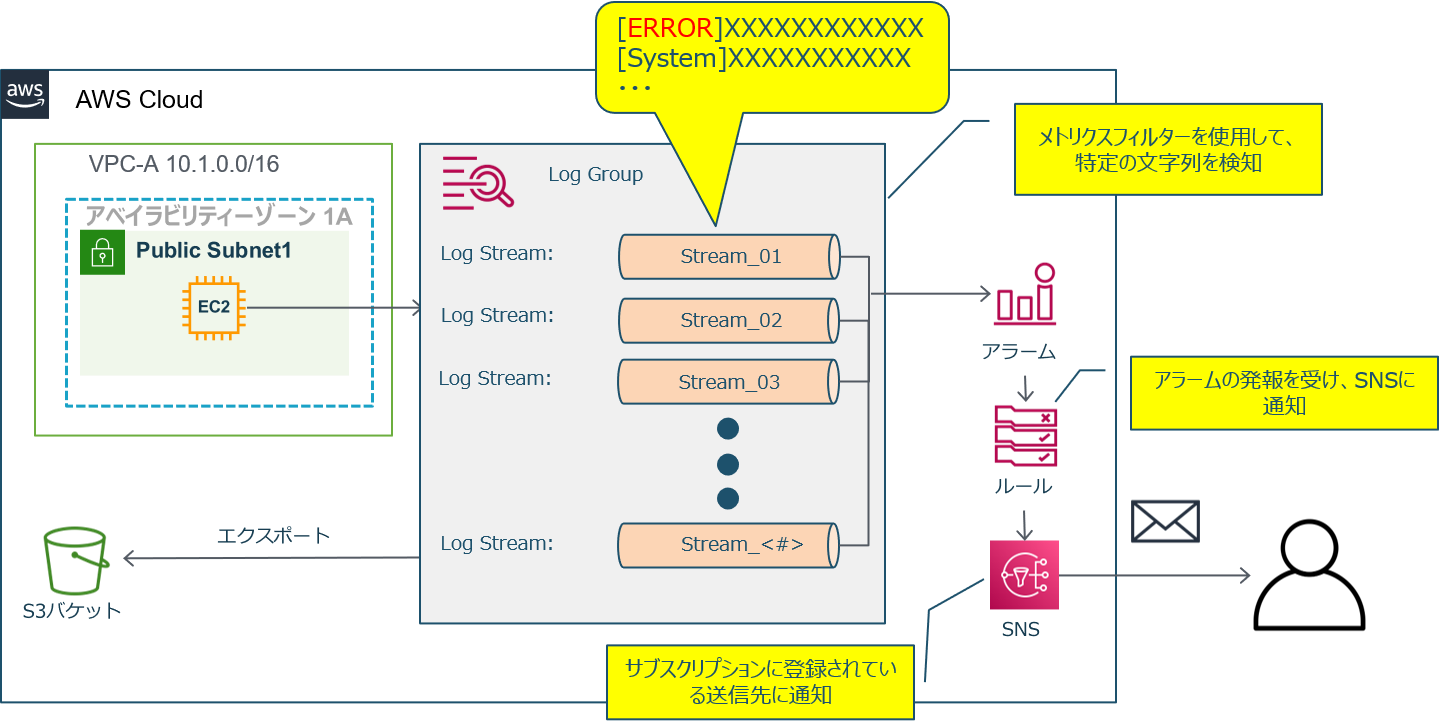
メトリクスフィルタを作成する。
ログから特定の文字列(ERRORなど)を検知して発報します。
CloudWatch ダッシュボードを作成する。
メトリクスを可視化することができるサービスですね。
↓こんな感じ(私の環境はまともなメトリクスを取ってなかったので、こちらから拝借)
CloudWatchダッシュボードはマルチアカウントにも対応していて、管理下のアカウントで作成されたダッシュボードを一つのアカウントから閲覧することもできます。
マルチアカウントで、運用管理を一元化する要件が出た際には設定する項目かと思います。
該当記事:Amazon CloudWatch でクロスアカウント、クロスリージョンダッシュボードの利用が可能に
通知を構成する
(例: Amazon Simple Notification Service (Amazon SNS)、ServiceQuotas、CloudWatch アラーム、AWS Health イベント)。
通知のよくある構成は先ほどの「メトリクスフィルタを作成する。」を確認してください。
■Amazon SNS
言わずと知れた、AWSで通知を行う際に最も使われているサービスですね。
【イベント送信先】
大まかに分けると以下の二種類があります。
・A2Aメッセージング(アプリケーション to アプリケーション)
例)Kinesis Data Firehose、SQS
・A2P通知(アプリケーション to Person)
例)Eメール、SMS
詳しくはこちら
【FIFOトピック】
重複排除や順序などの文言がある場合はFIFOトピックを検討する必要があります。
SQS FIFOキューと一緒に使用することが前提みたいですね。
詳しくはこちら
【サブスクリプションフィルター】
メッセージの属性でフィルターをかけて、送信先を制御することができます。
該当記事:SNSサブスクリプションのフィルタポリシーで良い知らせだけをメール受信する
■AWS Service Quotas
各リソースの上限数を管理します。
上限緩和申請もここから行えます。
Service Quotasと使用状況メトリクスを統合しているサービスはこちらを参照してください。
2021/07/20時点では、以下のサービスが統合されています。
・AWS CloudHSM
・Amazon CloudWatch
・Amazon DynamoDB
・Amazon EC2
・Amazon Elastic Container Registry
・AWS Fargate
・AWS Fault Injection Simulator
・AWS Interactive Video Service
・AWS Key Management Service
・Amazon Kinesis Data Firehose
・AWS Robomaker
通知設定を行うための手順は下記の記事が参考になります。
該当記事:CloudWatch で Service Quotas をグラフ化・アラート通知できるようになりました!
