はじめに
本稿では筆者が現在取り組んでいる著書である「効果検証入門〜正しい比較のための因果推論/計量経済学の基礎」で取り扱われているデータを用いて、セレクションバイアスについて確認してみたいと思います.
以下の引用部分で必要であると言及されている"セレクションバイアスの理解"に取り組んでみたいと思います.
(実際のところ、単なる可視化ですので悪しからず...
計量経済学や因果推論は、このような理想的にはRCTでデータをデザインして分析したいがそれが不可能という状態において、RCTの結果を近似するような方法論を提供してくれます。しかしながら、計量経済学や因果推論の方法は、データを入力すると自動的に分析の結果を出してくれるわけではありません。分析者が対象となる事象の理解、特にセレクションバイアスの理解から分析を設計する必要があります。 安井 翔太. 効果検証入門〜正しい比較のための因果推論/計量経済学の基礎 (Japanese Edition) (p.69). Kindle 版.
勿論、時間をかければ私のような初学者でも理解できるのでしょうが、人手不足の世の中ですので直感的に理解できる方法が好ましいです.
"preattentive attributes"という概念があるようですから、直感的に、誰でも素早く理解できることはとりわけビジネスの現場で重要だと感じている人は少なくないのではないでしょうか.
Preattentive visual propertiesとは、視覚的な情報を処理する際に、無意識に処理される視覚的な特徴のことです。色、形、動き、空間的位置の4つの基本的な視覚的特性があります。これらの特性は、視覚的な注意が必要ではなく、無意識に処理されるため、「preattentive」と呼ばれます。これらの特性は、データの可視化において重要であり、データをより効果的に伝えるために使用されます。 (Bing)
前提条件
著書の設例で使用されているものと同じデータを使用させていただきました.
https://blog.minethatdata.com/2008/03/minethatdata-e-mail-analytics-and-data.html
上記リンク内で紹介されているデータは、キャンペーンメール送信の効果を検証するというものです.
メール送信の有無で消費額(spend)が有意に変化したかどうかを検証するものです.
キャンペーンメールの送信対象者はランダムに選ばれたことになっており、さらに平均の差のt検定の結果、帰無仮説は棄却されるため、販促施策の効果があったということが言えます.
Rを使用すると以下のような検定結果を得るようなイメージです.
rct_ttest
# Two Sample t-test
# data: mens_mail and no_mail
# t = 5.3001, df = 42611, p-value = 1.163e-07
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# 0.4851384 1.0545160
# sample estimates:
# mean of x mean of y
# 1.4226165 0.6527894
この検定に使用した元データを加工しキャンペーンメールに反応しそうな人に対してキャンペーンメールが送信される割合が多くなるような状況、つまりRCTが担保できず、検定したい対象についてバイアスのかかったデータを用意します.
すると、平均の差のt検定は以下のような結果になります.
rct_ttest_biased
# Two Sample t-test
# data: mens_mail_biased and no_mail_biased
# t = 5.6708, df = 31861, p-value = 1.433e-08
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# 0.6409145 1.3179784
# sample estimates:
# mean of x mean of y
# 1.5277526 0.5483062
実際に購入してくれそうな人の選び方については割愛しますが、現実世界では確度が高いと信じる層に対して販売施策を重点的に打ったり、その他の事情によって結果論としてRCTの要件が充足しないケースは多々あると思います.
売上に近いビジネスの現場では、そうした傾向は顕著で、インターネット上で購入までの動線が完結していない限り、RCTを担保できるケースは稀だと思います. 例えその販促メールの送信対象が本当にランダム選定されていたとしてもです.
何はともあれ、元データにバイアスがかかったので、平均値の差や検定結果が変化しました.
この設例では、RCTが担保された状態での検定を実施することが可能で、実際有意な差が検出されているため、バイアスがかかったデータを使用したことでより大きな有意差が検出されたということが言えます.
一方で、RCTの要件が充足された検定用の元データが入手できず、バイアスのかかったデータしか得られないとなると、検定結果をどう判断すれば良いのか、ということになるでしょう.
ひょっとすると世の中には無意味な平均値の差のt検定で溢れているのかもしれません.
メモ
さて、色々と調べているとEDAという概念があり、それ用のライブラリも用意されているようです.