■AWS Health イベント
公式ドキュメント
AWS Healthというよりは我々が意識しなければいけないのは**AWS Personal Health Dashboard(PHD)**を意識する必要があります。
AWS Personal Health Dashboard を使用して、AWS サービスまたはアカウントに影響を与える可能性がある AWS Health イベントについて確認できます。
アカウント固有の障害が発生した場合にはPHDにイベントが送られます。
リージョン規模の障害が発生した場合にはService Health Dashboardを使用する必要があります。
該当記事:リージョン規模の障害が発生した時に Service Health Dashboard から障害情報の通知を受け取る方法
通知設定については、こちらをご参照ください。
1.2 監視メトリクスおよび可用性メトリクスに基づいて問題を解決する。
通知およびアラームに基づいて、トラブルシューティングを行うかまたは是正措置を講じる。
エラーメッセージから対応策を考えるみたいな問題が出題されるのかなと思います。
以下、例です。(ざっと調べたやつまとめ)
個人的に出題されそうな対応策は太字にしてます。(ニュアンス)
| エラーメッセージ | 対応策 |
|---|---|
| InsufficientInstanceCapacity | ・数分間待ってからリクエストを再度送信します。容量は頻繁に変化します。 ・インスタンス数を減らして新しいリクエストを送信します。たとえば、15 インスタンスを起動する 1 つのリクエストを行っている場合、代わりに 5 つのインスタンスに対する 3 つのリクエストを作成するか、1 つのインスタンスに対する 15 のリクエストを作成してみてください。 ・インスタンスを起動する場合は、アベイラビリティーゾーンを指定しないで新しいリクエストを送信します。 ・インスタンスを起動する場合は、別のインスタンスタイプを使用して新しいリクエストを送信します (これは後でサイズを変更できます)。詳細については、「インスタンスタイプを変更する」を参照してください。 ・クラスタープレイスメントグループに複数のインスタンスタイプでインスタンスを起動すると、容量不足エラーが発生する場合があります。同じインスタンスタイプで起動するのが推奨です。詳細については、「プレイスメントグループのルールと制限」を参照してください。 |
| InstanceLimitExceeded |
上限緩和申請 (<サービス名>LimitExceededは対応していればすべて上限緩和申請で対応) |
| UnauthorizedOperation | decode-authorization-messageコマンドを実行しデコードします。 不足している権限を該当のIAMリソースにアタッチします |
| Client.InternalError | ・EBSの名前を変更し、再アタッチする。 ・ボリュームからスナップショットを作成し、新しいボリュームを作成、アタッチする。 ・ボリュームで使用されているキーへのアクセス権をアタッチする。 |
| Rate exceeded | ・ GetResourceConfigHistoryまたは ListDiscoveredResources API 呼び出しの場合は、手順に従って、AWS Config コンソールのエラーメッセージをトラブルシューティングします。・ PutMetricData API 呼び出しについては、「CloudWatch API で PutMetricData を呼び出すときに、スロットルを回避する方法を教えてください。」をご参照ください。・AWS Auto Scaling に関連する API 呼び出しについては、「Auto Scaling API 呼び出しがスロットリングされています。これを防ぐにはどうすればよいですか ?」をご参照ください。 ・AWS Lambda 関数に関連する API 呼び出しについては、「 「Rate exceeded」エラーと 429「TooManyRequestsException」エラーの Lambda 関数のスロットリングをトラブルシューティングする方法を教えてください。」をご参照ください。 ・AWS Elastic Beanstalk に関連する API 呼び出しについては、「Elastic Beanstalk で API スロットリングまたは「Rate Exceeded」エラーを解決する方法を教えてください。」をご参照ください。 ・また、待機ステートメントを追加することで、スロットリングが発生した後で AWS API 呼び出しを再試行することを許可することもできます。詳細については、「AWS でのエラーの再試行とエクスポネンシャルバックオフ」をご参照ください。 |
| Access Denied | 場合によりすぎるので、省略 Amazon S3 から 403: Access Denied エラーをトラブルシューティングする方法 |
特に覚えておかないといけないのは、**「上限緩和申請」「エクスポネンシャルバックオフ」「同時実行制限(Lambda)」**あたりでしょうか。
キリがないので、一旦ここまでにしておきます…
参考:
EC2 インスタンスを開始または起動できないのはなぜですか?
EC2 インスタンスを開始または起動する際に発生する、InsufficientInstanceCapacity エラーのトラブルシューティング方法を教えてください。
EC2 インスタンスを起動しようとすると、「この操作を実行する権限がありません」というエラーメッセージが表示されるのはなぜですか?
インスタンスを開始できず、describe-instances コマンドの実行時に Client.InternalError が表示されます。この問題を解決する方法を教えてください。
どの API 呼び出しが「Rate exceeded」エラーを引き起こしているかを確認するにはどうすればよいですか?
アクションをトリガするよう、Amazon EventBridge ルールを構成する。
Amazon EventBridge は、直接関連していない独自のアプリケーションや AWS 外で提供される SaaS (Software-as-a-Service) アプリケーション、および AWS のサービスから送信されるデータを配信先としてサポートしている AWS サービスにルーティングするイベントバスを Amazon EventBridge コンソールで登録設定するだけでご利用いただけるよう機能およびリソースを提供しているサービスです。
下記の記事が非常にわかりやすいです。
サーバーレスのイベントバスって何 ? Amazon EventBridge をグラレコで解説
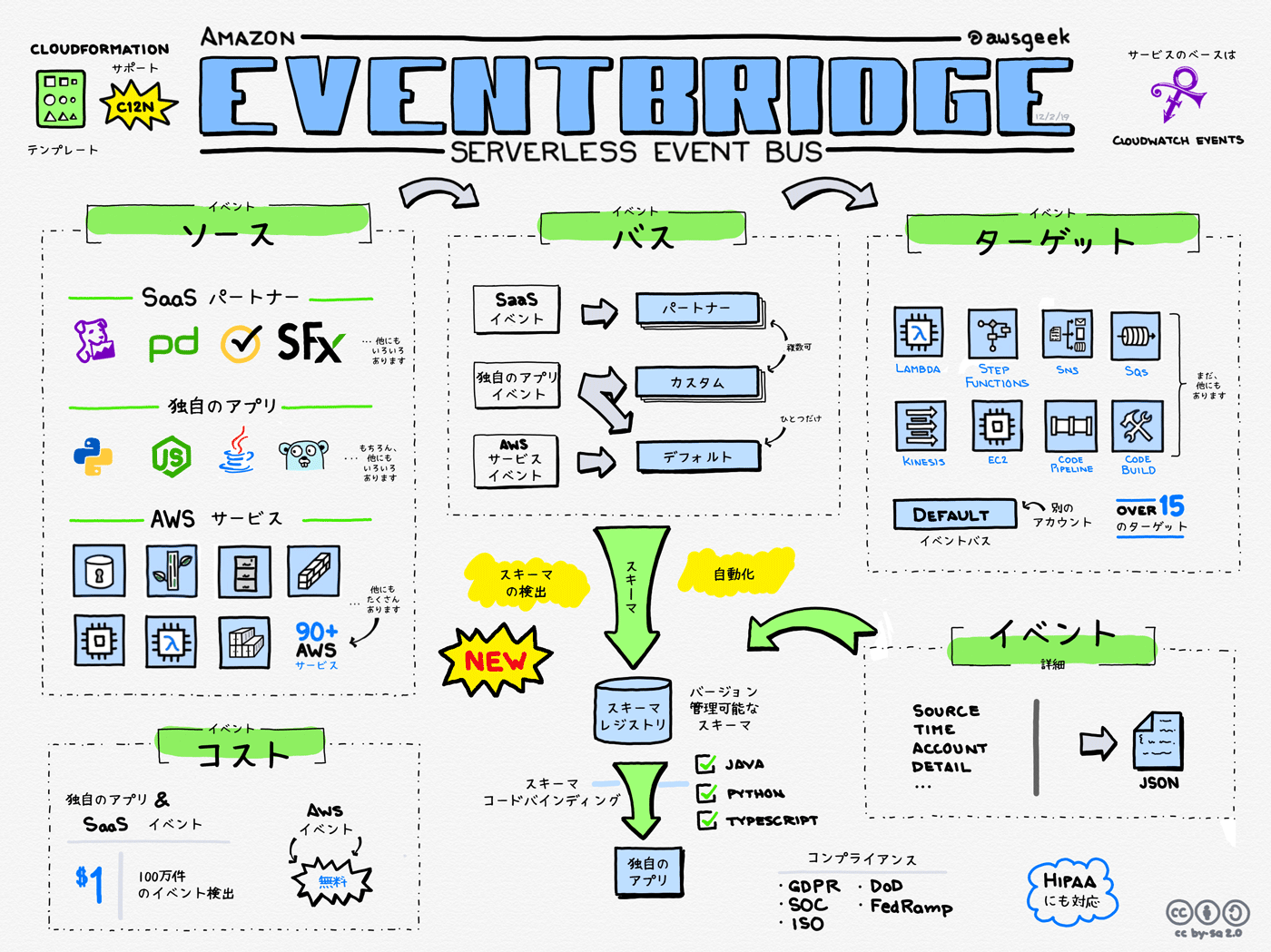
「Amazon EventBridge ルール」と「Amazon CloudWatch Events ルール」って何が違うの?ってたまに聞かれますが…
ほぼ同じものです!Amazon CloudWatch Events ルールをベースにしたものがAmazon EventBridge ルールです、2021/07/21時点では両方使えますし、
片方にルールを追加するとちゃんと追う一方に反映されますね。
好きな方を使いましょう(笑)
(イベントバスとかの見易さ的に個人的にはAmazon EventBridge ルールの方が好きですが、CloudWatchの他のサービスと一緒に使うことも多いと思うので、ほんとに好みの問題ですね)
【ルールの種類】
・イベントに反応するルール
特定のイベントが実行された際にトリガーします。
・スケジュールで実行するルール
時間を指定して、トリガーします。
使用できる形式は「cron式」「rate式」です。
AWS Systems Manager 自動化ドキュメントを使用して、AWS Config ルールに基づくアクションを実行する。
AWS Config では、AWS Config Rules で評価されている非準拠のリソースを修復できます。AWS Config では、AWS Systems Manager 自動化ドキュメントを使用して修復が適用されます。これらのドキュメントでは、非準拠で実行されるアクションを定義します。AWSによって評価されたリソースAWS Config Rules。SSM ドキュメントは、AWSManagement Console または API を使用して関連付けることができます。
例)
required-tagsルールで特定のタグをつけていないリソースを検知した際、ルールの修復アクションに「AWS-SetRequiredTags」ドキュメントを使用したオートメーションを設定しておくことで、自動的に指定のタグをつけるといったことが可能になります。
分野 2: 信頼性および事業継続性
2.1 拡張性および伸縮性を実装する。
AWS Auto Scaling プランを作成および保守する
AWS Auto Scaling は、アプリケーションを監視し、可能な限り低コストで安定した予測可能なパフォーマンスを維持するように自動的に容量を調整します。
スケーリングプランの対象とするリソースは以下のように三つの方法で検索することができます。

【スケーリング戦略】
スケーリング戦略(プラン)を指定します。
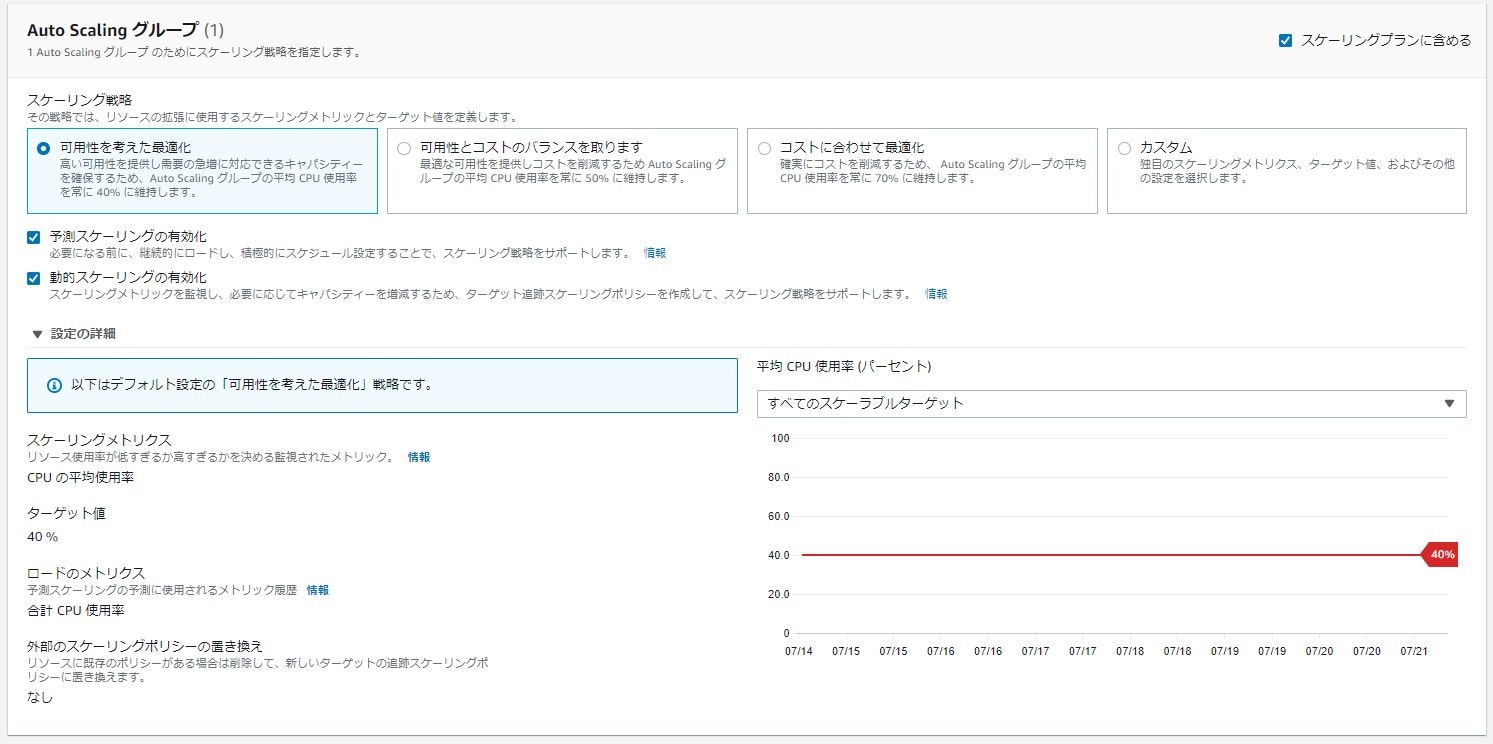
一番右側のカスタムを選択するとスケーリングメトリクスを編集することが可能になります。
【ベストプラクティス】
・1 分間隔で Amazon EC2 インスタンスメトリクスをスケール
・Auto Scaling グループメトリクスを有効にする
・Auto Scalingグループが使用しているインスタンスタイプを確認
【ActiveWithProblemsエラー】