EDAとは何なのかをBingに解説してもらいました.
探索的データ解析(EDA)とは、データ・サイエンティストがデータ・セットを分析および調査して、主な特性を要約するために使用する手法で、データ可視化の手法が活用されることが多くあります。EDAは、統計学における手法であり、データセットを解析してその主な特徴を要約するために使用されます。しばしば統計グラフィックスやその他のデータ可視化手法を使用します。EDAは、データの特徴を探求し、構造を理解することを目的としたデータサイエンスの最初の一歩とされています (Bing)
データサイエンティストのみならず、大学一般教養レベルの統計知識をお持ちであれば、広範な実務領域において用途があるものと理解しました.
恐らく時短のためなのでしょうが、pandas profilingやsweetvizなどといった便利なライブラリが存在するようです.
目下私の関心は、検定を行いたい2つのデータの特徴に差があるかどうかです.
sweetvizというライブラリを使ってそれを確かめてみましょう.
# 関連パッケージをインストールします
!pip install sweetviz
# 関連ライブラリをインポートします
import pandas as pd
import numpy as np
import sweetviz as sv
# 分析用のデータを読み込みます
filepath = "http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv"
df = pd.read_csv(filepath)
# separating the original data
# to controlled/treatment groups
# that are both biased
np.random.seed(1)
obs_rate_c = 0.5
obs_rate_t = 0.5
male_df = df[df['segment'] != 'Womens E-Mail']
male_df = male_df.assign(treatment = lambda x:
np.where(x['segment'] == 'Mens E-Mail', 1, 0))
biased_data = male_df.assign(obs_rate_c=np.where(
(male_df['history'] > 300)
| (male_df['recency'] < 6)
| (male_df['channel'] == "Multichannel"),
obs_rate_c,
1),
obs_rate_t=np.where(
(male_df['history'] > 300)
| (male_df['recency'] < 6)
| (male_df['channel'] == "Multichannel"),
1, obs_rate_t),
random_number=np.random.uniform(size=len(male_df)))
biased_data = biased_data.query(
"(treatment == 0 & random_number < obs_rate_c) "
"| (treatment == 1 & random_number < obs_rate_t)"
)
biased_mens_email = biased_data.query('treatment == 1')
biased_no_email = biased_data.query('treatment == 0')
# visualizing compared summary of features
# in both cotrolled and treatment data
# that are both biased
dataframe = biased_mens_email
compared = biased_no_email
report1 = sv.compare(dataframe, compared)
report1.show_html("sv_biased_data_comparison.html")
report1 = None
sweetviz以外の部分は、著書内のRのコードをBingチャットと相談して変換したものです.
pandasのDataFrameで利用可能なassign()やquery()は、その存在を知らなかったものの、Bingチャット曰く、良く使われるメソッドとのことでした.
また、元データにバイアスをかけるコードも私にとっては新鮮でした.
意図的にバイアスをかけることが今後あるのか?というところですが、初見ですととっつきにくい佇まいです.
さて、sweetvizがhtmlファイルでレポートを出力してくれたので確認していきたいと思います.
それぞれの特徴量について可視化してくれているので何個か眺めます.
はじめに、'recency'という特徴量についてです.
出典元による'recency'の説明は次のとおりです.
- Recency: Months since last purchase.
それではsweetvizによるレポートの一部を下図に示します.
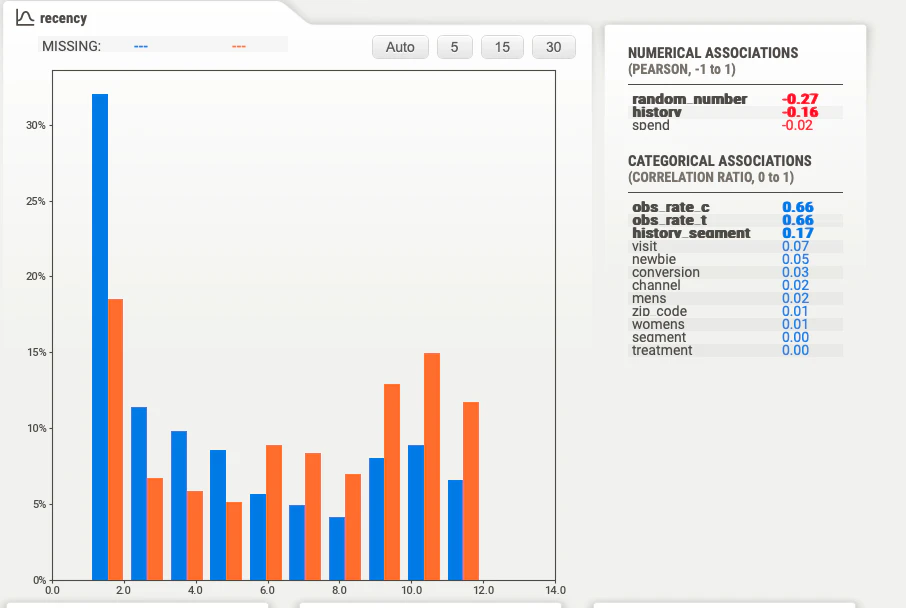
2つのヒストグラムが縦軸をパーセンテージとして表示されているようです.