スケーリングプランがアクティブであっても、1 つまたは複数のリソースのスケーリング設定を適用できなかった場合に、このエラーが発生します。
このエラーを回避するためには以下の点について考慮する必要があります。
・予測スケーリングでは、新しい Auto Scaling グループを作成してから 24 時間待ってスケーリングを設定する
・複数のプランで同じリソースが選択されている場合、既存のスケーリングポリシーを削除し、AWS Auto Scaling コンソールから作成されたターゲット追跡スケーリングポリシーに置き換えることができます。スケーリングポリシーを上書きする各リソースの [Replace external scaling policies (外部スケーリングポリシーを置き換え)] 設定を有効にします。
参考:AWS Auto Scalingスケーリングプランのベストプラクティス
キャッシングを実装する。
急に抽象的になりましたが、きっとこの記事とか見ておくと良いのかな…知らんけど……
ぱっと思いつくキャッシングサービスは以下の通りです。
・ElastiCache
・Amazon DynamoDB Accelerator (DAX)
・ローカルキャッシュ
・エッジキャッシュ(CloudFront)
詳しくはこちらの「ユースケースと業種」を見てみるとよいと思います。
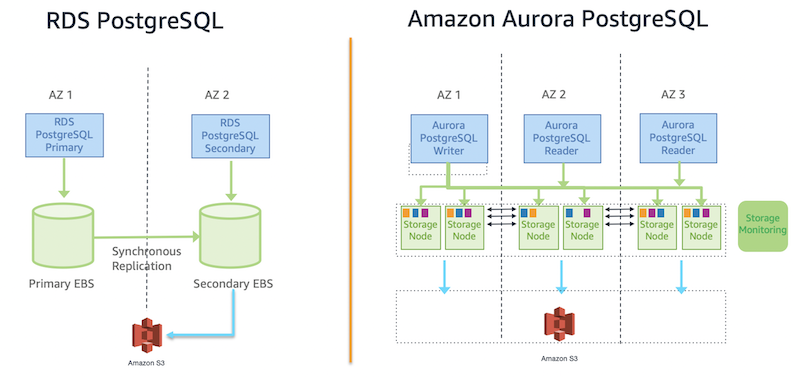
Amazon RDS レプリカおよび Amazon Aurora レプリカを実装する。
SAAもそうですけど、ホント好きですよねリードレプリカ
スタンバイインスタンスと一緒に出題されることが多い印象ですが、スタンバイインスタンスは読み込み処理とかできないですね。
リードレプリカとマルチAZ配置についてもよく出題される箇所かなと思います。
こちらの「リードレプリカ、マルチ AZ 配置、およびマルチリージョン配置」の比較表がわかりやすくて好きです。
読み取りワークロードが高いレプリケーションラグを許容できず、5つを超える読み取りレプリカが必要な場合は、AuroraPostgreSQLの方が適しています。レプリケーションの遅延が数秒から数分で許容可能であり、読み取りワークロードに最大5つのレプリカで十分な場合は、Amazon RDS forPostgreSQLの方が適しています。
とあるように、Auroraの方がより高速です。
RDSとAuroraの比較については、以下の記事が非常にわかりやすいです。(画像リンク)
疎結合アーキテクチャを実装する。
疎結合 = SQSと覚えてしまっている自分はダメ人間でしょうか…
【そもそも疎結合って?】
マイクロサービスのようにそれぞれのサービスが独立している状態で繋がっているものを疎結合という
参考:マイクロサービスの概要
サービスの形式には大きく分けて二種類あります。
「モノリシック」と「マイクロサービス」です。
・モノリシック
すべてのプロセスが密に結合し、単一のサービスとして実行される
・マイクロサービス
サービス内の複数のコンポーネントが1つのサービスとして独立していて、それぞれをつなげる
各サービスの障害の影響が小さく済む
それぞれにメリデメはありますが、最近の流行は明らかにマイクロサービスですね。
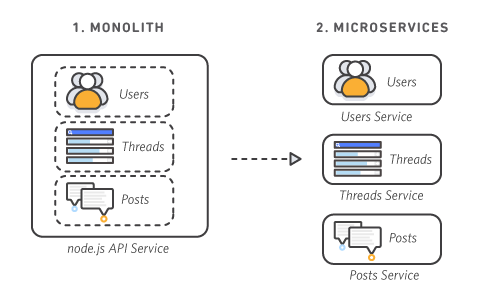
その疎結合を実現するサービスとして最もよく出しゃばってくるのがSQSです!(※個人の意見です)
SQSについてはAWSのグラレコ記事が出ていてわかりやすいのでこちらを参照してください。
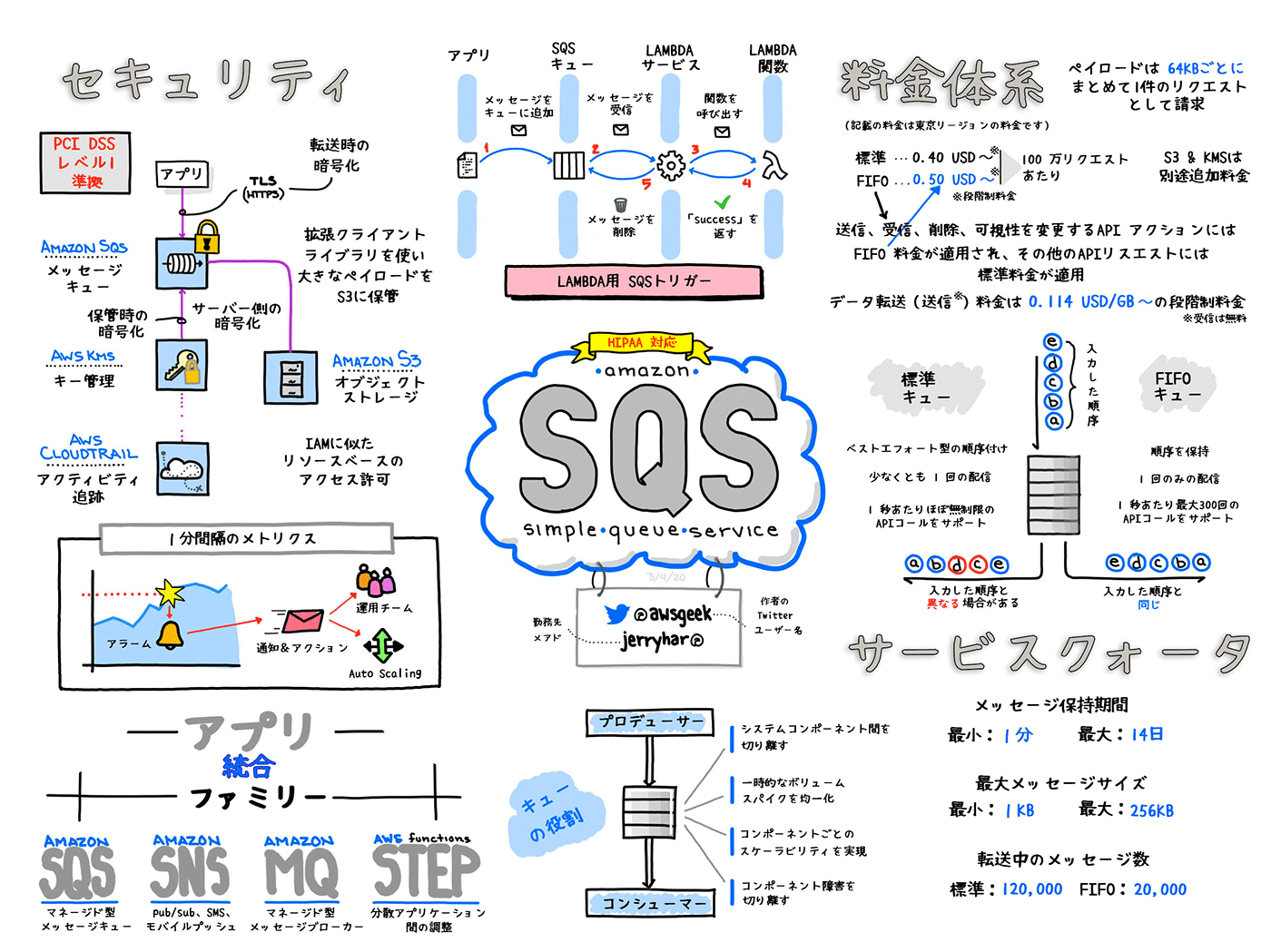
水平スケーリングと垂直スケーリングを使い分ける。
EC2インスタンスを例にすると、それぞれ以下のようになります。
・水平スケーリング(スケールアウト/イン):インスタンスの数を増減する
・垂直スケーリング(スケールアップ/ダウン):インスタンスタイプを変更する(スペックを変更する)
以下、イメージ
【使い分け】
| 垂直スケーリング | 水平スケーリング |
|---|---|
| リソースの限界が存在 | 論理的には限界が存在しない |
| インスタンスの停⽌が伴う | インスタンスの停⽌が伴わない |
参考;
Scaling Your Amazon RDS Instance Vertically and Horizontally
クラウドのためのアーキテクチャ設計
2.2 高可用性および回復性を備えた環境を実装する。
Elastic Load Balancer および Amazon Route 53 のヘルスチェックを構成する。
■Auto Scaling インスタンスのHealth チェック
Auto Scalingのヘルスチェックは以下の3種類のいずれかから通知を受け取ります。
・Amazon EC2(デフォルト)
インスタンスが以下の状態であるということを判断した場合に通知を出します。
〇stopping
〇stopped
〇shutting-down
〇terminated
インスタンス自体に問題がないと検知しないため、中のアプリケーションでエラーが起きていても通知は出しません。
・ELB
ターゲットへのリクエストが正常に終了しない場合に通知を出します。
ステータスコードまで確認するため、アプリケーションでエラーが発生した場合も通知を出します。
・カスタムヘルスチェック
独自のヘルスチェックシステムがある場合はこちらを使用します。
■Elastic Load Balancerのヘルスチェック
詳しくは公式ドキュメントを参照してください。
【ヘルスチェックの設定】
よく見る設定値のみ、下記に記載します。
| 設定 | 説明 |
|---|---|
| HealthyThresholdCount | 非正常なインスタンスが正常であると見なすまでに必要なヘルスチェックの連続成功回数。範囲は 2~10 です。デフォルトは 3 です。 |
| UnhealthyThresholdCount | 非正常なインスタンスが非正常であると見なすまでに必要なヘルスチェックの連続失敗回数。この値は正常なしきい値カウントと同じでなければなりません。 |
| matcher | [HTTP/HTTPS ヘルスチェック] ターゲットからの正常なレスポンスを確認するために使用する HTTP コード。この値は、200~399 である必要があります。 |
【ターゲットヘルスステータス】
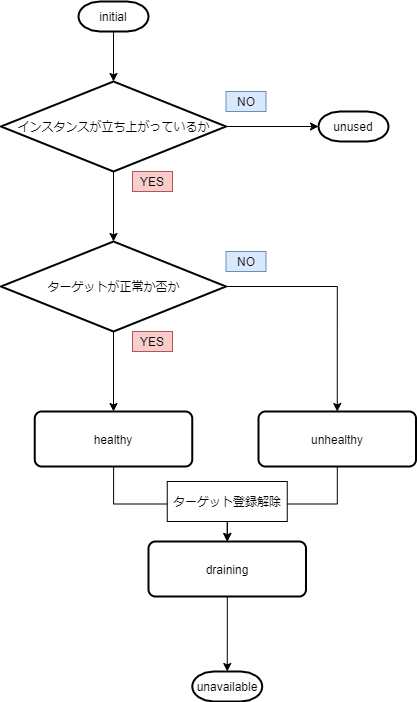
【ヘルスチェックの理由コード】
ターゲットのステータスが Healthy 以外の値の場合、API は問題の理由コードと説明を返し、コンソールのツールヒントで同じ説明が表示されます。Elb で始まる理由コードはロードバランサー側で発生し、Target で始まる理由コードはターゲット側で発生します。
■Route53のヘルスチェック
【Amazon Route 53 ヘルスチェックの種類】
・エンドポイントをモニタリングするヘルスチェック
Route 53 は、世界各地にヘルスチェッカーを持っています。エンドポイントをモニタリングするヘルスチェックを作成すると、ヘルスチェッカーは、エンドポイントが正常であるかどうかを判断するためにユーザーが指定するエンドポイントにリクエストの送信を開始します
<ヘルスチェッカーが正常性を評価するために使用する二つの値>
〇応答時間
〇失敗の閾値
<ヘルスチェックのタイプ>
〇HTTP/HTTPS ヘルスチェック
〇TCP ヘルスチェック
〇HTTP/HTTPS ヘルスチェックと文字列一致
指定の文字列が、レスポンス本文に含まれているかを検索し、なかった場合ヘルスチェックは不合格となります。
検索文字列はレスポンス本文の最初の5,120バイト内に存在する必要があります。