販促メールが配信された先は青色、配信されていない先はオレンジ色です.
確かに、2グループの直近購入からの経過月数の顧客ごとの傾向に差がありそうです.
相対度数の考え方で表示されているので、介入群の方がより直近の購入履歴を持つことが一目で分かります.
なお、RCTの要件が充足された2群ではヒストグラムの形状は同一でした.
つまり、この時点でバイアスがかかっていることが確認できました.
平均の差を確かめたかった'spend'についてはどうでしょうか.
出典元による当該特徴量の説明は次のとおりです.
- Spend: Actual dollars spent in the following two weeks.
sweetvizによるレポートの一部を下図に示します.

こちらは購入金額0が多いためでしょうか、平均がいずれも1になっているなど、可視化としてはあまり良いとは言えないと感じました.
先ほどと同様の拡大グラフを確認してみましょう.
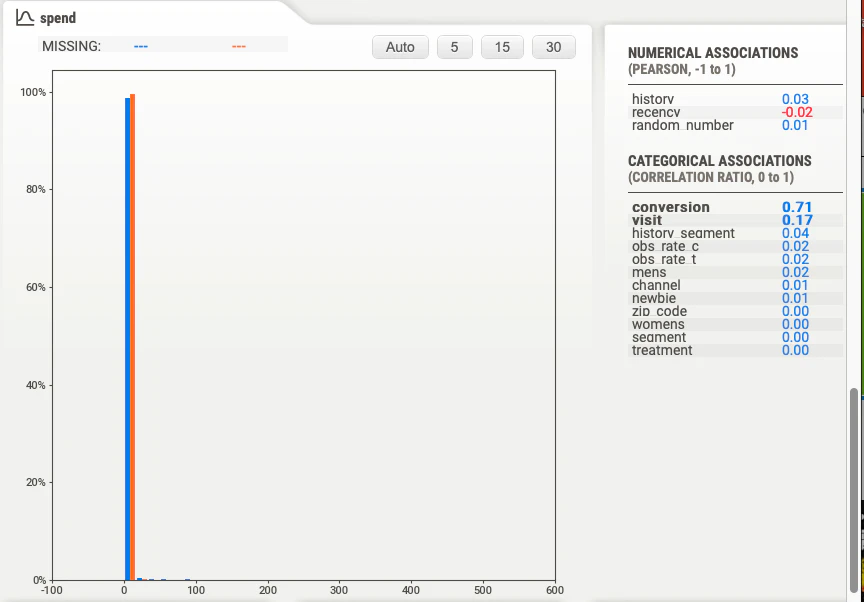
同様に、あまりイケテナイです.
まとめ
レポート出力時のオプション指定などがあるのでしょうが、現時点で次のような理解を得ました.
- 2群間の属性の違いを、収集済の特徴量ベースで確認したい場合、sweetvizのようなツールは時短になり便利
- ただし、特徴量の分布が極端な場合(例: 0が多い)は2群間の傾向の違いを判別しづらいケースがあった.
施策の効果検証の局面以外でも、2群間、多群間の傾向の違いをざっと確認したい場合は実務上多々あると思います.
(例えば、支店コードごとに傾向の違いを見るなど....
大抵の場合そんなに時間をかけていられないので、元データの特徴量を綺麗に可視化してくれるツールは非常に便利だと感じました.