Route 53 は、実際のステータス (正常または非正常) を決定するための十分なデータを得るまでは、新しいヘルスチェックを正常と見なします。ヘルスチェックのステータスを反転するオプションを選択した場合、Route 53 は、十分なデータを得るまでは、新しいヘルスチェックを非正常と見なします。
・他のヘルスチェック (算出したヘルスチェック) を監視するヘルスチェック
ヘルスチェックの入れ子のような状態です。
1つの親ヘルスチェックは255個の子ヘルスチェックを監視できます。
以下、イメージです。
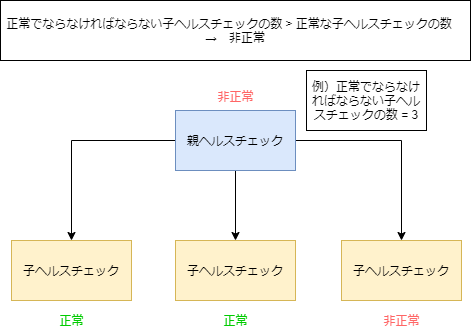
・CloudWatch アラームをモニタリングするヘルスチェック
CloudWatchアラームの状態によって、正常稼働どうかを判断します。
| CloudWatch Alarm | Route53ヘルスチェック |
|---|---|
| OK | 正常 |
| Alarm | 異常 |
| データ不足 |
InsufficientDataHealthStatusの値 |
詳しくはこちらを参照してください。
単一アベイラビリティーゾーン配置とマルチ AZ 配置を使い分ける
(例: Amazon EC2 AutoScaling グループ、Elastic Load Balancing、Amazon FSx、Amazon RDS)。
■AutoScaling Group Multi AZ
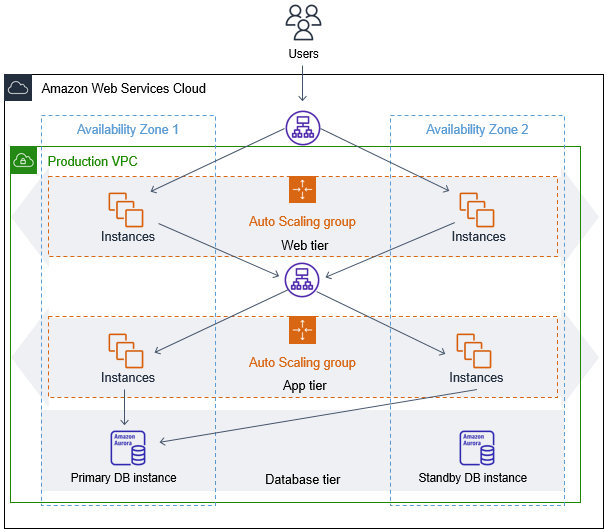
1 つのアベイラビリティーゾーンが異常ありまたは使用不可になると、Amazon EC2 Auto Scaling は、影響を受けていないアベイラビリティーゾーンで新しいインスタンスを起動します。異常のあるアベイラビリティーゾーンが正常な状態に戻ると、Amazon EC2 Auto Scaling は Auto Scaling グループのすべてのアベイラビリティーゾーンにわたって均等にアプリケーションインスタンスを自動的に再分散します。Amazon EC2 Auto Scaling は、インスタンス数が最も少ないアベイラビリティーゾーンで新しいインスタンスの起動を試みることで、これを実行します。この試みが失敗すると、Amazon EC2 Auto Scaling は成功するまで他のアベイラビリティーゾーンでの起動を試みます。
【アベイラビリティゾーンの再分散】
再分散の際には、新しいインスタンスを先に起動し、古いインスタンスを後から削除します。
→ 一時的に上限を超える可能性があります。(一時的に最大容量を超えられます)
以下のアクティビティが発生した場合に、再分散が発生する可能性があります。
・グループのアベイラビリティーゾーンを変更する。
・インスタンスを明示的に終了するかデタッチして、そのグループをアンバランスにする。
・容量が不足していたアベイラビリティーゾーンが回復し、使用できる容量が増えた。
・これまでスポット価格が上限価格より高かったアベイラビリティーゾーンで、スポット価格が上限価格より低くなった。
詳しくはこちらを参照してください。
■Elastic Load Balancing
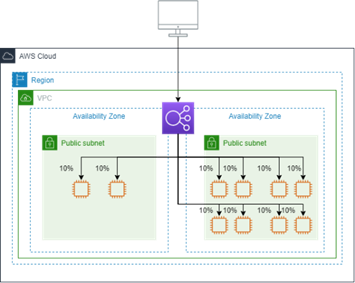
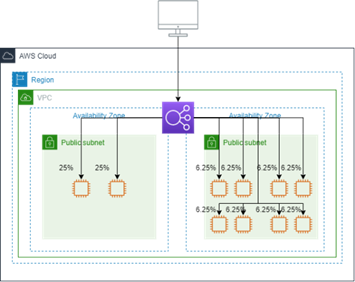
【クロスゾーン負荷分散】
クロスゾーン負荷分散は、インスタンスが存在するアベイラビリティーゾーンに関係なく、すべてのバックエンドインスタンスに均等にリクエストを分散します。
以下、イメージです。
【有効な場合】
【無効な場合】
■Amazon FSx
【シングルAZ】
・AZ内でデータを自動的にレプリケート
・耐久性の高いバックアップを毎日作成し、Amazon S3 に保存
【マルチAZ】
・異なるアベイラビリティーゾーンにスタンバイファイルサーバーが自動的にプロビジョニングされて維持
・同期的に Availability Zone 間でスタンバイにレプリケート
・自動的にフェイルオーバー、フェイルバック
詳しくはこちら
■Amazon RDS
「シングルAZ ⇔ マルチAZ」の変更は可能(リソース作成後に)
Amazon RDS のマルチ AZ 配置では、異なるアベイラビリティーゾーンに同期スタンバイレプリカが自動的にプロビジョニングされて維持されます。
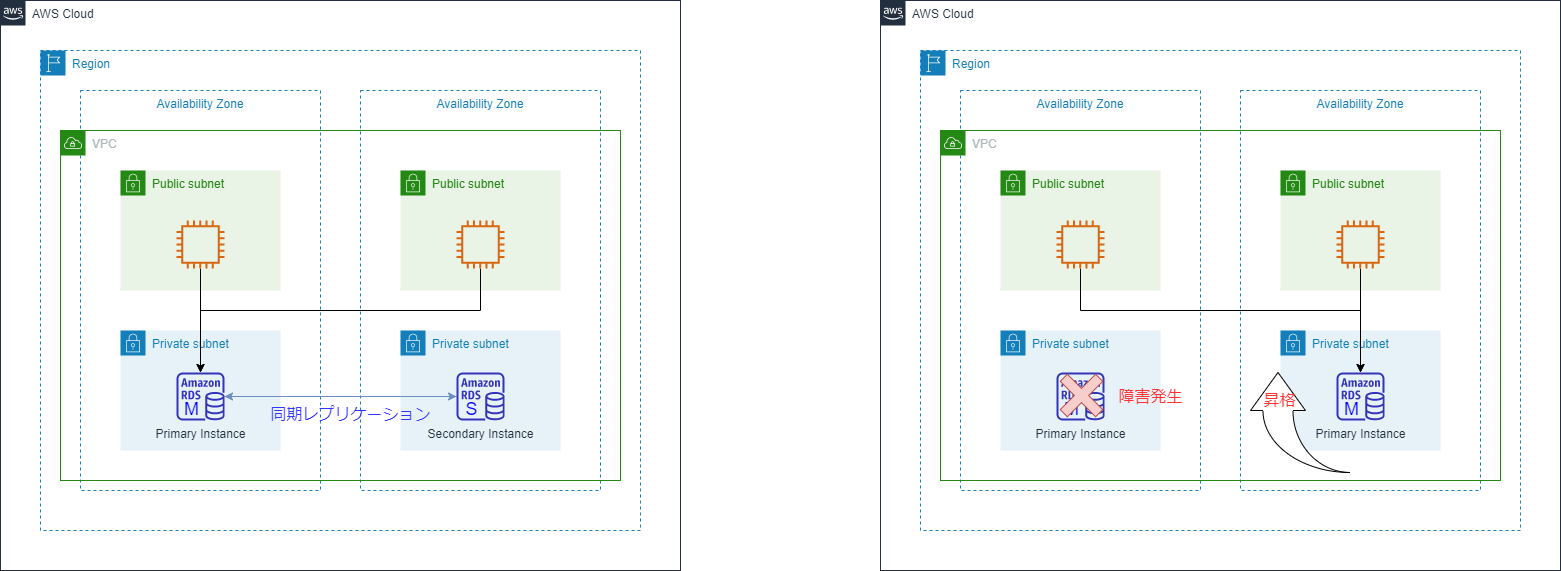
マルチ AZ 配置、マルチリージョン配置、およびリードレプリカが見やすくて好きです。
フォールトトレラントなワークロードを実装する (例: Amazon Elastic File System(Amazon EFS)、Elastic IP アドレス)。
Route 53 ルーティングポリシーを実装する
(例: フェールオーバー、加重、レイテンシーベース)。
2.3 バックアップ戦略および復元戦略を実装する。
用途に基づいてスナップショット作成処理およびバックアップ処理を自動化する (例: RDSスナップショット、AWS Backup、RTO/RPO、Amazon Data Lifecycle Manager、保持ポリシー)。
データベースを復元する
(例: 特定時点復元、リードレプリカの昇格)。
バージョニングルールおよびライフサイクルルールを実装する。
Amazon S3 のリージョン間レプリケーションを構成する。
ディザスタリカバリ手順を実行する。
分野 3: 展開、プロビジョニング、および自動化
3.1 クラウドリソースをプロビジョニングおよび保守する。
AMI を作成および管理する
(例: EC2 Image Builder)。
AWS CloudFormation の構成要素を作成、管理、およびトラブルシューティングする。
複数の AWS リージョンおよび AWS アカウントにまたがってリソースをプロビジョニングする
(例: AWS Resource Access Manager、CloudFormation StackSets、IAM クロスアカウントロール)。
展開シナリオおよび展開サービスを選択する
(例: ブルー/グリーン、ローリング、カナリア)。
展開に関する問題を特定および解決する
(例: サービスクオータ、サブネットのサイズ変更、CloudFormation エラー、AWS OpsWorks エラー、権限)。
3.2 手動プロセスまたは繰り返し実行されるプロセスを自動化する。
AWS サービスを使用して、展開プロセスを自動化する
(例: OpsWorks、Systems Manager、CloudFormation)。
修正プログラムの自動管理を実装する。
AWS サービスを使用して、自動化されたタスクをスケジューリングする
(例:EventBridge、AWS Config)。
分野 4: セキュリティおよびコンプライアンス
4.1 セキュリティポリシーおよびコンプライアンスポリシーを実装および管理する。
IAM 機能を実装する
(例: パスワードポリシー、MFA、ロール、SAML、フェデレーションID、リソースポリシー、ポリシー条件)。
AWS サービスを使用して、アクセスに関する問題をトラブルシューティングおよび監査する
(例: CloudTrail、IAM Access Analyzer、IAM Policy Simulator)。
サービスコントロールポリシーおよび権限境界の妥当性を検査する。
AWS Trusted Advisor セキュリティ検査の内容を確認する。
コンプライアンス要件に基づいて、選択した AWS リージョンおよびサービスの妥当性を検査する。
セキュアなマルチアカウント戦略を実装する (例: AWS Control Tower、AWSOrganizations)。
4.2 データ保護戦略およびインフラストラクチャ保護戦略を実装する。
データ分類スキームを適用する。
暗号化キーを作成、管理、および保護する。
格納データの暗号化を実装する
(例: AWS Key Management Service (AWS KMS))。
送信中データの暗号化を実装する
(例: AWS Certificate Manager、VPN)。
AWS サービスを使用して、シークレットをセキュアな方法で格納する
(例: AWS SecretsManager、Systems Manager、Parameter Store)。
レポートまたは調査結果の内容を確認する
(例: AWS Security Hub、Amazon GuardDuty、AWS Config、Amazon Inspector)。
分野 5: ネットワーキングおよびコンテンツ配信
5.1 ネットワーキング機能および接続を実装する。
VPC を構成する
(例: サブネット、ルーティングテーブル、ネットワーク ACL、セキュリティグループ、NAT ゲートウェイ、インターネットゲートウェイ)。
プライベート接続を構成する
(例: Systems Manager Session Manager、VPC エンドポイント、VPC ピアリング、VPN)。
AWS のネットワーク保護サービスを構成する
(例: AWS WAF、AWS Shield)
5.2 ドメイン、DNS サービス、およびコンテンツ配信を構成する。
Route 53 のホストゾーンおよびレコードを構成する。
Route 53 ルーティングポリシーを実装する
(例: 位置情報、地理的近接性)。
DNS を構成する
(例: Route 53 Resolver)。
Amazon CloudFront および S3 オリジンアクセスアイデンティティ (OAI) を構成する。
S3 静的 Web サイトホスティングを構成する。
5.3 ネットワーク接続問題をトラブルシューティングする。
VPC 構成を理解する
(例: サブネット、ルーティングテーブル、ネットワーク ACL、セキュリティグループ)。
ログを収集および解釈する
(例: VPC フローログ、Elastic Load Balancer アクセスログ、AWS WAF Web ACL ログ、CloudFront ログ)。
CloudFront のキャッシング問題を特定および解決する。
ハイブリッド接続問題およびプライベート接続問題をトラブルシューティングする。
分野 6: コストおよびパフォーマンスの最適化
6.1 コスト最適化戦略を実装する。
コスト配分タグを実装する。
AWS のサービスおよびツールを使用して、使用率の低いリソースや使用していないリソースを特定し、修正する
(例: Trusted Advisor、AWS Compute Optimizer、Cost Explorer)。
AWS Budgets および請求アラームを構成する。
リソース使用パターンを評価し、EC2 スポットインスタンスに適したワークロードを特定する。
マネージドサービスを使用する機会を特定する
(例: Amazon RDS、AWS Fargate、EFS)。
6.2 パフォーマンス最適化戦略を実装する。
パフォーマンスメトリクスに基づいてコンピュートリソースを提案する。
Amazon EBS メトリクスを監視し、パフォーマンス効率を高めるよう構成を修正する。
S3 のパフォーマンス機能を実装する (例: S3 Transfer Acceleration、マルチパートアップロード)。
RDS メトリクスを監視し、パフォーマンス効率を高めるよう構成を修正する
(例:Performance Insights、RDS Proxy)。
EC2 の拡張機能を有効化する
(例: 拡張ネットワークアダプタ、インスタンスストア、プレイスメントグループ)。
終わりに
少しずつ概要に解説足していきます。
試験ラボが、天国に導いてくれるのか、地獄へ引きずり込んでくるのか…
試験ガイドを見る限りですが、試験範囲はそこまで変わってないのかな~という印象です。